AMD Radeon R9 285 Review: Feat. Sapphire R9 285 Dual-X OC
by Ryan Smith on September 10, 2014 2:00 PM ESTGCN 1.2: Geometry Performance & Color Compression
Instruction sets aside, Radeon R9 285 is first and foremost a graphics and gaming product, so let’s talk about what GCN 1.2 brings to the table for those use cases.
Through successive generations of GPU architectures AMD has been iterating on and improving their geometry hardware, both at the base level and in the case of geometry generated through tessellation. This has alternated between widening the geometry frontends and optimizing the underlying hardware, with the most recent update coming in the GCN 1.1 based Hawaii, which increased AMD’s geometry processor count at the high end to 4 processors and implemented some buffering enhancements.
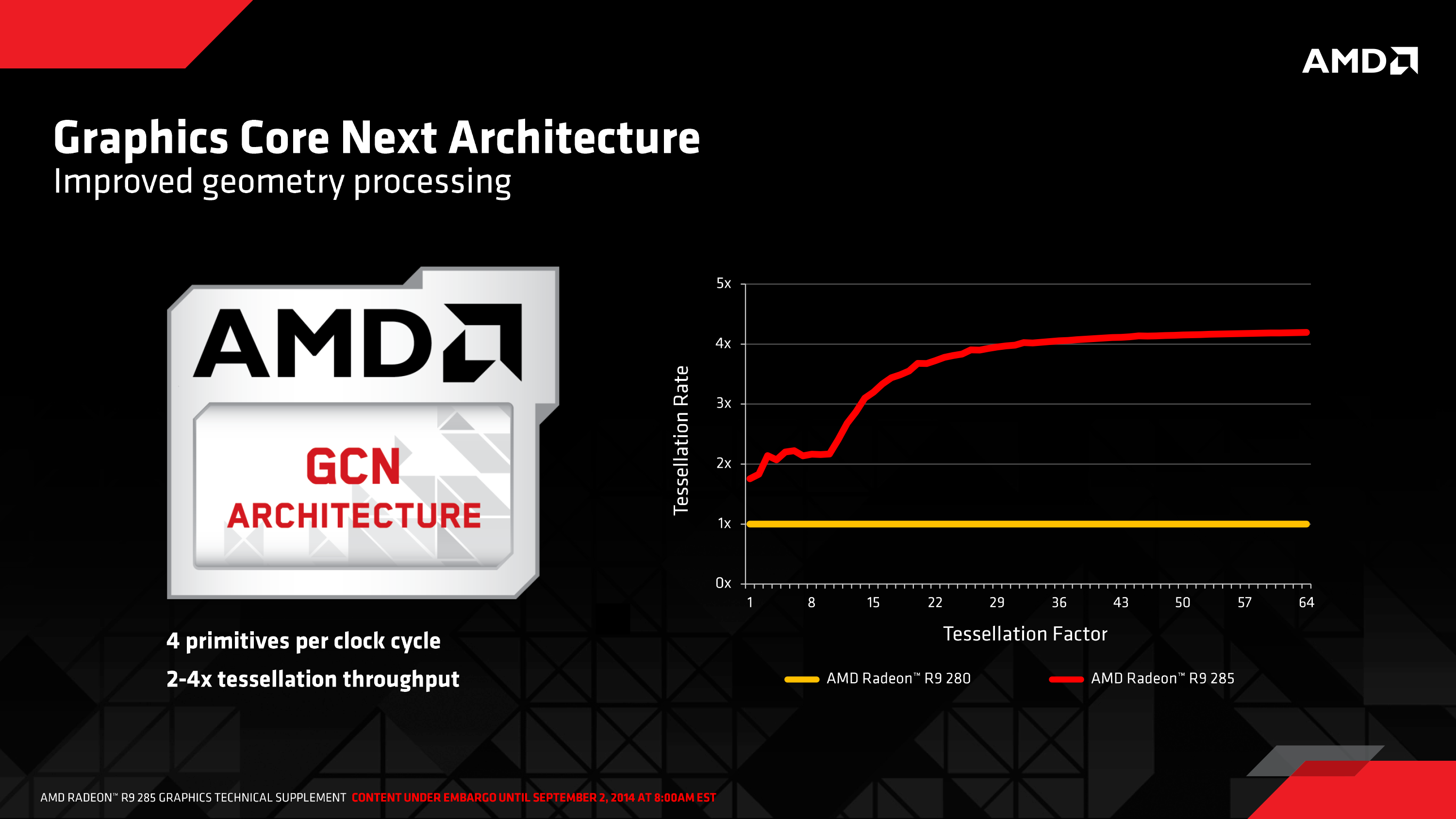

For Tonga AMD is bringing that 4-wide geometry frontend from Hawaii, which like Hawaii immediately doubles upon Tahiti’s 2-wide geometry frontend. Not stopping there however, AMD is also implementing a new round of optimizations to further improve performance. GCN 1.2’s geometry frontend includes improved vertex reuse (for better performance with small triangles) and improved work distribution between the geometry frontends to better allocate workloads between them.
At the highest level Hawaii and Tonga should be tied for geometry throughput at equivalent clockspeeds, or roughly 2x faster than Tahiti. However in practice due to these optimizations Tonga’s geometry frontend is actually faster than Hawaii’s in at least some cases, as our testing has discovered.
Comparing the R9 290 (Hawaii), R9 285 (Tonga), and R9 280 (Tahiti) in TessMark at various tessellation factors, we have found that while Tonga trails Hawaii at low tessellation factors – and oddly enough even Tahiti – at high tessellation factors the tables are turned. With x32 and x64 tessellation, the Tonga based R9 285 outperforms both cards in this raw tessellation test, and at x64 in particular completely blows away Hawaii, coming close to doubling its tessellation performance.

At the x64 tessellation factor we see the R9 285 spit out 134fps, or equivalent to roughly 1.47B polygons/second. This is as compared to 79fps (869M Polys/sec) for the R9 290, and 68fps (748M Polys/sec) for the R9 280. One of the things we noted when initially reviewing the R9 290 series was that AMD’s tessellation performance didn’t pick up much in our standard tessellation benchmark (Tessmark at x64) despite the doubling of geometry processors, and it looks like AMD has finally resolved that with GCN 1.2’s efficiency improvements. As this is a test with a ton of small triangles, it looks like we’ve hit a great case for the vertex reuse optimizations.
Meanwhile AMD’s other GCN 1.2 graphics-centric optimization comes at the opposite end of the rendering pipeline, where the ROPs and memory controllers lie. As we mentioned towards the start of this article, one of the notable changes between the R9 280 and R9 285 is that the latter utilizes a smaller 256-bit memory bus versus the R9 280’s larger 384-bit memory bus, and as a result has around 27% less memory bandwidth than the R9 280. Under most circumstances such a substantial loss in memory bandwidth would result in a significant performance hit, so for AMD to succeed Tahiti with a smaller memory bus, they needed a way to be able to offset that performance loss.

The end result is that GCN 1.2 introduces a new color compression method for its ROPs, to reduce the amount of memory bandwidth required for frame buffer operations. Color compression itself is relatively old – AMD has had color compression in some form for almost 10 years now – however GCN 1.2 iterates on this idea with a color compression method AMD is calling “lossless delta color compression.”
Since AMD is only meeting us half-way here we don’t know much more about what this does. Though the fact that they’re calling it delta compression implies that AMD has implemented a further layer of compression that works off of the changes (deltas) in frame buffers, on top of the discrete compression of the framebuffer. In this case this would not be unlike modern video compression codecs, which between keyframes will encode just the differences to reduce bandwidth requirements (though in AMD’s case in a lossless manner).
AMD’s own metrics call for a 40% gain in memory bandwidth efficiency, and if that is the average case it would more than make up for the loss of memory bandwidth from working on a narrower memory bus. We’ll see how this plays out over our individual games over the coming pages, but it’s worth noting that even our most memory bandwidth-sensitive games hold up well compared to the R9 280, never losing anywhere near the amount of performance that such a memory bandwidth reduction would imply (if they lose performance at all).








86 Comments
View All Comments
Alexvrb - Tuesday, September 16, 2014 - link
"if other GCN 1.1 parts like Hawaii are any indication, it's much more likely the 280 maintains its boost clocks compared to the 285 (due to low TDP limits)"This is what you said. This is where I disagreed with you. The 285 maintains boost just as well as the 280. Further, GCN 1.1 Bonaire and even Hawaii reach and hold boost at stock TDP. The 290 series were not cooled sufficiently using reference coolers, but without any changes to TDP settings (I repeat, stock TDP) they boost fine as long as you cool them. GCN 1.1 boosts fine, end of story.
As far as Tonga goes, there's almost no progress in performance terms. In terms of power it depends on the OEM and I've seen good and bad. The only additions that really are interesting are the increased tessellation performance (though not terribly important at the moment) and finally getting TrueAudio into a mid-range part (it should be across the board by next gen I would hope - PS4 and XB1 have the same Tensilica DSPs).
I would hope they do substantially better with their future releases, or at least release a competent reference design that shows off power efficiency better than some of these third party designs.
chizow - Wednesday, September 17, 2014 - link
Yes, and my comment was correct, it will ALWAYS be "more likely" the 280 maintains its boost over other GCN 1.x parts because we know the track record of GCN 1.0 cards and their conservative Boost compared to post-PowerTune GCN1.x and later parts as a result of the black eye caused by Hawaii. There will always be a doubt due to AMD's less-than-honest approach to Boost with Hawaii, plain and simple.I also (correctly) qualified my statement by saying the low stated TDP of the 285 would be a hindrance to exceeding those rated specs and/or the performance of the 280, and we also see that is the case that in order to exceed those speed limits, AMD traded performance for efficiency to the point the 285's power consumption is actually closer to the 250W rated 280.
In any case, in another day or two, this unremarkable part is going to become irrelevant with GM104 Maxwell, no need to further waste any thoughts on it.
etherlore - Thursday, September 11, 2014 - link
Speculating here. The data parallel instructions could be a way to share data between SIMD lanes. I could see this functionality being similar in functionality to what threadgroup local store allows, but without explicit usage of the local store.It's possible this is an extension to, or makes new use of, the 32 LDS integer units in GCN. (section 2.3.2 in the souther islands instruction set docs)
vred - Thursday, September 11, 2014 - link
And... DP rate at last. Sucks to have it at 1/16 but at least now it's confirmed. First review where I see this data published.chizow - Thursday, September 11, 2014 - link
It has to be artificially imposed, as AMD has already announced FirePro cards based on the Tonga ASIC that do not suffer from this castrated DP rate. AMD as usual taking a page from Nvidia's playbook, so now all the AMD fans poo-poo'ing Nvidia's sound business decisions can give AMD equal treatment. Somehow I doubt that will happen though!Samus - Thursday, September 11, 2014 - link
If this is AMD's Radeon refresh, if the 750Ti tells us anything, they are screwed when Maxwell hits the streets next month.Atari2600 - Thursday, September 11, 2014 - link
The one thing missed in all this - APUs.As we all know, APUs are bandwidth starved. A 30-40% increase in memory subsystem efficiency will do very nicely for removing a major bottleneck.
That is before the move to stacked chips or eDRAM.
limitedaccess - Thursday, September 11, 2014 - link
@RyanRegarding the compression (delta color compression) changes for Tonga does this have any effect on the actual size of data stored in VRAM.
For instance if you take a 2gb Pitcarin card and a 2gb Tonga card showing the identical scene in a game will they both have identical (monitored) VRAM usage? Assuming of course the scenario here is neither is actually hitting the 2gb VRAM limit.
I'm wondering if it possible to test whether or not this is the case if unconfirmed.
Ryan Smith - Sunday, September 14, 2014 - link
VRAM usage will differ. Anything color compressed will take up less space (at whatever ratio the color compression algorithm allows). Of course this doesn't account for caching and programs generally taking up as much VRAM as they can, so it doesn't necessarily follow that overall VRAM usage will be lower on Tonga than Pitcairn. But it is something that can at least be tested.abundantcores - Thursday, September 11, 2014 - link
I see Anand still don't understand the purpose of Mantle, if they did they wouldn't be using the most powerful CPU they could find, i would explain it to them but i think its already been explained to them a thousand times and they still don't grasp it.Anand are a joke, they have no understanding of anything.