ARM’s Mali Midgard Architecture Explored
by Ryan Smith on July 3, 2014 11:00 AM ESTTricks of the Trade: Transaction Elimination and Frame Buffer Compression
While we have spent some time covering various techniques ARM uses to improve efficiency in Midgard, we wanted to spend a bit more time talking about two specific techniques in general that we find especially cool: transaction elimination and frame buffer compression.
Going back once again to what we said earlier about rendering and power efficiency, any rendering work ARM can eliminate before it’s completed not only improves performance by freeing up resources, but it also frees up power by not having to spend it on said redundant work. This is especially the case for anything that wants to hit system memory, as compared to the on-die caches and memories available to the GPU, system memory is slow and expensive to operate from a power perspective.
For their final two tricks then, having already eliminated as much rendering work as possible through other means, ARM’s last tricks involve minimizing the amount of data from rendered tiles and pixels that needs to hit system memory. The first of these tricks is Transaction Elimination (TE), which is based on the idea that if a scene (or parts of it) do not change, then it makes no sense to spend power and bandwidth rewriting those identical screen portions.
![]()
To accomplish this, ARM relies on their tiling system to break down the scene for them, and from there they can begin comparing tiles that are waiting for finalization (ROP/blending) to the tiles that are already in the frame buffer from the previous frame. Using a simple cyclic redundancy check to compare the tiles, if the tile to be rendered is found to be identical to the tile already there, the tile can be skipped and the memory bandwidth saved. Altogether of all of ARM’s various tricks, this is among the simplest conceptually.
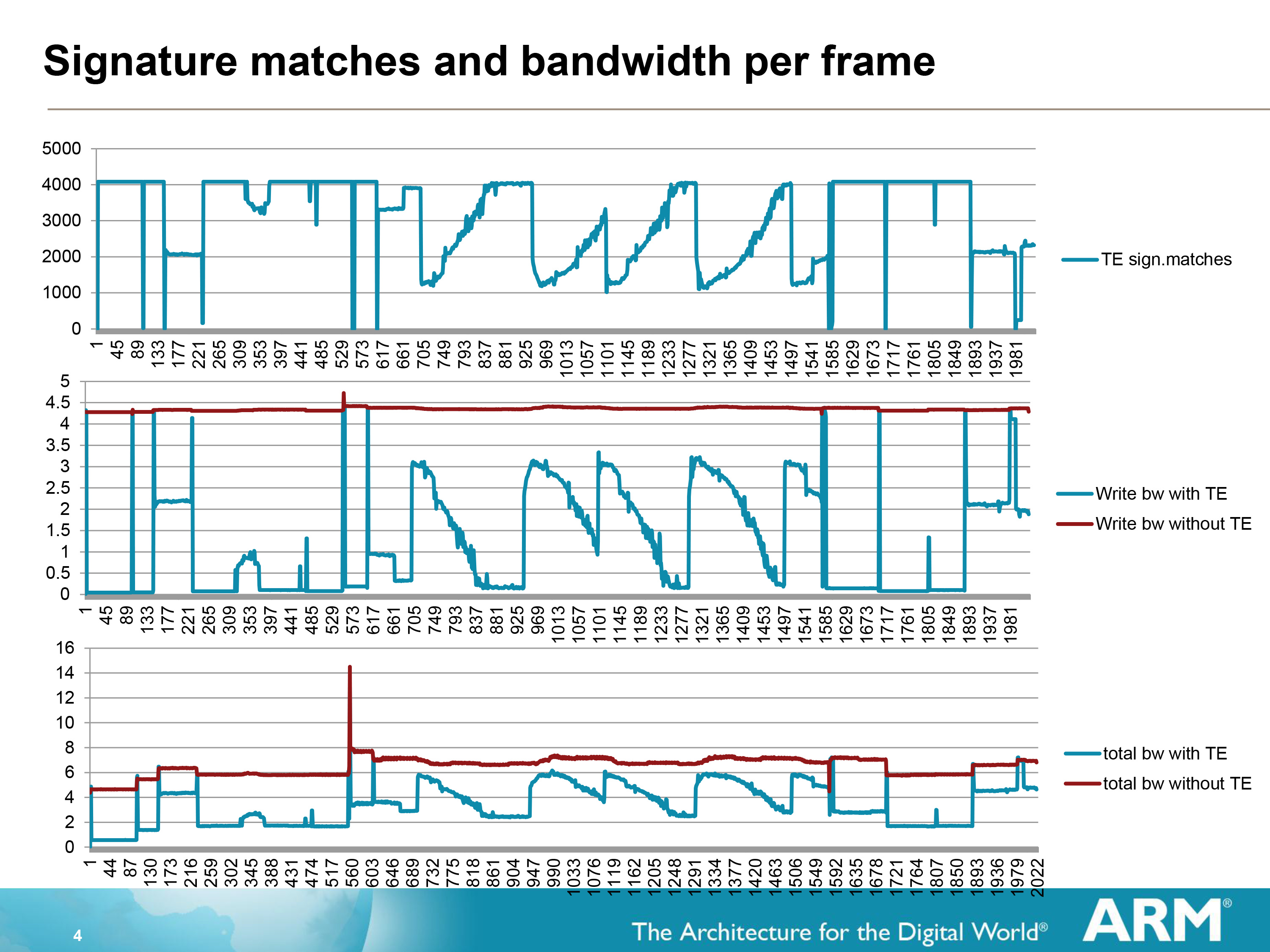
The effectiveness of Transaction Elimination in turn depends on the content. A generally static workload such as a movie will have a high degree of redundancy overall (notably when the camera is not moving), while a game may have many moving elements but will still have redundant elements that can be skipped. As a result ARM can save anywhere between almost nothing and over 99% for a highly static workload, with the average more than offsetting the roughly 1.5% overhead from computing and comparing the CRCs.
Of course Transaction Elimination does have one drawback besides its low overhead, and that is CRC collisions. During a CRC collision a pair of tiles that are different will compute to the same CRC value, and as such Transaction Elimination will consider them identical and throw away the new tile. With a standard CRC value being 64bits, such a collision is rare but not impossible, and indeed will statistically occur sooner or later. In which case Transaction Elimination has no fallback method; it is judge, jury, and executioner as it were, and the new tile will be lost.
As a result Transaction Elimination is interestingly imprecise in a world of precision. When a collision occurs the displayed tile will be wrong, but only for as long as there is a collision, which in turn should only be for 1 frame, or 1/60th of a second.
Moving on, when worse comes to worse and ARM does need to write a new tile, on the Mali-T700 series GPUs they can turn to ARM Frame Buffer Compression (AFBC) to minimize the amount of memory bandwidth they spend on that operation. By using a lossless compression algorithm to write out and store a frame, memory bandwidth is saved on both the writing of the frame and in the reading of it.
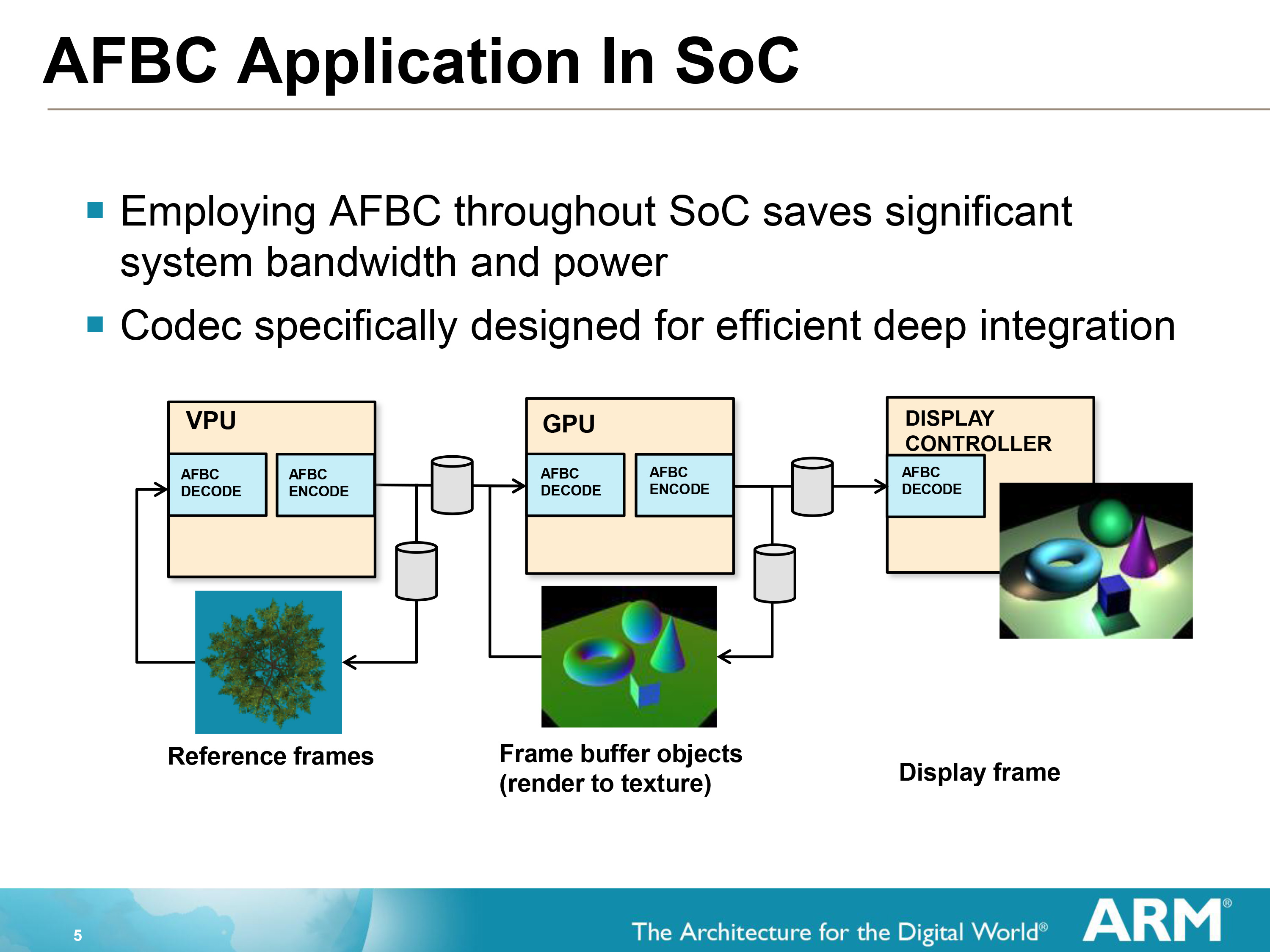
AFBC requires that both the GPU and the Display Controller support the technology, as the frame remains compressed the entire time until decompressed for display/consumption. Interestingly this means that the GPU needs to be able to compress as well as decompress, as it can reuse its own frames either in frame buffer objects (where a frame is rendered to a texture) or in Transaction Elimination. This becomes a secondary vector of saving bandwidth since it results in similar bandwidth savings for the frame even if the frame is never touched by the display controller itself. A similar principle applies to ARM’s video decoders (VPUs) which can use AFBC to compress a frame before shipping it off to the GPU.
On that note, it’s worth pointing out that while AFBC is an ARM technology, for interoperability purposes ARM does license it out to other display controller designers. ARM puts together their own display controllers, but because SoC integrators can use one of many display controllers it’s to ARM’s own benefit that everyone else be able to read AFBC as well as ARM can.








66 Comments
View All Comments
kkb - Monday, July 7, 2014 - link
I hope you do understand how to read benchmark results. 3dmark and GFXbench(offscreen) results are resolution independent. Now go and check the results in the article.As per T760, I will not comment on theoretical GFLOP numbers unless there is real product. Even the theoretical MAD GFLOPs are not so great (roughly half) compared to others. I don't think anyone going to fall for marketing gimmick of taking dot product also as extra 40 GFLOPs
darkich - Monday, July 7, 2014 - link
You said it definitely performs better yet it loses on the T Rex HD onscreen and in Basemark X overall. That's not definite you know.Regardless, even if a case can be made that it performs slightly better overall than the Mali T628, it is without doubt outperformed by the :
ULP Gforce 3
Adreno 330
Sgx G6320
.. and is *definitely* far outclassed by the Adreno 420, Kepler K1, SGX G6550, Mali T760MP6-10.
Until Intel shows their next generation of ULP graphics, I don't see a point in comparing the current one
darkich - Monday, July 7, 2014 - link
Correction, I believe the GPU in Tegra 4 is internally referred to as the ULP GeForce 4, not 3fithisux - Friday, July 4, 2014 - link
Could you provide an expository of C66x architecture since it is suitable in my opininion for GPGPU tasks and realtime software rendering/raytracingjann5s - Friday, July 4, 2014 - link
lol, I thought this expression was wrong: "the proof is in the pudding", but in fact I was wrong: http://en.wiktionary.org/wiki/the_proof_is_in_the_...toyotabedzrock - Friday, July 4, 2014 - link
I wish you would have talked more about the GPU in the Nexus 10 since that is a shipping product. It would be nice to know how it differs from the newer midgard designs.seanlumly - Friday, July 4, 2014 - link
Another interesting point to make about the Mali architecture (that goes unnoticed, but is significant) is that the anti-aliasing is fully pipelined, tiled (read zero bandwidth penalty for the op), and very fast. MSAA 4x costs 1 cycle, MSAA 8x costs 2 cycles, and MSAA 16x costs 4 cycles. This means that if you have a scene full of fragment shaders running for more than 4 cycles (which is not too complex these days) you get the benefit of ultra-high quality MSAA 16x for FREE.There aren't too many examples of MSAA 16x online, but even at MSAA 8x performs very well, with sharp, non-blurry results and is often compared against. MSAA would produce very crisp edges devoid of aliasing and crawling during animation.
Of course, MSAA isn't perfect -- it isn't terribly helpful for deferred renderers -- but it certainly doesn't hurt them when its costs are nothing, even if you are planning to do a screen-space pass in post.
toyotabedzrock - Friday, July 4, 2014 - link
Oddly the best open source driver is for adreno GPU, perhaps you should ask that person what he knows about it?ol1bit - Saturday, July 5, 2014 - link
This is another fantastic job guys! Thanks to you and Thanks to Midgard for sharing!cwabbott - Saturday, July 5, 2014 - link
Well, if they won't cough up the information, then there's always freedreno... Rob Clark has reverse engineered basically everything you would want to know about the Adreno architecture, up to even more detail than this article. All that remains is to fill in the pieces based on the documentation he's written...