Imagination's PowerVR Rogue Architecture Explored
by Ryan Smith on February 24, 2014 3:00 AM EST- Posted in
- GPUs
- Imagination Technologies
- PowerVR
- PowerVR Series6
- SoCs
How Rogues Get Executed: Wavefronts & Superscalar ILP
Now that we’ve seen the basic makeup of a single Rogue pipeline, let’s expand our view to the wider USC.
A single Rogue USC is comprised of 16 pipelines, making the design a 16 wide array. This, along with a texture unit, comprises one “cluster” when we’re talking about a multi-cluster (multiple USC) Rogue setup. In a setup with multiple USCs, the texture unit will then be shared among a pair of USCs.
We don’t have a great deal of information on the texture units themselves, but we do know that a Rogue texture unit can fetch 4 32bit bilinear texels per clock. So for a top-end 6 USC part, we’d be looking at a texture rate of 12 texels/clock.
Now by PC standards the Rogue pipeline/USC setup is a bit unusual due to its width. Both AMD and NVIDIA’s architectures are fairly narrow at this level, possessing just a small number of ALUs per shader core/pipeline. The impact of this is that by having multiple ALUs per pipeline in Rogue’s case, there is a need to extract some degree of instruction level parallelism (ILP) out of threads to feed as many ALUs as possible. Extracting ILP in turn requires having instructions in a single thread that have no dependencies on each other that can be executed in parallel. This can be many (but not all) instructions, so it’s worth noting that the efficiency of a USC is going to depend in part on the instructions in a thread. We call this property a superscalar design.
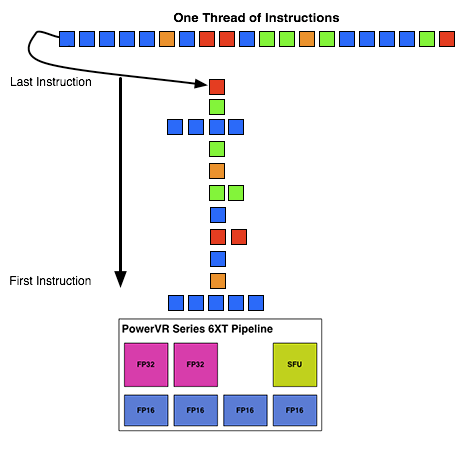
For the sake of comparison, AMD’s Graphics Core Next is not a superscalar design at all, while NVIDIA’s Kepler is superscalar in a similar manner. NVIDIA’s CUDA cores only have 1 FP32 ALU per core, but there are additional banks of CUDA cores that can be co-issued additional instructions, conditions permitting. So Rogue has a similar reliance on ILP within a thread, needing it to achieve maximum efficiency.
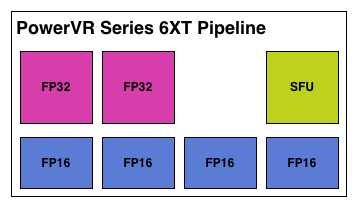
What makes Rogue all the more interesting is just how wide it is. For FP32 operations it’s only 2-wide, but if we throw in the FP16 operations we’re technically looking at a 6-wide design. The odds of having FP16 and FP32 operations ready to co-issue in such a manner is far rarer than having just a pair of FP32 instructions to co-issue, so again Rogue technically is very unlikely to achieve 100% utilization of a pipeline.
That said, the split between FP16 and FP32 units makes it clear that Imagination expects to be using one or the other most of the time rather than both, so as far as the design goes this is not unexpected. For FP32 instructions then it’s a simpler 2-wide setup, while FP16 instructions are going to be trickier as full utilization of FP16 is going to require a full 4 instruction setup (say 4 MADs following each other). The fact that Series 6XT has 4 FP16 units despite that is interesting, as it implies that it was worth the extra die space compared to the Series 6 setup of 2 FP16 units.
With that out of the way, let’s talk about how work is dispatched to the pipelines within a USC. Each pipeline works on one thread at a time, the same as any other modern GPU architecture. Consequently we’d expect the wavefront size to be 16 threads.
However there’s an interesting fact that we found out about the USCs, and that is that they don’t run at the same clockspeed throughout. The ALUs themselves run at the published clockspeed for the GPU, but the frontends that feed them – the decoders and operand collectors do not. Imagination has not specified at what rate they run at, but the only thing that makes sense is ½ the rate of the ALUs. So a 300MHz USC would have its decoder frontend running at 150MHz, etc.
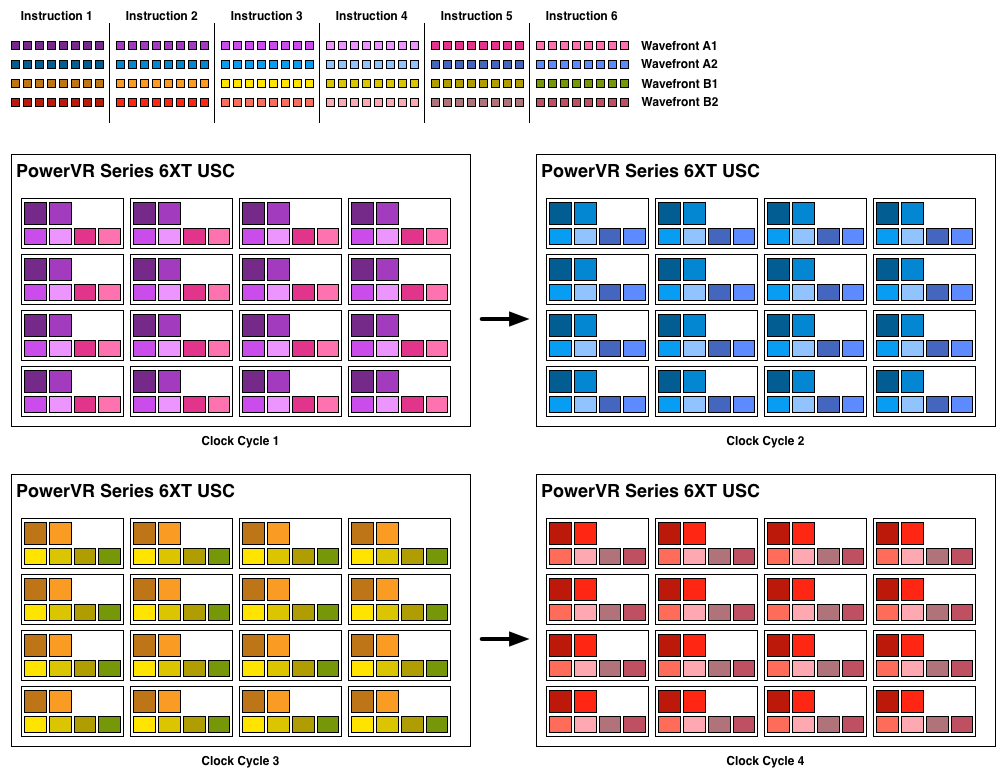
An example of a wavefront executing. Instructions per thread not to scale
Consequently we believe that the size of a wavefront is not 16 threads, but rather 32 threads, executed over 2 cycles of the ALUs. This is not the first time we’ve seen this design – NVIDIA did something similar for their retired Fermi architecture – but this isn’t something we were expecting to see again. But with the idiosyncrasies of the SoC space, this is apparently something that still makes sense. Imagination did tell us that there are tangible power savings from doing this, and since SoC GPUs are power limited in most cases anyhow, this is essentially the higher performance option. Go faster by going slower.
Finally, this brings us to the highest level, the USC array. Each USC in an array receives its own thread to work on, so the number of threads actively being executed will be identical to the number of USCs in a design. For a high-end 6 module design, we’d be looking at 6 threads, whereas for a smaller 2 module design it would be just 2 threads.








95 Comments
View All Comments
jjj - Monday, February 24, 2014 - link
Far from ideal timing with so many news around, guess i'll have to read it after MWC.rpg1966 - Monday, February 24, 2014 - link
Thank you for sharing.Mondozai - Monday, February 24, 2014 - link
The most important part is what Anand highlighted from this walkthrough; namely that the Rogue series has a chip that is on equal balance if not even stronger than Tegra K1.Poor Nvidia.
Sabresiberian - Monday, February 24, 2014 - link
That remains to be seen - but it does appear to be competitive at this point. We also don't know what the entire Denver+K1 package will do.What kind of surprises me about K1 though is that Maxwell has already been released for the desktop. I would think "M1" (to guess at a name) would be the architecture to build on in the next year.
dragonsqrrl - Monday, February 24, 2014 - link
Uhhh no it doesn't. The article failed to mention this important piece of information, but you realize the 6XT series probably won't come to market before 2015 right? Likely 2H 2015 according to an earlier article published here on Anandtech.grahaman27 - Monday, February 24, 2014 - link
Interesting. Which article mentioned that? Would you mind linking me to it?I can't find an expected release date for this chip anywhere.
dragonsqrrl - Tuesday, February 25, 2014 - link
That's because there is none. It was an estimate given by Ryan Smith based on prior Imagination GPU announcements, and the time it usually takes chipmakers to integrate the design and bring a device to market."Finally, while Imagination doesn’t provide a timeframe for consumer availability (since they only sell designs to chipmakers), based on the amount of time needed to integrate these designs into new products and then get those products in the hands of consumers, we should be looking at a timetable similar to the original Series6 designs. In which case Series6XT equipped SoCs would start appearing in 2015, likely in the latter half."
http://www.anandtech.com/show/7629/imagination-tec...
michael2k - Tuesday, February 25, 2014 - link
Really? You don't think their biggest customer, Apple, which has shown the ability to beat an entire industry to market by almost a year (64 bit ARMv8) and one of the first PVR6 customers to market as well? Anand though it would be 2014 when PVR6 would show up to market, and the A9600 that was supposed to show up in 2013 never did (Apple's A7 did though!)So why do you rule out the real possibility that the Apple A8 would ship with a 6XT this year?
dragonsqrrl - Tuesday, February 25, 2014 - link
I don't know, ask Ryan Smith.My theory for the ~18 month estimate is that it's about how long Apple took to integrate and bring their current series 6 GPU to market in the A7. I suppose if any company had the resources to accelerate that schedule, it would be Apple. But then the question becomes why and does it make sense? There will be faster Series 6 SKU's available for the A8 in the interim.
stingerman - Wednesday, February 26, 2014 - link
But don't forget, Apple has been involved in this design long before Imagination's public reveal. In fact, Apple informed Imaginations design with their real world experience and their own needs. I always expect Apple to get a 6 to 12 month lead. And, Apple has shown themselves to put a very high value on their SoC GPU leadership.