ARM’s Mali Midgard Architecture Explored
by Ryan Smith on July 3, 2014 11:00 AM EST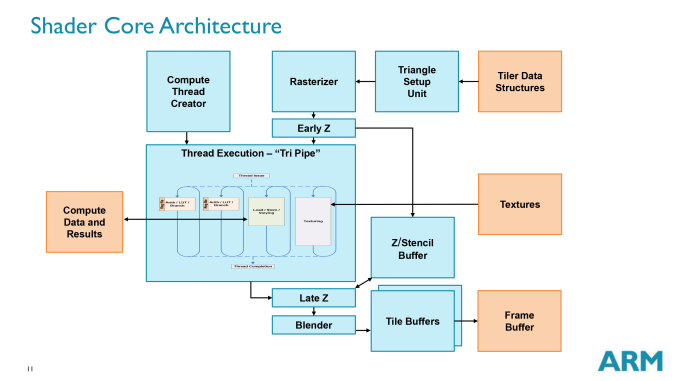
So far this is shaping up to be a banner year for SoCs. From a market perspective the mobile hardware space is still in a period of significant growth, but more importantly from a hardware point of view these products and especially the GPUs in these products have made significant strides in performance and in features. SoC GPUs will approach feature parity with desktop GPUs this year, and from a performance perspective they’re nearing the performance of the last-generation game consoles, a long-aspired goal given the “good enough” status attached to those devices.
Meanwhile at the same time that these products are maturing at a technical level, we’ve seen the various SoC firms mature at a professional level. The “wild west” days of SoCs have given way to mature markets of longer product cycles, longer product lives, and a more stable market overall. This both good and bad news for the various players in the SoC market as firms get squeezed out – SoC integrators such as TI and STMicroelectronics have been the first of such victims – but it also means that as companies become better established and more deeply entrenched, they can be more open about their projects and their products, and discuss them in greater detail than before without needing to be concerned about getting scooped by a competitor.
Here at AnandTech we’re particularly fond of doing architectural deep dives; our chance to talk to the people behind various processors and learn from them about how their products work and how they came together. Thanks to the maturation of the SoC market we’re finally getting a level of access in the SoC market that we haven’t had before, and in turn for the first time we get to tell the stories of the people behind these mind-bogglingly complex devices while better learning how they operate and as such how they compare. It’s admittedly a level of access we take for granted in the PC space, where companies such as Intel, AMD, and NVIDIA are regularly open, but it’s hard to contain our excitement about gaining this kind of access to the myriad of players in the SoC space.
This year then has been especially productive in that regard, and as of today it’s going to get even better. After we took a look at Imagination’s PowerVR Rogue architecture earlier this year, ARM contacted us and indicated that they would like to do the same; that they would like to take a seat at the “open architecture” table. To give us the access we need to discover how their GPUs work, and in turn tell you what we’ve learned.

To that end we’ve gladly let ARM pull up a seat, and today we’ll be taking our first in-depth look at ARM’s newest Mali SoC GPU architecture: Midgard. Now as with Imagination what we’re seeing today is most, but not all of the picture, as ARM has their secrets and they wish to keep some of them. But today we get to learn all about Midgard’s shader cores while also learning a thing or two about its pixel rendering pipeline, power optimizations, and other aspects of what makes Midgard tick. In other words, more than enough to keep us busy for one day.
But before we dive in we’d also like to quickly call attention to an Ask The Experts session we held with ARM’s Jem Davies, an ARM Fellow and VP of Technology in the Media Processing Division. While our deep dive is focusing on Midgard’s architecture, Jem has been answering all sorts of additional Mali-related questions, including business strategy and ARM’s views on GPU computing.
Finally, as this is the second article in our continuing series on SoC GPUs, we will be picking up from where we left off after our last article. While all of our articles are meant to be accessible to some degree, if you haven’t caught any of our previous articles I’d highly recommend our primer on how GPUs work for a quick overview of the technology before we dive into the nuts and bolts of ARM’s Midgard architecture.








66 Comments
View All Comments
tuxRoller - Monday, July 7, 2014 - link
Yup, that is indeed what I said earlier.I don't think anand is interested in investigating that avenue, however. For one, he might fear that such published info would blacklist him from future qualcomm info dumps (pretty far fetched, imho, but AT likes the corporate relationships its been able to cultivate). For another, AT doesn't seem to be terribly interested in oss.
prabindh - Monday, July 7, 2014 - link
Do the GFLOPS give a measure of how much performance an OpenCL kernel can provide in ARM Mali architecture ? Simple fp16/32 kernels doing a MAD and writing to global memory do not seem to match the GFLOPS calculated here. Are there other HW LD/ST limits in the pipeline (assuming no system memory Bandwidth limitations) ?Amadiro - Friday, July 11, 2014 - link
So how do the dFdx/dFdy operators work for such a non-wavefront based design? Does using them imply a huge overhead/stall/context-switch of some sort on this kind of architecture?MrSpadge - Wednesday, August 13, 2014 - link
Thanks ARM, Ryan and Anandtech for this very interesting article! This finally gives this "yet another SoC GPU irrelevant to me" a face. And I think ARM could employ this design for some very nice GP-GPU (co-)processors:- FP64 performance rivaling the best
- not relying on TLP could open up the GPU for entire new application ranges where they just didn't make sense yet
- ARM can scale the amount of compute per core easily
I know building a massive GP-GPU chip is anything but trivial.. but this seems an architecture worthy of this!
manoj1919 - Friday, September 25, 2015 - link
Hi Anand,Nice article!.I am working with mali GPU, and I am a researcher trying to figure out power management capabilities of MALI GPU. last part of this article seems to be covering a bit of that. can you please point me to the source of ARM's slide showing gating techniques of MALI GPU(last figure in article).
Thanks in advance,
Manoj
gregware - Monday, February 20, 2017 - link
Interesting article, thanks!