Imagination's PowerVR Rogue Architecture Explored
by Ryan Smith on February 24, 2014 3:00 AM EST- Posted in
- GPUs
- Imagination Technologies
- PowerVR
- PowerVR Series6
- SoCs
Technical Comparisons
Finally, to close out this look at the Rogue architecture we wanted to spend a bit of time looking at how it compares to other architectures. Unfortunately the lack of details we have on other SoC GPU architectures means we can’t make any meaningful comparisons there beyond the GFLOPs comparisons we do today (and that says nothing of real world efficiency). But we can compare it to the next best thing, which is mobile parts based on desktop GPU architectures from AMD and NVIDIA. The latter case being especially interesting, as we know Kepler will be coming to SoCs with the K1.
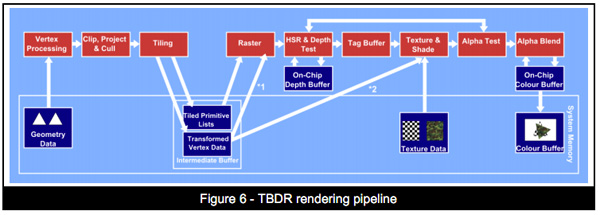
With that said, and we can’t reiterate this enough, this is just a look at theoretical performance. It is not possible to take into account efficiency measures such as memory bandwidth, ROPs, or especially early rejection optimizations such as Tile Based Deferred Rendering. TBDR is Imagination’s ace, and while other GPU firms have their own early rejection technologies, from what little we know about each of them, none of them quite matches TBDR. So Rogue’s theoretical performance aside, if Imagination is rejecting significantly more work before it hits their shaders, then they would have greater performance when all other factors were held equal. The only way to compare the real world performance of these architectures is to benchmark their real world performance, so please do not consider this the final word on performance.
For this comparison we’ll be looking at NVIDIA’s Kepler based K1, AMD’s GCN based A4-1350, and Imagination’s Rogue based GX6650 and G6230. Because Rogue is offered in multiple configurations it’s difficult to determine just how large a Rogue configuration would equal K1 or A4-1350 from a performance and size perspective, but given the anticipated integration time for Series 6XT, a 6 cluster configuration seems the most likely.
| GPU Specification Comparison | |||||||
| NVIDIA K1 | Imagination PVR GX6650 | Imagination PVR G6230 | AMD A4-1350 | NVIDIA GTX 650 | |||
| FP32 ALUs | 192 | 192 | 64 | 128 | 384 | ||
| FP32 FLOPs | 384 | 384 | 128 | 256 | 768 | ||
| Pixels/Clock (ROPs) | 4 | 12 | 4 | 4 | 16 | ||
| Texels/Clock | 8 | 12 | 4 | 8 | 32 | ||
| GFLOPS @ 300MHz | 115.2 GFLOPS | 115.2 GFLOPS | 38.4 GFLOPS | 76.8 GFLOPS | 230.4 GFLOPS | ||
| Architecture | Kepler | Rogue (6XT) | Rogue (6) | GCN 1.0 | Kepler | ||
Briefly, we can see that as far as theoretical shading performance is concerned, both the GX6650 and K1 are neck-and-neck when clockspeeds are held equal. Both of them have the same ILP dependency, so both need to be able to pull off some FP32 co-issued instructions if they are to achieve their full 384 FLOP/cycle throughput. The A4-1350 on the other hand has no such limitation, making it easier to hit its 256 FLOP/cycle throughput, but never getting the chance to go past it.
Meanwhile it was surprising to see that GX6650’s theoretical pixel throughput was so high. 12 pixels/clock (12 ROPs) is much higher than either K1 or A4-1350, and in fact is quite high for an SoC class product. Most designs use relatively few ROPs here for size and power reasons, and not all designs replicate the ROPs with the shader blocks. So having 12 ROPs here was unexpected. At the same time it remains to be seen how well real world efficiency tracks this, as ROPs are frequently memory bandwidth constrained, which makes such a large number of ROPs harder to feed.
Moving on to quickly compare texture throughput, again it’s surprising to see just how many texels GX6650 can push. TMUs regularly scale with shader core counts, so the fact that it’s three-fold what a single TMU design can do is not unexpected, but until now we had never realized just what that meant for overall texture throughput. 12 texels/clock is (thankfully) a lot of texels for a SoC GPU. That said, this is also a memory bandwidth heavy operation, so it’s difficult to say how real world performance will track it.
Finally, to throw in a true desktop comparison for the fun of it, we also put NVIDIA’s Kepler based GTX 650 in the chart. Clockspeeds aside, the best case scenario for even GX6650 is that it achieves half the shading throughput as GTX 650. The ROP throughput gap on the other hand is narrower (but GTX 650 will easily have 2x the memory bandwidth) and the texture throughput gap is nearly 3x wider. In practice it would be difficult to imagine the GX6650 being any closer than about 40% of the GTX 650’s performance, once again owing to the massive memory bandwidth difference between an SoC and a discrete GPU.
Final Words
Wrapping up this architectural overview of Imagination’s Rogue architecture, it’s exciting to finally see much of the underpinnings of an SoC GPU design. While we haven’t seen every facet of Rogue yet – and admittedly it’s unlikely we ever will – the information that we’ve received on Rogue so far has given us a much better perspective on how Imagination’s latest graphics architecture works, and for that matter how Series 6 and Series 6XT differ from one-another.
Ultimately we still can’t do true apples-to-apples comparisons with these integrated GPUs (we can’t separate the CPU and memory controller from the GPU), but it should be helpful for better understanding why certain products perform the way they do, and determining what the stronger products might be in the long run. So it’s with some hope and a bit of luck that this might get the ball rolling with the other SoC GPU vendors, getting them to open up their doors a bit more so that we can see what’s inside their designs.
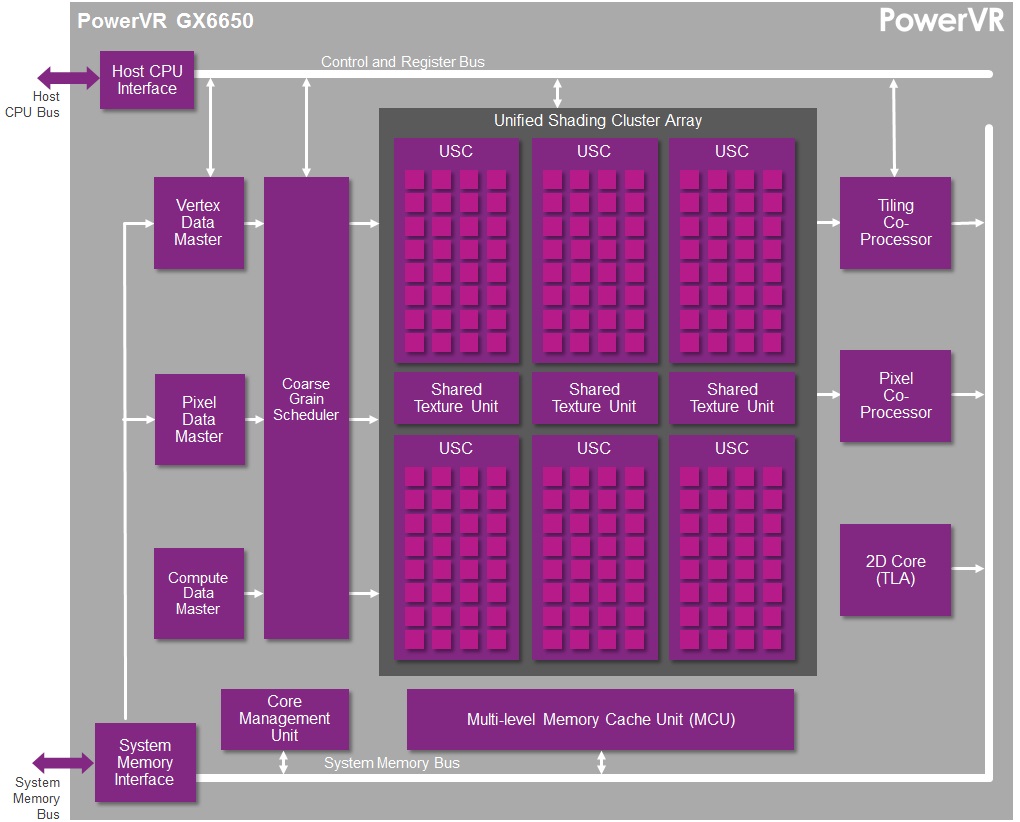
Coming back full circle to Imagination, we’re left with one of the big reasons why they’re opening up in the first place: core wars. Imagination is keen on not being seen as being left behind on core counts, and while we don’t expect the “core” terminology to go away any time soon, now that we have these low level Rogue architecture details, we can agree that Imagination does have a salient point as far as counting cores and ALUs is concerned.
For the purposes of FP32 operations a Rogue USC is essentially equivalent to a 32 core design, with an ILP reliance similar to what we’re seeing out of NVIDIA right now, though perhaps greater than some other designs. Or as Imagination likes to compare it to, a 6 USC design would be equivalent to a 192 core design. This speaks nothing of real world performance – without real world hardware it can’t, there are too many external variables – but it does give us an idea of how many clusters Imagination’s customers would need to achieve various degrees of theoretical performance, including what it would take to beat the competition.








95 Comments
View All Comments
vladz - Monday, February 24, 2014 - link
So what does flexible hardware or flexible rendering mean exactly?Ryan Smith - Monday, February 24, 2014 - link
Flexible hardware in the context I used it would mean programmable.TMUs aren't flexible. They fetch texels, apply filtering, and that's it.
Shaders are flexible. They accept threads of instructions and the result on a pixel/vertex will be whatever the program dictates, as opposed to a fixed outcome.
ifrit39 - Monday, February 24, 2014 - link
I believe your math is off on the last table. GTX 650 would produce 230.4 GFLOPS @ 300MHz, not 330.4.Its interesting to me that these mobile designs are so close to full desktop performance (albeit with the low 300MHz clock). But memory bandwidth, power, and clocks will always hold these SoCs back in the real world.
Thanks for the great article, as always.
hoboville - Monday, February 24, 2014 - link
I love these kinds of articles, simply because of the explanations of how various hardware and underlying systems work. Probably the best part of Anandtech reviews.Laststop311 - Tuesday, February 25, 2014 - link
Gotta give imagination tech some credit. They have the highest performing gpu's in the soc market. Very flexible too, they make a 2 core cluster , 3 core, 4 core and 6 core. If only we could have the best cpu performance (qualcomm snapdragon krait cpu's) mixed with the best gpu (powervr 6xt 6 core version) on the same soc. Tho nvidia dual core denver design that throws away all the extra cores and devotes more die space to 2 higher performing more complex cores might take the cpu crown since there arent many workloads on a phone that needs more then 2 threads going.nosirrah123 - Tuesday, February 25, 2014 - link
Wow, this is an amazingly written article, good work!patrickjchase - Tuesday, February 25, 2014 - link
Are you sure that Rogue is superscalar rather than VLIW?Briefly the difference between the two comes down to when independent instructions (ones that can execute in parallel) are identified. In a VLIW it happens at compile time, while in a superscalar design it happens at runtime. It would actually surprise me if Rogue does runtime dependency analysis for such a wide backend - If I had to bet I'd say "VLIW".
D16700605001 - Wednesday, February 26, 2014 - link
is there a similar article comparing Nvidia to AMD? I've seen block diagrams of Nvidia chips on their web site but haven't found any for AMD. Even if I did, an article like this one would be better than me trying to make inferences and decode the vendor spin. I want to buy a compute engine and I keep getting the impression AMDs offering is better but would like to be convinced from a technical discussion rather than stats about game performance and unpacking textures.Bawl - Saturday, March 1, 2014 - link
Great article. Thank you so much. PowerVR has so much power inside, I can only think their power are underutilized because of the others GPUs.MrSpadge - Saturday, March 1, 2014 - link
I wonder how many instructions they can dispatch per clock. That's a significant factor when discussing how to feed up to 7 execution units. Actually I'd be surprised if it's more than 2, maybe 3 under special circumstances.. which would make me wonder how they're feeding 4 FP16 ALUs. But then I also wonder if these are truly 4 independebt units.. I guess not.