Intel Xeon E5 Version 3: Up to 18 Haswell EP Cores
by Johan De Gelas on September 8, 2014 12:30 PM ESTOpenFoam
Computational Fluid Dynamics is a very important part of the HPC world. Several readers told us that we should look into OpenFoam, and my lab was able to work with the professionals of Actiflow. Actiflow specializes in combining aerodynamics and product design. Calculating aerodynamics involves the use of CFD software, and Actiflow uses OpenFoam to accomplish this. To give you an idea what these skilled engineers can do, they worked with Ferrari to improve the underbody airflow of the Ferrari 599 and increase its downforce.
We were allowed to use one of their test cases as a benchmark, but we are not allowed to discuss the specific solver. All tests were done on OpenFoam 2.2.1 and openmpi-1.6.3.
Many CFD calculations do not scale well on clusters, unless you use InfiniBand. InfiniBand switches are quite expensive and even then there are limits to scaling. We do not have an InfiniBand switch in the lab, unfortunately. Although it's not as low latency as InfiniBand, we do have a good 10G Ethernet infrastructure, which performs rather well. So we can compare our newest Xeon server with a basic cluster.
We also found AVX code inside OpenFoam 2.2.1, so we assume that this is one of the cases where AVX improves FP performance. To understand this real world test case better, we'll start with a single-threaded benchmark.
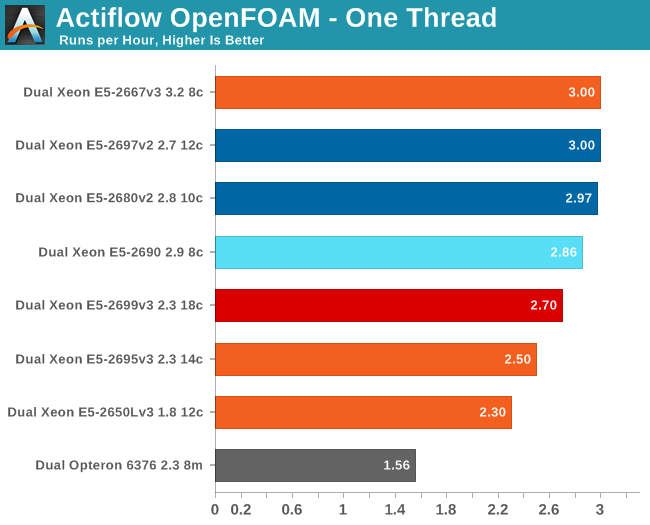
As this is AVX code, the clock speed "rules" change. A 2.3GHz Xeon E5 v3 can fall back to 1.9GHz if necessary, but it may also boost to 3.3GHz if the thermals allow it. The Xeon 2695 v3 has less TDP headroom and as a result it performs slightly slower than the Xeon E5-2699 v3. Still they cannot beat the Xeon E5-2667 v3 in single-threaded HPC performance. The latter is the better chip for this workload as it guarantees 2.7GHz and can boost up to 3.5GHz. As the previous Xeons also support AVX and run between 2.7 and 3.3GHz, they keep up with the Xeon E5-2667 v3.
Of course, most HPC code is now multi-threaded. We next ran OpenFOAM at one thread per physical core, which is about 5% faster than running with one thread per logical core (likely due to AVX).
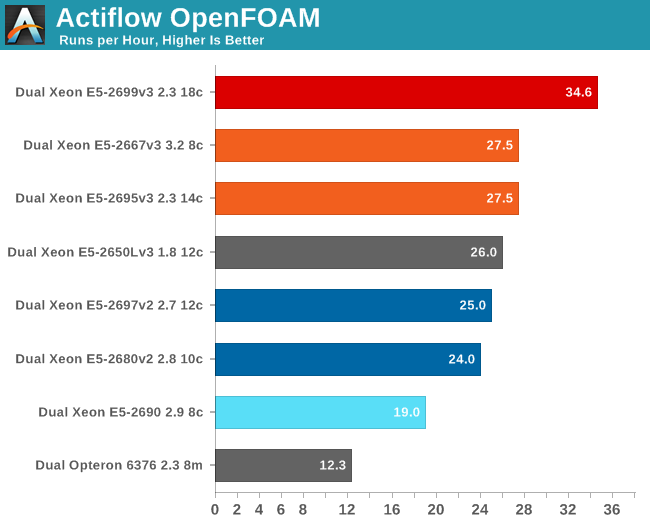
If you work professionally with OpenFOAM, it is clear that it pays off to understand what a certain CPU offers. If money does not matter much, the Xeon E5-2699 v3 does what is has to, which is to beat everybody else despite the fact that OpenFOAM does not scale that well beyond a certain point.
To give you an idea of what we're seeing, with 16 threads on the Xeon E5-2699 v3 we were already running at 30 runs per hour. Despite the fact that our workload is already a pretty heavy one (>600k cells), it is clear you need a larger mesh to really use the best Xeons of today to their full potential.
A less expensive option is the Xeon E5-2667 v3, but the real winner here is the Xeon E5-2650L v3 which costs a full $1000 per CPU les than the Xeon E5-2695 v3 and consumes quite a bit less as we will see on the next page.








85 Comments
View All Comments
shodanshok - Tuesday, September 16, 2014 - link
Hi,Please note that the RWT article you are endlessy posting is 10 (TEN!) years ago.
SGI tell the extact contrary of what you reports:
https://www.sgi.com/pdfs/4227.pdf
Altrix UV systems are shared memory system connecting the various boards (4-8 sockets per board) via QPI and NUMAlink. They basically are a distribuited version of your beloved scale-up server. After all, maximum memory limit is 16 TB, which is the address space _a single xeon_ can address.
I am NOT saying that commodity X86 hardware can replace proprietary, big boxes in every environment. What I am saying it that the market nice for bix unix boxes is rapidly shrinking.
So, to recap:
1) in an article about Xeon E5 (4000$ max) you talk about the the mighty M7 (which are NOT available) with will probably cost 10-20X (and even T4/T5 are 3-5X);
2) you speak about SPECInt2006 conveniently skipping about anything other that throughput, totalling ignoring latency and per-thread perf (and event in pure throughput Xeons are very competitive at a fraction of the costs)
3) you totally ignore the fact that QPI and NUMAlink enable multi-board system to act as a single one, running a single kernel image within a shared memory environment.
Don't let me wrong: I am not an Intel fan, but I must say I'm impressed with the Xeons it is releasing since 4 years (from Nehalem EX). Even their (small) Itanium niche is at risk, attacked by higher end E7 systems.
Maybe (and hopefully) Power8 and M7 will be earth-shattering, but they will surely cost much, much more...
Regards.
Brutalizer - Friday, September 19, 2014 - link
This is folly. The link I post where SGI says their "Altix" server is only for HPC clustered workloads, applies also today to the "Altix" successor: the "Altix UV". Fact is that no large Unix or Mainframe vendor has successfully scaled beyond 32/64 sockets. And now SGI, a small cluster vendor with tiny resources, claims to have 256 socket server, with tiny resources compared to the large Unix companies?? Has SGI succeeded where no one else has, pouring decades and billions of R&D?As a response you post a link where SGI talks about their "Altix UV", and you claim that link as a evidence that the Altix UV server is not a cluster. Well, if you bothered to read your link, you would see that SGI has not change their viewpoint: it is only for HPC clustered workloads. For instance, "Altix UV" talks about MPI. MPI is only used in clusters, mainly for number crunching. I have worked with MPI in scientific computations, so I know this. No one would use MPI in a SMP server, such as the Oracle M7. Anyone talking about MPI, is also talking about clusters. For instance, enterprise software such as SAP does not use MPI.
As a coup de grace, I quote text from your link about the latest "Altix UV" server:
"...The key enabling feature of SGI Altix UV is the NUMAlink 5 interconnect, with additional performance characteristics contributed by the on-node hub and its MPI Offload Engine (MOE)...MOE is designed to take MPI process communications off the microprocessors, thereby reducing CPU overhead and lowering memory access latency, and thus improving MPI application performance and scalability. MOE allows MPI tasks to be handled in the hub, freeing the processor for computation. This highly desirable concept is being pursued by various switch providers in the HPC cluster arena;
...
But fundamentally, HPC is about what the user can achieve, and it is this holy quest that SGI has always strived to enable with its architectures..."
Maybe this is the reason you will not find SAP benchmarks on the largest "Altix UV" server? Because it is a cluster.
But of course, you are free to disprove me by posting SAP benchmarks on a large Linux server with 10.000s of cores (i.e. clusters). I agree that if that SGI cluster runs SAP faster than a SMP 32-socket server - then it does not matter if SGI is cluster or not. The point is; clusters can not run all workloads, they suck at Enterprise workloads. If they can run Enterprise workloads, then I change my mind. Because, in the end, it does not matter how the hardware is constructed, as long as it can run SAP fast enough. But clusters can not.
Post SAP benchmarks on a large Linux server. Go ahead. Prove me wrong when you say they are not clusters - in that case they would be able to handle non clustered workloads such as SAP. :)
shodanshok - Friday, September 19, 2014 - link
Brutalizer, I am NOT (NOT!!!) saying that x86 is the best-of-world in scale-up performance. After all, it remain commodity hardware, and some choices clearly reflect that. For example, while Intel put single-image systems at as much as 256 sockets, the latency induced by the switchs/interconnect surely put the real number way lower.What I am saying in that the market that truly need big Unix boxes is rapidly shrinking, so your comment about how "mediocre" is this new 18-core monster are totally off place.
Please note that:
1) Altrix UV are SHARED MEMORY systems built out of clusters, where the "secret sauce" is the added tech behind NUMAlink. Will SAP run well on these systems? I think no: the NUMAlinks add too much latency. However, this same tech can be used in a number of cases where big unix boxes where the first choice (at least in SGI words, I don't have a similar system (unfortunately!) so I can't tell more;
2) HP has just released the SAP HANA benchmarks for 16 sockets Intel E7 in scale-up configuration (read: single system) and 12/16 TB of RAM
LINK1 :http://h30507.www3.hp.com/t5/Converged-Infrastruct...
LINK2: http://h30507.www3.hp.com/t5/Reality-Check-Server-...
LINK3: http://h20195.www2.hp.com/V2/GetPDF.aspx%2F4AA5-14...
3) Even at 8 sockets, the Intel systems are very competitive. Please read here for some benchmarks: http://www.anandtech.com/show/7757/quad-ivy-brigde...
Long story short: an 8S Intel E7-8890 (15 cores @ 2.8 GHz) beat an 8S Oracle T5-8 (16 cores @ 3.6 GHz) by a significant margin. Now think about 18 Haswell cores...
4) On top of that, event high-end E7 Intel x86 systems are way cheaper that Oracle/IBM box, while providing similar performances. The real differentation are the extreme RAS features integrated into proprietary unix boxes (eg: lockstep) that require custom, complex glue logic on x86. And yes, some unix boxes have impressive amount of memory ;)
5) This article speak about *Haswell-EP*. They are one (sometime even two...) order of magnitude cheaper that proprietary unix boxes. So, why on earth in each Xeon article you complain about how mediocre is that technology?
Regards.
Brutalizer - Monday, September 22, 2014 - link
I hear you when you say that x86 has not the best scaleup performance. I am only saying that those 256-socket x86 servers you talk of, are in practice, nothing more than a cluster. Because they are only used for clustered HPC workloads. They will never run Enterprise business software as a large SMP server with 32/64 sockets - that domain are exclusive to Unix/Mainframe servers.It seems that we disagree on the 256-socket x86 servers, but agree on everything else (x86 are cheaper than RISC, etc). I claim they can only be used as clusters (you will only find HPC cluster benchmarks). So, those large Linux servers with 10.000 cores such as SGI Altix UV, are actually only usable as clusters.
Regarding HP SAP HANA benchmarks with the 16-socket x86 server called ConvergedSystem 9000; it is actually a Unix Superdome server (a RISC server) where HP swapped all Itanium cpus to x86 cpus. Well, it is good that there are soon 16-sockets Linux servers available on the market. But HANA is a clustered database. I would like to see the HP ConvergedSystem server running non clustered Enterprise workloads - how well would the first 16-socket Linux server perform? We have to see. And then we can compare the fresh Linux 16-socket server to the mature 32/64-socket Unix/Mainframe servers in benchmarks and see which is fastest. A clustered Linux 256-socket server sucks on SMP benchmarks, it would be useless.
Brutalizer - Monday, September 22, 2014 - link
http://www.enterprisetech.com/2014/06/02/hps-first..."...The first of several systems that will bring technologies from Hewlett-Packard’s Superdome Itanium-based machines to big memory ProLiant servers based on Xeon processors is making its debut this week at SAP’s annual customer shindig.
Code-named “Project Kraken,” the system is commercialized as the ConvergedSystem 900 for SAP HANA and as such has been tuned and certified to run the latest HANA in-memory database and runtime environment. The machine, part of a series of high-end shared memory systems collected known as “DragonHawk,” is part of a broader effort by HP to create Superdome-class machines out of Intel’s Xeon processors.
...
The obvious question, with SAP allowing for HANA nodes to be clustered, is: Why bother with a big NUMA setup instead of a cluster? “If you look at HANA, it is really targeting three different workloads,” explains Miller. “You need low latency for transactions, and in fact, you can’t get that over a cluster...."
TiGr1982 - Tuesday, September 9, 2014 - link
Our RISC scale-up evengelist is back!That's OK and very nice, nobody argues, but I guess one has to win a serious jackpot to afford one of these 32 socket Oracle SPARC M7-based machines :)
Jokes aside, technically, you are correct, but Xeon E5 is obviously not about the very best scale-up on the planet, because Intel is aiming more at a mainstream server market. So, Xeon E5 line resides in a totally different price range than your beasty 32 socket scale-up, so what's the point of writing about SPARC M7 here?
TiGr1982 - Tuesday, September 9, 2014 - link
Talking Intel, even Xeon E7 is much lower class line in terms of total firepower (CPU and RAM capability) than your beloved 32 socket SPARC Mx, and even Xeon E7 is much cheaper, than your Mx-32, so, again, what's the point of posting this in the article about E5?Brutalizer - Wednesday, September 10, 2014 - link
The point is, people believes that building a huge SMP server with as many as 32-sockets is easy. Just add a few of Xeon E5 and you are good to go. That is wrong. It is exponentially more difficult to build a SMP server than a cluster. So, no one has ever sold such a huge Linux server with 32-sockets. (IBM P795 is a Unix server that people tried to compile Linux for, but it is not Linux server, it is a RISC AIX server)TiGr1982 - Wednesday, September 10, 2014 - link
Well, I comprehend and understand your message, and I agree with you. Huge SMP scale-up servers are really hard to build, mostly because of the dramatically increasing complexity of the problem to implement the REALLY fast (both in terms of bandwidth and latency) interconnect between sockets in case when socket count grows considerably (say, up to 32), which is really required in order to get the true SMP machine.I hope, other people get your message too.
BTW, I remember you already posted this kind of statements in the Xeon E7 v2 article comments before :-)
Brutalizer - Monday, September 15, 2014 - link
"...I hope, other people get your message too...."Unfortunately, they dont. See "shodanshok" reply above, that the 256 socket xeon servers are not clusters. And see my reply, why they are.