Western Digital Updates Red NAS Drive Lineup with 6 TB and Pro Versions
by Ganesh T S on July 21, 2014 8:00 AM EST- Posted in
- NAS
- Storage
- Western Digital

Back in July 2012, Western Digital began the trend of hard drive manufacturers bringing out dedicated units for the burgeoning NAS market with the 3.5" Red hard drive lineup. They specifically catered to units having 1-5 bays. The firmware was tuned for 24x7 operation in SOHO and consumer NAS units. 1 TB, 2 TB and 3 TB versions were made available at launch. Later, Seagate also jumped into the fray with a hard drive series carrying similar firmware features. Their differentiating aspect was the availability of a 4 TB version. Western Digital responded in September 2013 with their own 4 TB version (as well as a 2.5" lineup in capacities up to 1 TB).
Today, Western Digital is making updates to their Red lineup for the third straight year in a row. The Red lineup gets the following updates:
- New capacities (5 TB and 6 TB versions)
- New firmware (NASware 3.0)
- Official sanction for use in 1-8 bay tower form factor NAS units
In addition, a new category is also being introduced, the Red Pro. Available in 2 - 4 TB capacities, this is targeted towards rackmount units with 8 - 16 bays (though nothing precludes it from use in tower form factor units with lower number of bays).
WD Red Updates
Even though 6 TB drives have been around (HGST introduced the Helium drives last November, while Seagate has been shipping Enterprise Capacity and Desktop HDD 6 TB versions for a few months now), Western Digital is the first to claim a NAS-specific 6 TB drive. The updated firmware (NASware 3.0) puts in some features related to vibration compensation, which allows the Red drives to now be used in 1 - 8 bay desktop NAS systems (earlier versions were officially sanctioned only for 1 - 5 bay units). NASware 3.0 also has some new features to help with data integrity protection in case of power loss. The unfortunate aspect here is that units with NASware 2.0 can't be upgraded to NASware 3.0 (since NASware 3.0 requires some recalibration of internal components that can only be done in the factory).
The 6 TB version of the WD Red has 5 platters, which makes it the first drive we have seen to have an areal density of more than 1 TB/platter (1.2 TB/platter in this case). This areal density increase is achieved using the plain old Perpendicular Magnetic Recording (PMR) technology. Western Digital has not yet found reason to move to any of the new technologies such as SMR (Shingled Magnetic Recording), HAMR (Heat-assisted Magnetic Recording) or Helium-filling for the WD Red lineup.The 5 TB and 6 TB versions also have WD's StableTrac technology (securing of the motor shaft at both ends in order to minimize vibration). As usual, the drive comes with a 3 year warranty. Other aspects such as the rotation speed, buffer capacity and qualification process remain the same as that of the previous generation units.
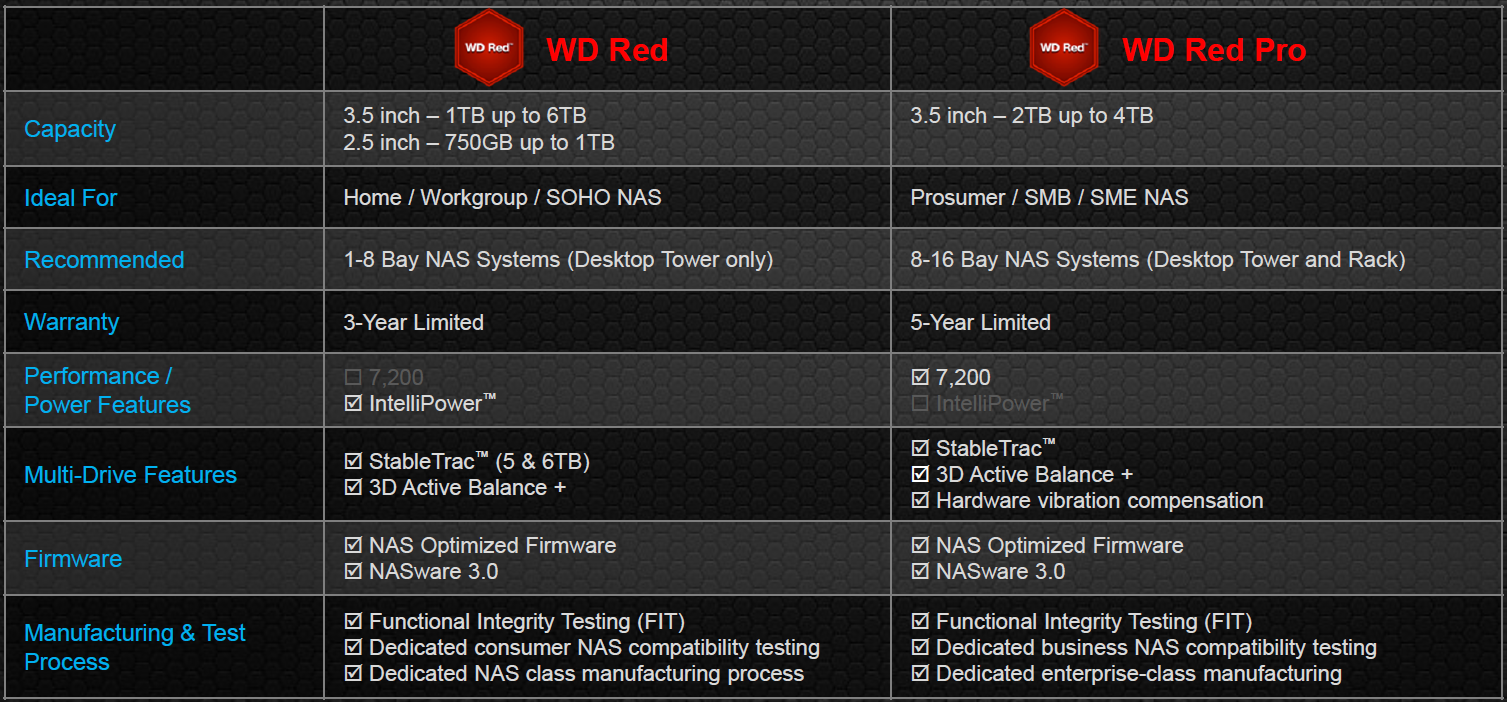
WD Red Pro
The Red Pro targets medium and large business NAS systems which require more performance by moving to a rotation speed of 7200 rpm. Like the enterprise drives, the Red Pro comes with hardware-assisted vibration compensation, undergoes extended thermal burn-in testing and carries a 5-year warranty. 2, 3 and 4 TB versions are available, with the 4 TB version being a five platter design (800 GB/platter).
The WD Green drives are also getting a capacity boost to 5 TB and 6 TB. WD also specifically mentioned that their in-house NAS and DAS units (My Cloud EX2 / EX4, My Book Duo etc.) are also getting new models with these higher capacity drives pre-installed. The MSRPs for the newly introduced drives are provided below
| WD Red Lineup 2014 Updates - Manufacturer Suggested Retail Prices | ||
| Model | Model Number | Price (USD) |
| WD Red - 5 TB | WD50EFRX | $249 |
| WD Red - 6 TB | WD60EFRX | $299 |
| WD Red Pro - 2 TB | WD2001FFSX | $159 |
| WD Red Pro - 3 TB | WD3001FFSX | $199 |
| WD Red Pro - 4 TB | WD4001FFSX | $259 |
We do have review units of both the 6 TB WD Red and the 4 TB WD Red Pro. Look out for the hands-on coverage in the reviews section over the next couple of weeks.








37 Comments
View All Comments
ericloewe - Monday, July 21, 2014 - link
If you read their spec sheet, it says 10^14.Per Hansson - Wednesday, July 23, 2014 - link
The spec for the regular Red & Red Pro differ, is it just marketing bullshit to make the numbers look better when infact they are the same?Non-Recoverable Read Errors per Bits Read:
<1 in 10^14 WD Red
<10 in 10^15 WD Red Pro
Just for reference the Seagate Constellation ES.3, Hitachi Ultrastar He6 & 7K4000 are all rated for: 1 in 10^15
Guspaz - Monday, July 21, 2014 - link
The solution to that is raid6 or raidz2. The chances of having a read error during a rebuild isn't that remote (as you point out, 10^14 bits implies a read error is likely in larger arrays, although 10^14 is 12.5TB rather than 11.5). The chances of having a read error during a rebuild in the exact same spot on two drives is astronomical.There definitely is a capacity sacrifice that has to be made to do that, though. My current setup is a single ZFS pool spread over two arrays that are both using raidz2. 7x4TB and 8x2TB, for a total of 44TB of which I lose 2x4+2x2=12TB, giving me a total of 32TB of usable storage space in the end. So I'm losing a bit over a quarter of my space, which isn't too bad.
If (when) I need more storage space, I can just swap those 2TB drives for 6TB ones, bumping me up to 76TB total, 56TB usable. Won't be cheap, of course, but 6TB drives should be a bunch cheaper by the time I need to do that.
asmian - Monday, July 21, 2014 - link
Which is why anyone who cares about their data wouldn't touch drives this big with such poor error rates. You need the RE class drives with 1 in 10^15 unrecoverable read error rates, an order of magnitude better. Size isn't everything, and the error rates of consumer-class drives make their sheer size a liability. Just putting them in a RAID array isn't a panacea for their basic unreliability, unless you like to waste time nursing failed arrays.ZeDestructor - Monday, July 21, 2014 - link
You move the error handling higher up by adding more redundancy (RAID6+/RAIDZ2+) instead. In almost all cases, it works out being significantly cheaper than paying for RE disks.asmian - Monday, July 21, 2014 - link
I'd doubt your overall cost saving taking respective MTBF and warranties into account, and it's not only about cost. As the original questioner stated, it's the risk of ANOTHER disk in your array failing while you're rebuilding after a failure. The sheer size of these disks makes that statistically much more likely since so much more data is being read to recover the array. Throwing more redundancy at the problem saves your array at the initial point of failure, but you're going to be spending more time in a slower degraded rebuild mode, hence increasing the risk of further cheap disks dying in the process, than if you'd invested in more reliable disks in the first place. :/ It's the combination of the enormous size of the individual disks and lower intrinsic reliability that's the issue here.cygnus1 - Monday, July 21, 2014 - link
an unrecoverable read error is not an entire drive failure. raidz2/raid6 protects you during a rebuild from the cheap drives having a single sector unrecoverable read error.asmian - Monday, July 21, 2014 - link
That is meaningless because you are invoking that "protection" as if it is a guarantee - it's not. You're still playing the odds against more drives failing. You might be lucky, you might not. The issue is whether that 1 in 10^14 chance is statistically likely to occur during the massive amount of reading required to rebuild arrays using such large disks as these 6TB monsters.Newsflash - 6TB is approx 0.5 X 10^14 bits. So during a full rebuild EVERY DISK IN THE ARRAY has a 50% chance of an error if they are 6TB disks with that level of unrecoverable error rate. THAT'S why the bigger the disk I'd rather have one with 10x the error rate reliability - due to the size of these disks it's weighing 50% failure risk PER DISK during rebuild against 5%. Extra redundancy, however clever ZFS is, can't mitigate against those statistics.
ZeDestructor - Monday, July 21, 2014 - link
ZFS should be able to catch said errors. The issue in traditional arrays is that file integrity verification is done so rarely that UREs can remain hidden for very long periods of time, and consequently, only show up when a rebuild from failure is attempted.ZFS meanwhile will "scrub" files regularly on a well-setup machine, and will catch the UREs well before a rebuild happens. When it does catch the URE, it repairs that block, marks the relevant disk cluster as broken and never uses it again.
In addition, each URE is only a single bit of data in error. The odds of all drives having the URE for the exact same block at the exact same location AND the parity data for that block AND have all of those errors happen at the same time is extremely small compared to the chance of getting 1bit errors (that magical 1x10^14 number).
Besides, if you really get down to it, that error rate is the same for smaller disks as well, so if you're building a large array, the error rate is still just as high, but now spread over a larger amount of disks, so while the odds of a URE is smaller (arguable, I'm not going there), the odds of a physical crash, motor failure, drive head failure and controller failure are higher, and as anyone will tell you, far more likely to happen than 2 or more simultaneous UREs for the same block across disks (which is why you want more than 1 disk worth of parity, so there is enough redundancy DURING the rebuild to tolerate the second URE hapenning on another block)
asmian - Monday, July 21, 2014 - link
Yay for ZFS if it really can work like you claim and negate all reliability deficiencies in drives. You may be safe using these.However, DanNeely's comment almost immediately below this is the far more likely scenario for the majority who try making non-ZFS arrays. Read that and remember there's a 50% chance of bit error with EVERY 6TB drive in a full array rebuild. That is how they are more likely to be used by low-knowledge users buying only for size at lowest available $/GB or £/GB - note that these 6GB drives are NOT being marketed as for ZFS only.