Intel Broadwell Architecture Preview: A Glimpse into Core M
by Ryan Smith on August 11, 2014 12:01 PM ESTPutting It All Together: Low Power Core M
So far we’ve discussed Broadwell’s architecture on a broad basis, focusing on features and optimizations that are fundamental to the architecture. However to talk about the Broadwell architecture is not enough to fully explain the Core M itself. Though many of Core M’s improvements do come from Broadwell, Intel has also made a number of alterations to everything from the CPU packaging to the process node itself specifically for Core M. It’s the resulting combination of these factors that has allowed Intel to iterate on Broadwell-Y over Haswell-Y, and why Intel is so confident in Broadwell-Y’s capabilities and suitability for mobile form factors.
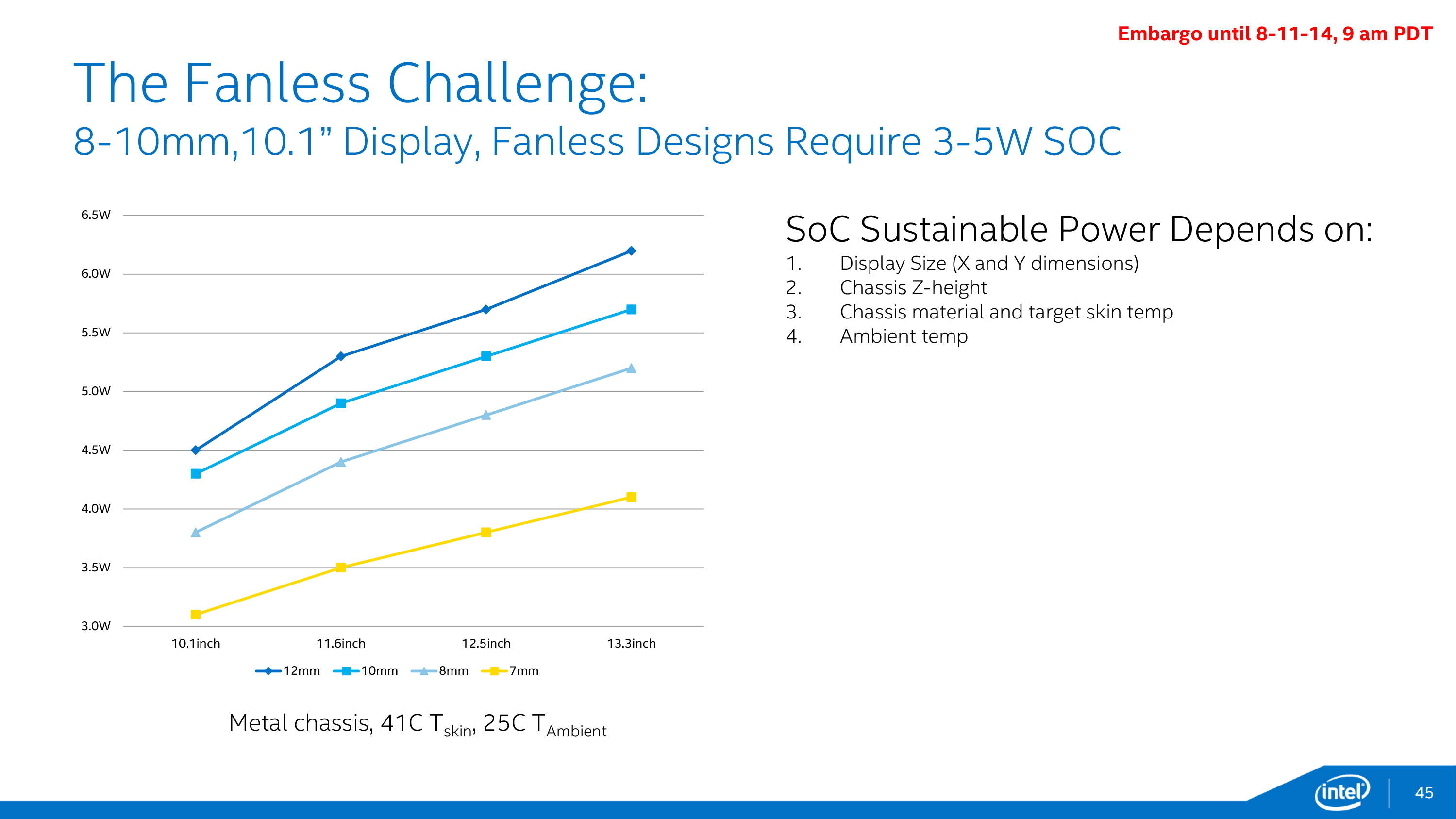
When it comes to building and configuring Core M, Intel likes to refer to their efforts as the “Fanless Challenge,” reflecting the fact that their biggest goal with Core M is to comfortably get the processor in to 10” tablets under 10mm in thickness that are passively cooled. A big part of getting into such a device is meeting the heat dissipation limitations of the form factor – a 10” tablet under 10mm would require a sub-5W SoC – which is where a lot of Intel’s engineering efforts have gone. Broadwell’s performance optimizations, the GPU optimizations, GPU duty cycling, and the 14nm process all contribute to getting a Core CPU’s power consumption down to that level.
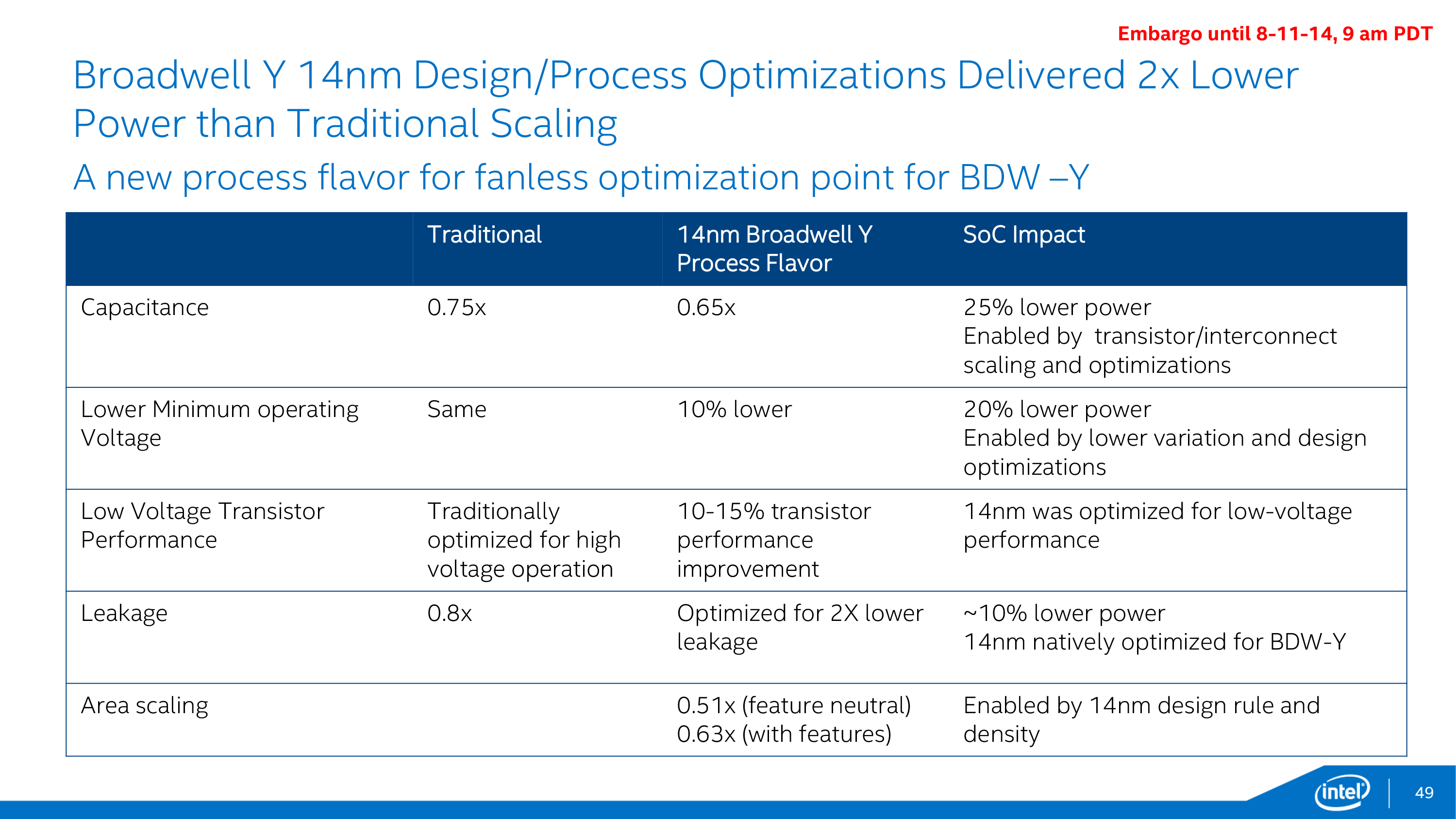
But even that’s still not enough, and for Core M Intel went so far as to give Broadwell-Y its own die and design a low-power optimized version of their 14nm process just for it. This variant is designed to further reduce power consumption by optimizing the resulting transistors for lower power, lower voltage, lower clockspeed operation. By doing this Intel was able to further reduce power consumption in all of the major areas over what would be a traditional 14nm Intel process.
In the resulting 14nm Broadwell-Y process, voltage, capacitance, and leakage were all improved over the traditional 14nm process. Capacitance was reduced by 15%, minimum operating voltages by 10%, and leakage was improved to the point that it reduced SoC power consumption by 10%. The combination of all of these factors serves to significantly lower power consumption over what Intel’s traditional 14nm process would provide.
Working in concert with Broadwell-Y’s 14nm process, Intel has made a number of other changes to further reduce power consumption. Some of these are reflected in Broadwell’s overall design and others are unique to Broadwell-Y, such as using a lower TjMax for Broadwell-Y. By reducing the maximum operating temperature of the chip Intel has been able to realize further power savings by further reducing voltage and decreasing the maximum amount of temperature-dependent leakage the SoC will experience.

Meanwhile Broadwell-Y’s partner in crime, the on-package PCH, has received its own optimizations to reduce power consumption on the SoC’s total power consumption. The PCH itself is not much of a power hog in the first place – it’s still made on Intel’s 32nm process for this and cost reasons – but with such a strong focus on power consumption every watt ends up counting. As a result the Broadwell PCH-LP has seen optimizations that cut its idle power consumption by 25% and its active power consumption by 20%. Further improvements to the PCH’s monitoring hardware also mean it’s more responsive and can be controlled to a finer degree than the Haswell PCH-LP, and Intel has upgraded to a faster audio DSP to improve performance and reduce power consumption there as well.

Feeding all of that silicon in turn is Intel’s second generation Fully Integrated Voltage Regulator (FIVR), which further builds off of Intel’s other optimizations. The 2nd gen FIVR has been tuned for Broadwell-Y’s lower voltages, making the FIVR itself more efficient when delivering power at those voltages. To accomplish this Intel has implemented non-linear vDroop control, which is designed to better control the voltage when workload changes would cause voltage overshoots that waste power. And when even the 2nd gen FIVR isn’t efficient enough, this latest FIVR offers a second mode (LVR Mode) for low voltage/workload situations where the FIVR can be partially bypassed to reduce the FIVR’s power consumption.
Interestingly Broadwell-Y also sees the voltage regulation inductors redesigned and relocated in both the name of power efficiency and space efficiency. We’ll get to the case of space efficiency in a moment, but for power efficiency the new 3D inductors (3DLs) have been placed on the underside of the package, allowing the use of more efficient inductors that waste less power.
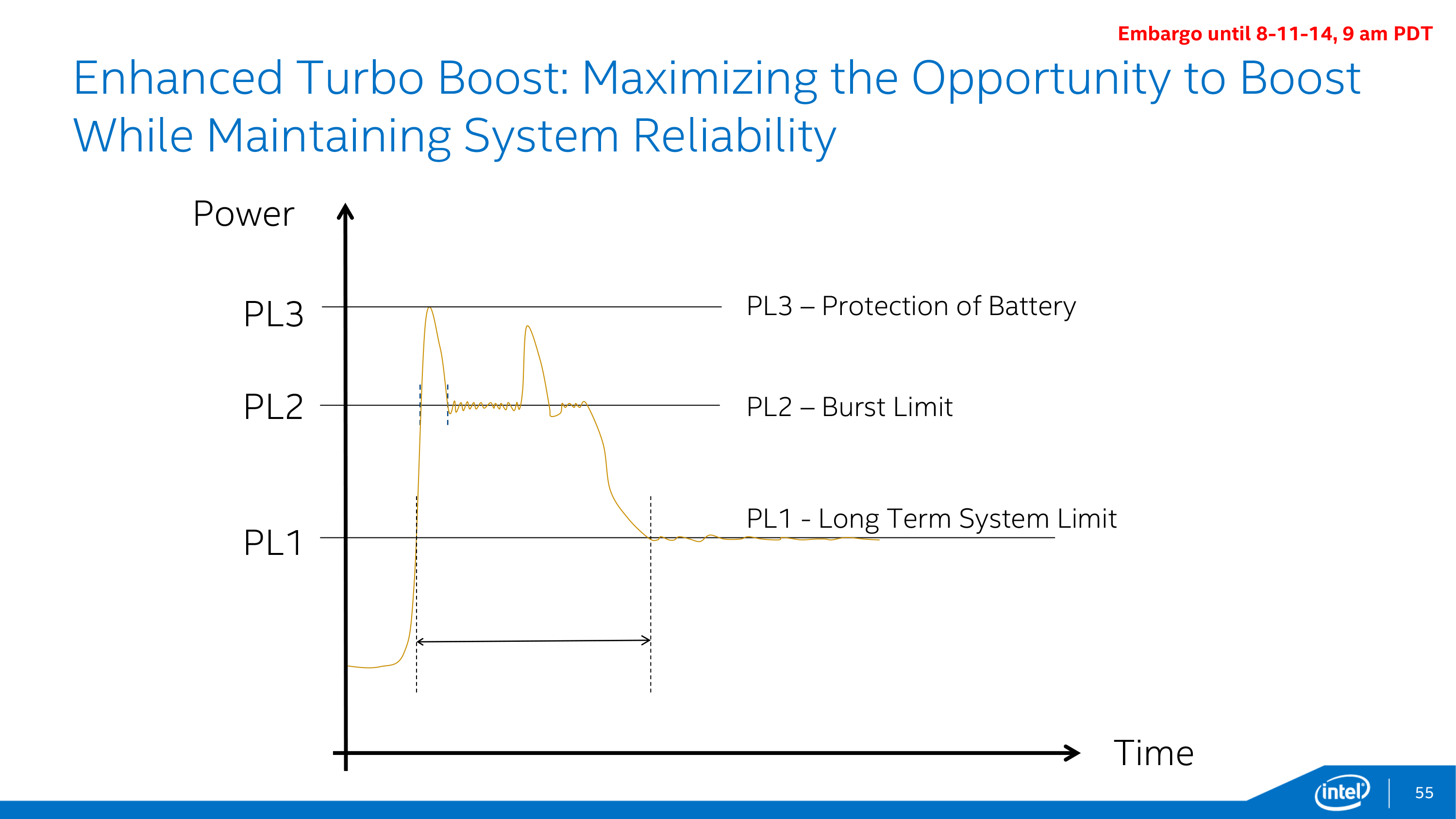
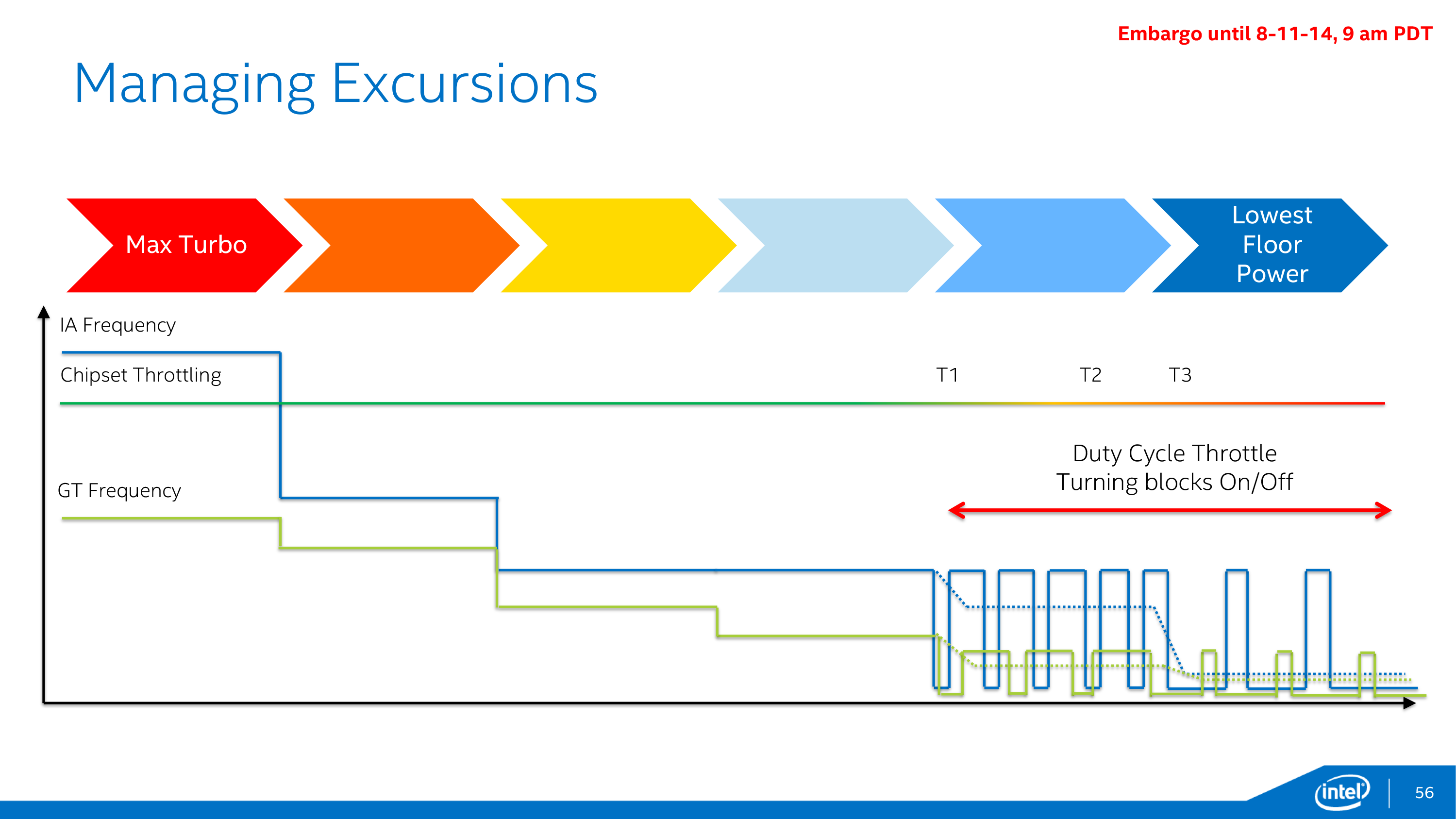
This brings us to the final element of Intel’s power optimization efforts, which involve further adjustments to turbo boost as part of Intel’s “hurry up and go to sleep” motto. New for Broadwell-Y is a 3rd power state, PL3, which allows for even greater turbo boosting, but for only a very limited period of time – on the order of milliseconds. PL3 represents the maximum amount of power the device battery can deliver, and while it’s okay to reach this value sparingly, PL3 is a fast drain that is very hard on the battery. The existence of PL3 in this case is as much for battery protection as it is for performance; it allows devices to tap into PL3 power levels on occasion, all the while allowing PL2 (the regular burst limit) to be defined at a safer value below the battery’s limit. Put another way, by knowing PL3 devices know how to stay farther away from it, which in the long run is what’s best for battery reliability.








158 Comments
View All Comments
psyq321 - Tuesday, August 12, 2014 - link
I also fail to see how will Intel be able to keep their cadence with Skylake without either skipping the entire generation (obsoleting it in 6 months does not sound reasonable from the financial point of view) or delaying the Skylake introduction.Also the fact that Intel decided to enable all 18 cores in the Haswell EP is telling IMHO. Initially, this was to happen only with BDW-EP, so it might not be impossible that Intel might just skip Broadwell for some segments and go with Skylake.
isa - Tuesday, August 12, 2014 - link
Those who know ain't talking, but I can observe the following;- Delaying Skylake for financial reasons related to Broadwell is braindead. Broadwell development costs are sunk costs and Intel is or should be trying to maximize overall profits, not just a particular program's profits. Intel should release Skylake as quickly as possible when its yields hit target values, regardless of Broadwell delays, with two caveats:
- If the Broadwell yield difficulties also slowed down Skylake, then Skylake will likely be inherently delayed to some degree
- If Intel screws up product planning such that they flood the market with Broadwell, then their customers might be very angry if they are stuck with that inventory upon a Skylake release.
My bet at this point? Broadwell H mobile will be a very short-lived product (about 6 months).
Krysto - Tuesday, August 12, 2014 - link
Definitely not Y or U, and wouldn't get M either. Whatever is above that.mczak - Monday, August 11, 2014 - link
For the gpu It is noteworthy that unlike nvidia and amd the subslice block (at least before gen8) doesn't really have an inherent minimal size which cannot be changed without significantly altering the architecture. E.g. Gen7 (which is just about the same as Gen7.5) had subslice sizes of 6 (IvyBridge GT1), 8 (IvyBridge GT2) and 4 even (BayTrail).It is also quite interesting that everybody (nvidia since gk2xx and Maxwell, amd since even before GCN, notably their Northern Islands VLIW4 designs, intel since Gen8) now has ended up with the exact same ALU:TEX ratio (one quad tmu per 64 ALU lanes), though of course the capabilities of these tmus vary a bit (e.g. nvidia can do fullspeed fp16 filtering, amd only half speed etc.)
tuxRoller - Monday, August 11, 2014 - link
http://www.phoronix.com/scan.php?page=article&...In the fourth to last paragraph an intel driver dev says that broadwell graphics "dwarf any other silicon iteration during my tenure, and certainly can compete with the likes of the gen3->gen4 changes."
I'm going to go with the guy who's actually developing the drivers on this.
AnnonymousCoward - Tuesday, August 12, 2014 - link
Simple question: will all the new Intel desktop CPUs have integrated graphics? If the answer's yes, why would they waste the silicon area for those using discrete?name99 - Tuesday, August 12, 2014 - link
Because the people who obsess about discrete graphics are a RIDICULOUSLY small fraction of the purchasing public, a fraction which is utterly unwilling to accept this fact and the fact that CPU design is not targeted at the needs of high-end gamers.wintermute000 - Tuesday, August 12, 2014 - link
"Because the people who obsess about discrete graphics are a RIDICULOUSLY small fraction of the purchasing public"Maybe not obsess, but to characterise the PC gaming market as ridiculously small, is pretty far off the mark....
DanNeely - Tuesday, August 12, 2014 - link
Compared to the total Intel CPU market and compared to the cost of creating an IGPless CPU die for the mainstream socket it's entirely on the mark. If you want an IGPless design your only choice is to wait a year for the Xeon derived LGA2011 model; and the fact that LGA1366 launched as an enthusiast design well before the Xeon's did, but that Intel hasn't done the same for any other models shows that it didn't sell well enough to justify rushing one for us.C'DaleRider - Tuesday, August 12, 2014 - link
Small fraction is right. Projected worldwide PC hardware sales for 2015 is ~ $385B (Source: eTForcasts). Projected PC gaming sales (both hardware and software) is ~$20B (Source: Statista), less than 10% of total PC hardware sales alone. A 10% market niche is very, very small in the overall scheme of the PC market.