AMD Radeon R9 285 Review: Feat. Sapphire R9 285 Dual-X OC
by Ryan Smith on September 10, 2014 2:00 PM ESTGCN 1.2 - Image & Video Processing
AMD’s final set of architectural improvements for GCN 1.2 are focused on image and video processing blocks contained within the GPU. These blocks, though not directly tied to GPU performance, are important to AMD by enabling new functionality and by offering new ways to offload tasks on to fixed function hardware for power saving purposes.
First and foremost then, with GCN 1.2 comes a new version of AMD’s video decode block, the Unified Video Decoder. It has now been some time since UVD has received a significant upgrade, as outside of the addition of VC-1/WMV9 support it has remained relatively unchanged for a couple of GPU generations.

With this newest generation of UVD, AMD is finally catching up to NVIDIA and Intel in H.264 decode capabilities. New to UVD is full support for 4K H.264 video, up to level 5.2 (4Kp60). AMD had previously intended to support 4K up to level 5.1 (4Kp30) on the previous version of UVD, but that never panned out and AMD ultimately disabled that feature. So as of GCN 1.2 hardware decoding of 4K is finally up and working, meaning AMD GPU equipped systems will no longer have to fall back to relatively expensive software decoding for 4K H.264 video.
On a performance basis this newest iteration of UVD is around 3x faster than the previous version. Using DXVA checker we benchmarked it as playing back a 1080p video at 331fps, or roughly 27x real-time. For 1080p decode it has enough processing power to decode multiple streams and then-some, but this kind of performance is necessary for the much higher requirements of 4K decoding.
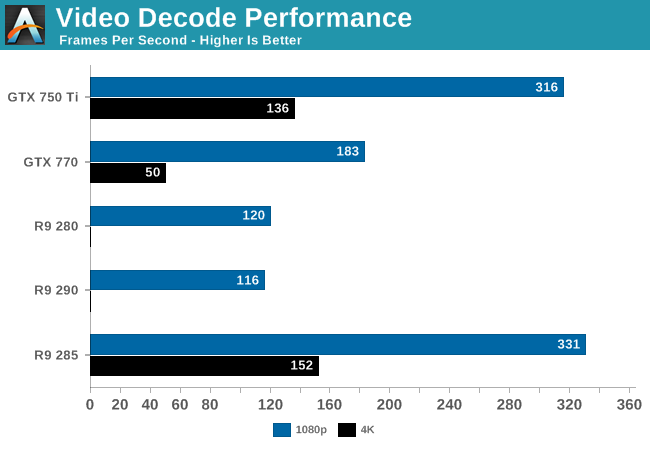
Speaking of which, we can confirm that 4K decoding is working like a charm. While Media Player Classic Home Cinema’s built-in decoder doesn’t know what to do for 4K on the new UVD, Windows’ built-in codec has no such trouble. Playing back a 4K video using that decoder hit 152fps, more than enough to play back a 4Kp60 video or two. For the moment this also gives AMD a leg-up over NVIDIA; while Kepler products can handle 4Kp30, their video decoders are too slow to sustain 4Kp60, which is something only Maxwell cards such as 750 Ti can currently do. So at least for the moment with R9 285’s competition being composed of Kepler cards, it’s the only enthusiast tier card capable of sustaining 4Kp60 decoding.
This new version of UVD also expands AMD’s supported codec set by 1 with the addition of hardware MJPEG decoding. AMD has previously implemented JPEG decoding for their APUs, so MJPEG is a natural extension of that. Though MJPEG is a fairly uncommon codec for most workloads these days, so outside of perhaps pro video I’m not sure how often this feature will get utilized.
What you won’t find though – and we’re surprised it’s not here – is support for H.265 decoding in any form. While we’re a bit too early for full fixed function H.265 decoders since the specification was only ratified relatively recently, both Intel and NVIDIA have opted to bridge the gap by implementing a hybrid decode mode that mixes software, GPU shader, and fixed function decoding steps. H.265 is still in its infancy, but given the increasingly long shelf lives of video cards, it’s a reasonable bet that Tonga cards will still be in significant use after H.265 takes off. But to give AMD some benefit of the doubt, since a hybrid mode is partially software anyhow, there’s admittedly nothing stopping them from implementing it in a future driver (NVIDIA having done just this for H.265 on Kepler).
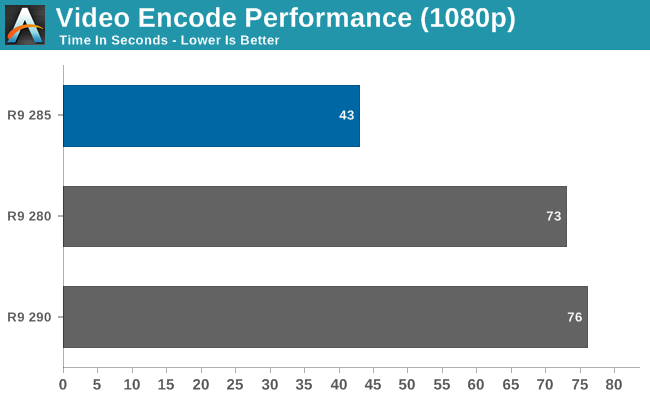
Moving on, along with their video decode capabilities, AMD has also improved on their video encode capabilities for GCN 1.2 with a new version of their Video Codec Engine. AMD’s hardware video encoder has received a speed boost to improve its encoding performance at all levels, and after previously being limited to a maximum resolution of 1080p can now encode at resolutions up to 4K. Meanwhile by AMD’s metrics this new version of VCE should be capable of encoding 1080p up to 12x over real time.
A quick performance check finds that while the current version of Cyberlink’s MediaEspresso software isn’t handling 4K video decoding quite right, encoding from a 1080p source shows that the new VCE is roughly 40% faster than the old VCE in our test.
4K video is still rather new, so there’s little to watch and even less of a reason to encode. That of course will change over time, but in the meantime the most promising use of a hardware 4K encoder would be 4K gameplay recording through the AMD Gaming Evolved Client’s DVR function.








86 Comments
View All Comments
Alexvrb - Tuesday, September 16, 2014 - link
"if other GCN 1.1 parts like Hawaii are any indication, it's much more likely the 280 maintains its boost clocks compared to the 285 (due to low TDP limits)"This is what you said. This is where I disagreed with you. The 285 maintains boost just as well as the 280. Further, GCN 1.1 Bonaire and even Hawaii reach and hold boost at stock TDP. The 290 series were not cooled sufficiently using reference coolers, but without any changes to TDP settings (I repeat, stock TDP) they boost fine as long as you cool them. GCN 1.1 boosts fine, end of story.
As far as Tonga goes, there's almost no progress in performance terms. In terms of power it depends on the OEM and I've seen good and bad. The only additions that really are interesting are the increased tessellation performance (though not terribly important at the moment) and finally getting TrueAudio into a mid-range part (it should be across the board by next gen I would hope - PS4 and XB1 have the same Tensilica DSPs).
I would hope they do substantially better with their future releases, or at least release a competent reference design that shows off power efficiency better than some of these third party designs.
chizow - Wednesday, September 17, 2014 - link
Yes, and my comment was correct, it will ALWAYS be "more likely" the 280 maintains its boost over other GCN 1.x parts because we know the track record of GCN 1.0 cards and their conservative Boost compared to post-PowerTune GCN1.x and later parts as a result of the black eye caused by Hawaii. There will always be a doubt due to AMD's less-than-honest approach to Boost with Hawaii, plain and simple.I also (correctly) qualified my statement by saying the low stated TDP of the 285 would be a hindrance to exceeding those rated specs and/or the performance of the 280, and we also see that is the case that in order to exceed those speed limits, AMD traded performance for efficiency to the point the 285's power consumption is actually closer to the 250W rated 280.
In any case, in another day or two, this unremarkable part is going to become irrelevant with GM104 Maxwell, no need to further waste any thoughts on it.
etherlore - Thursday, September 11, 2014 - link
Speculating here. The data parallel instructions could be a way to share data between SIMD lanes. I could see this functionality being similar in functionality to what threadgroup local store allows, but without explicit usage of the local store.It's possible this is an extension to, or makes new use of, the 32 LDS integer units in GCN. (section 2.3.2 in the souther islands instruction set docs)
vred - Thursday, September 11, 2014 - link
And... DP rate at last. Sucks to have it at 1/16 but at least now it's confirmed. First review where I see this data published.chizow - Thursday, September 11, 2014 - link
It has to be artificially imposed, as AMD has already announced FirePro cards based on the Tonga ASIC that do not suffer from this castrated DP rate. AMD as usual taking a page from Nvidia's playbook, so now all the AMD fans poo-poo'ing Nvidia's sound business decisions can give AMD equal treatment. Somehow I doubt that will happen though!Samus - Thursday, September 11, 2014 - link
If this is AMD's Radeon refresh, if the 750Ti tells us anything, they are screwed when Maxwell hits the streets next month.Atari2600 - Thursday, September 11, 2014 - link
The one thing missed in all this - APUs.As we all know, APUs are bandwidth starved. A 30-40% increase in memory subsystem efficiency will do very nicely for removing a major bottleneck.
That is before the move to stacked chips or eDRAM.
limitedaccess - Thursday, September 11, 2014 - link
@RyanRegarding the compression (delta color compression) changes for Tonga does this have any effect on the actual size of data stored in VRAM.
For instance if you take a 2gb Pitcarin card and a 2gb Tonga card showing the identical scene in a game will they both have identical (monitored) VRAM usage? Assuming of course the scenario here is neither is actually hitting the 2gb VRAM limit.
I'm wondering if it possible to test whether or not this is the case if unconfirmed.
Ryan Smith - Sunday, September 14, 2014 - link
VRAM usage will differ. Anything color compressed will take up less space (at whatever ratio the color compression algorithm allows). Of course this doesn't account for caching and programs generally taking up as much VRAM as they can, so it doesn't necessarily follow that overall VRAM usage will be lower on Tonga than Pitcairn. But it is something that can at least be tested.abundantcores - Thursday, September 11, 2014 - link
I see Anand still don't understand the purpose of Mantle, if they did they wouldn't be using the most powerful CPU they could find, i would explain it to them but i think its already been explained to them a thousand times and they still don't grasp it.Anand are a joke, they have no understanding of anything.