6 TB NAS Drives: WD Red, Seagate Enterprise Capacity and HGST Ultrastar He6 Face-Off
by Ganesh T S on July 21, 2014 11:00 AM ESTPerformance - Raw Drives
Prior to evaluating the performance of the drives in a NAS environment, we wanted to check up on the best-case performance of the drives by connecting them directly to a SATA 6 Gbps port. Using HD Tune Pro 5.50, we ran a number of tests on the raw drives. The following screenshots present the results for the various drives in an easy-to-compare manner.
Sequential Reads
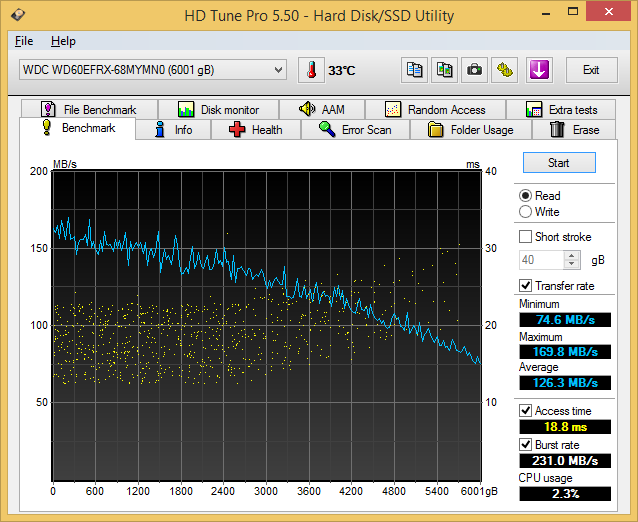
The Seagate Enterprise Capacity drive, as expected, leads the benchmark numbers with an average transfer rate of around 171 MBps. The HGST unit (142 MBps) performs better than the WD Red (126 MBps) in terms of raw data transfer rates, thanks to the higher rotational speed. The burst rate of the Seagate drive is also higher. In effect, the higher amount of cache memory on the Seagate drive helps it to perform well in this test.
Sequential Writes
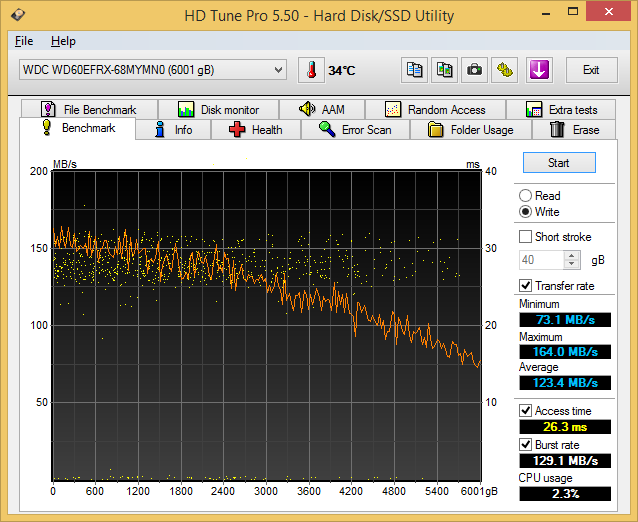
A similar scenario plays out in the sequential write benchmarks. The Seagate drive leads the pack with an average transfer rate of 168 MBps followed by the HGST one at 139 MBps. The WD Red's 123 MBps is the slowest of the lot, but these results are foregone conclusions due to the lower rotational speeds in the Red.
Random Reads
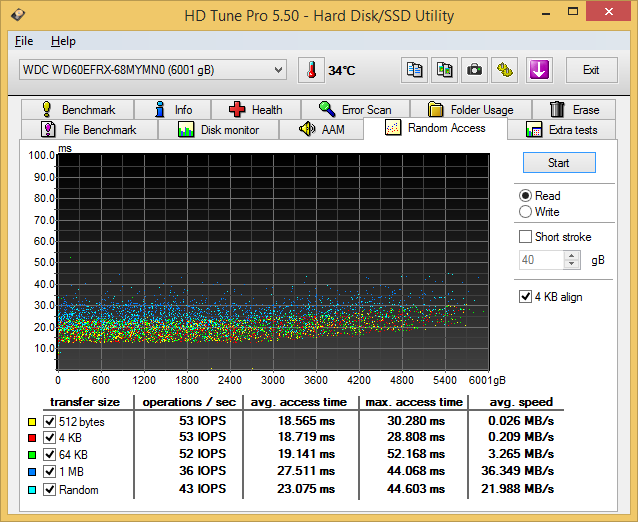
In the random read benchmarks, the HGST and Seagate drives perform fairly similar to each other in terms of IOPS as well as average access time.
Random Writes
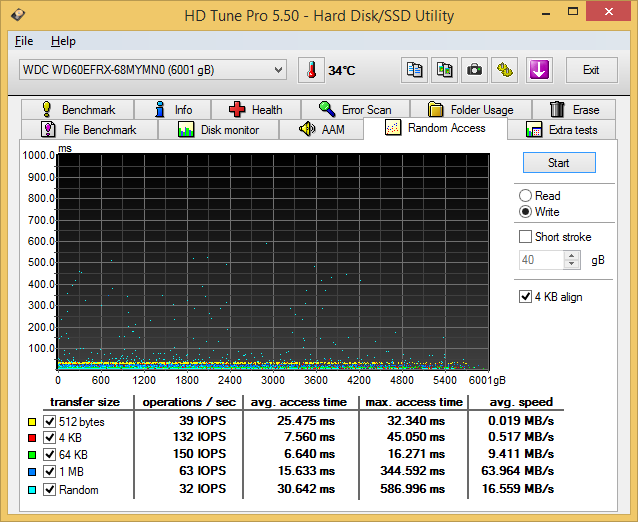
The differences between the enterprise-class drives and the consumer / SOHO NAS drives is even more pronounced in the random write benchmark numbers. However, the most interesting aspect here is that the HGST Ultrastar He6 wins out on the IOPS for 512B transfers due to its sector size. Otherwise, the familiar scenario that we observed in the previous subsections play out here too.
Miscellaneous Reads
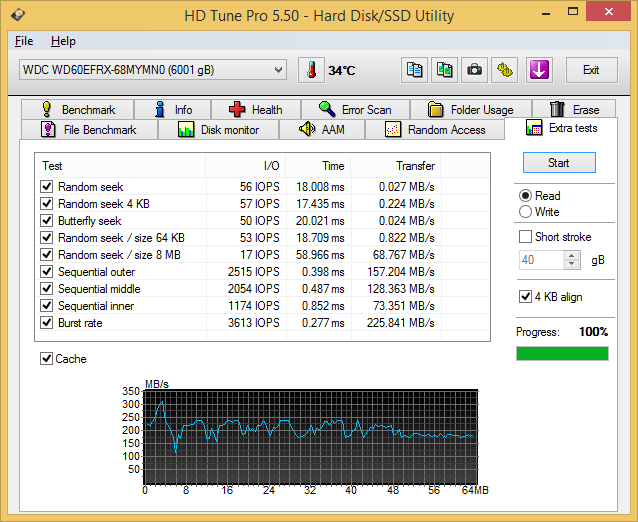
HD Tune Pro also includes a suite of miscellaneous tests such as random seeks and sequential accesses in different segments of the hard disk platters. The numbers above show the HGST and Seagate drives matched much more evenly. The cache effects are also visible in the final graph.
Miscellaneous Writes
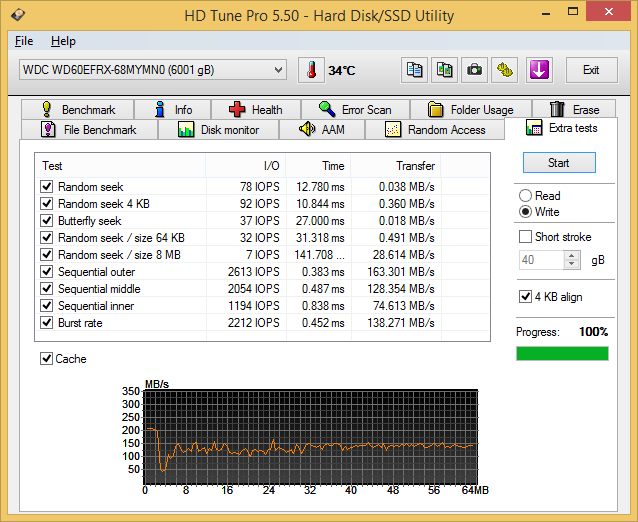
Similar to the previous sub-section, we find that the Seagate and HGST drives quite evenly matched in most of the tests. The HGST drive does exhibit some weird behaviour with the burst rate test and the Seagate one with the 8 MB random seek tests, while the Red is consistent across all of them without being exceptional.
We now have an idea of the standalone performance of the three drives being considered today. In the next section, we will take a look at the performance of these drives when subject to access from a single client - as a DAS as well as a NAS drive.








83 Comments
View All Comments
NonSequitor - Thursday, July 24, 2014 - link
So something isn't adding up here. I have a set of nine Red 3TB drives in a RAID6. They are scrubbed - a full rebuild - once a month. They have been in service for a year and a half with no drive failures. Since it's RAID6, if one drive returns garbage it will be spotted by the second parity drive. Obviously they can't be returning bad data, or they would have been failed out long ago. The array was previously made of 9 1TB Greens, scrubbed monthly, and over two and a half years I had a total of two drive failures, one hard, one a SMART pre-failure.asmian - Friday, July 25, 2014 - link
Logically, I think this might well be due to the URE masking on these Red drives - something the Green drives weren't doing. You've been lucky that with a non-degraded RAID6 you've always had that second parity drive that has perhaps enabled silent repair by the controller when a URE occurred. I've been pondering more about this and here's what I have just emailed to Ganesh, with whom I've been having a discussion...--------------------
On 24/07/2014 03:45, Ganesh T S wrote:
> Ian,
>
> Irrespective of the way URE needs to be interpreted, the points you
> raise are valid within a certain scope, and I have asked WD for their
> inputs. I will ping Seagate too, since their new NAS HDD models are
> expected to launch in late August.
Thanks. This problem is a lot more complicated than it looks, I think, and than a single URE figure might suggest. But the other "feature" of these Red drives is also extremely concerning to me now. I am a programmer and often think in low-level algorithms, and everything about this URE masking seems wrong in the likely usage scenarios. Please help me with my logic train here - correct me if I'm wrong. Let's assume we have an array of these Red drives. Irrespective of the chance of a URE while the array is rebuilding or in use, let's assume one occurs. You have stated WD's info that the URE is masked and the disk simply returns dummy info for the read.
If you were in a RAID5 and you were rebuilding after you've lost a drive, that MUST mean the array is now silently corrupted, right? The drive has masked the read failure and reported no error, and the RAID controller/software has no way to detect the dummy data. Critically, having a back-up doesn't help if you don't know that you NEED to repair or restore damaged files, and without a warning, due to simple space contraints a good backup will likely be over-written with one that now contains the corrupted data... so all ways round you are screwed. Having a masked URE in this situation is worse than having one reported, as you have no chance to take any remedial action.
If you are in RAID6 and you lost a drive, then you still have a parity check to confirm the stripe data with while rebuilding. But if there's a masked URE and dummy data, then how will the controllers react? I presume they ALWAYS test the stripe data with the remaining parity or parities for consistency... so at that point the controller MUST throw a major rebuild error, right? However, they cannot determine which drive gave the bad data - just that the parity is incorrect - unless it's a parity disc that errored and one parity calculates correctly while the other is wrong. If they knew WHICH disc had UREd then they could easily exclude it from the parity calculation and rebuild that dummy data on the fly with the spare parity, but the masking makes that impossible. The rebuild must fail at this point. At least you have your backups... hopefully.
Obviously the above situation will also be the same for a RAID5 array in normal usage or a degraded RAID6. Checking reads with parity, a masked URE means a failure with no way to recover. If you have an unmasked URE at least the drive controller can exclude the erroring disc for that stripe and just repair data silently using the remaining redundancy, knowing exactly where the error has come from. After all, it's logically just an EXPECTED disk event with a statistically low chance of happening, not necessarily an indication of impending disk failure unless it is happening frequently on the same disc. The only issue will be the astronomically unlikely chance of another URE occurring in the same stripe on another disc.
Fundamentally, a masked URE means you get bad data without any explanation of why a disc is returning it, which gives no information to the user (or to the RAID controller so it can take action or warn the user appropriately). For me, that's catastrophic. It all really depends on what the controllers do when they discover parity errors and UREs in rebuild situations and how robust their recovery algorithms are - an unmasked URE does not NEED to be a rebuild-killer for RAID6, as thank G*d you had a second redundancy disc...
Anyway, the question will be whether these new huge drives will, as you say, accumulate empirical evidence from users that array failures are happening more and more frequently. Without information from reviews like yours that warn against their use in RAID5 (or mirrors) despite the marketing as NAS products, the thought-experiment above suggests the most likely scenario is extremely widespread silent array corruption. I stand by my comment that this URE masking should be a total deal-breaker in considering them for home array usage. Better a disk that at least tells you it's errored.
NonSequitor - Tuesday, July 29, 2014 - link
That still doesn't add up - there are no unmasked UREs in my situation, as I'm using Linux software RAID. It is set to log any errors or reconstructions, and there are literally none. One of these arrays has a dozen scrubs on it now with no read errors whatsoever.m0du1us - Friday, July 25, 2014 - link
@asmian This is why we run 28 disk arrays minimum for SAN. If you really want RAID6 to be reliable, you need A LOT of disks, no matter the size. Larger disks decrease your odds of rebuilding the array, that just means you need more disks. Also, you should never build a RAID6 array with less than 5 disks. At 5 disks, you get no protection from a disk failure during rebuild. At 12 disks, You can have 2 spares and 2 failures during rebuild before loosing data.NonSequitor - Friday, July 25, 2014 - link
Your comment makes no sense. A five disk RAID-6 is N+2. A 28 disk RAID-6 is N+2. More disks will decrease reliability. Our storage vendor advised keeping our N+2 array sizes between 12 and 24 disks, for instance: 12 disks as a minimum before it started impacting performance, 24 disks as a maximum before failure risks started to get too high. Our production experience has borne this out. Bigger arrays are actually treated as sets of smaller arrays.LoneWolf15 - Friday, July 25, 2014 - link
asmian, it totally depends on what you are building the array for, and how you are building it.Myself, I'd use them for home or perhaps small business, but in a RAID 10 or RAID 6. Then I'd have some guaranteed security. That said, if I needed constant write performance (e.g., multiple IP cameras) I'd use WD RE, and if I wanted enterprise level performance, I'd use enterprise drives.
That, and I realize that RAID != backup strategy. I have a RAID-5 at home; but I sure as heck have a backup, too.
tuxRoller - Monday, July 21, 2014 - link
Hi Ganesh,Would you mind listing the max power draw of these drives? That is, how much power is required during spin-up?
WizardMerlin - Tuesday, July 22, 2014 - link
If you're not going to show the results on the same graph then for the love of god don't change the scale of the axis between graphs - makes quick comparison completely impossible.ganeshts - Tuesday, July 22, 2014 - link
I have tried that before and the problem is that once all the drives are on the same scale, then some of them become really difficult to track absolute values across. Been down that road and decided the issues it caused are not worth the effort taken for readers (including me and my colleagues) to glance right and left on the axes side to see what the absolute numbers are.Iketh - Tuesday, July 22, 2014 - link
what? why would they become difficult to "track absolute values" ??