Imagination's PowerVR Rogue Architecture Explored
by Ryan Smith on February 24, 2014 3:00 AM EST- Posted in
- GPUs
- Imagination Technologies
- PowerVR
- PowerVR Series6
- SoCs
How Rogues Get Executed: Wavefronts & Superscalar ILP
Now that we’ve seen the basic makeup of a single Rogue pipeline, let’s expand our view to the wider USC.
A single Rogue USC is comprised of 16 pipelines, making the design a 16 wide array. This, along with a texture unit, comprises one “cluster” when we’re talking about a multi-cluster (multiple USC) Rogue setup. In a setup with multiple USCs, the texture unit will then be shared among a pair of USCs.
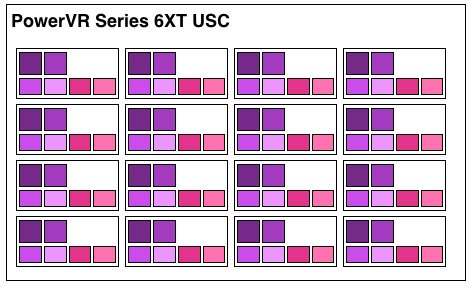
We don’t have a great deal of information on the texture units themselves, but we do know that a Rogue texture unit can fetch 4 32bit bilinear texels per clock. So for a top-end 6 USC part, we’d be looking at a texture rate of 12 texels/clock.
Now by PC standards the Rogue pipeline/USC setup is a bit unusual due to its width. Both AMD and NVIDIA’s architectures are fairly narrow at this level, possessing just a small number of ALUs per shader core/pipeline. The impact of this is that by having multiple ALUs per pipeline in Rogue’s case, there is a need to extract some degree of instruction level parallelism (ILP) out of threads to feed as many ALUs as possible. Extracting ILP in turn requires having instructions in a single thread that have no dependencies on each other that can be executed in parallel. This can be many (but not all) instructions, so it’s worth noting that the efficiency of a USC is going to depend in part on the instructions in a thread. We call this property a superscalar design.
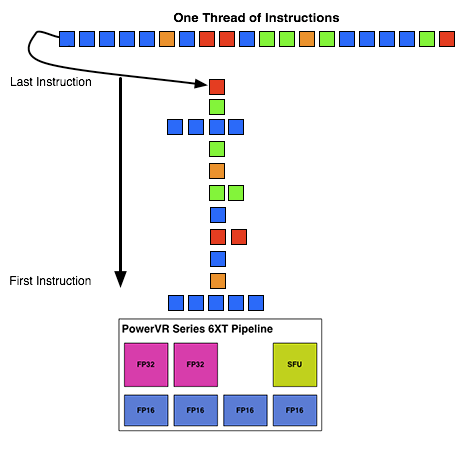
For the sake of comparison, AMD’s Graphics Core Next is not a superscalar design at all, while NVIDIA’s Kepler is superscalar in a similar manner. NVIDIA’s CUDA cores only have 1 FP32 ALU per core, but there are additional banks of CUDA cores that can be co-issued additional instructions, conditions permitting. So Rogue has a similar reliance on ILP within a thread, needing it to achieve maximum efficiency.
What makes Rogue all the more interesting is just how wide it is. For FP32 operations it’s only 2-wide, but if we throw in the FP16 operations we’re technically looking at a 6-wide design. The odds of having FP16 and FP32 operations ready to co-issue in such a manner is far rarer than having just a pair of FP32 instructions to co-issue, so again Rogue technically is very unlikely to achieve 100% utilization of a pipeline.
That said, the split between FP16 and FP32 units makes it clear that Imagination expects to be using one or the other most of the time rather than both, so as far as the design goes this is not unexpected. For FP32 instructions then it’s a simpler 2-wide setup, while FP16 instructions are going to be trickier as full utilization of FP16 is going to require a full 4 instruction setup (say 4 MADs following each other). The fact that Series 6XT has 4 FP16 units despite that is interesting, as it implies that it was worth the extra die space compared to the Series 6 setup of 2 FP16 units.
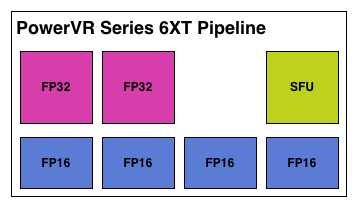
With that out of the way, let’s talk about how work is dispatched to the pipelines within a USC. Each pipeline works on one thread at a time, the same as any other modern GPU architecture. Consequently we’d expect the wavefront size to be 16 threads.
However there’s an interesting fact that we found out about the USCs, and that is that they don’t run at the same clockspeed throughout. The ALUs themselves run at the published clockspeed for the GPU, but the frontends that feed them – the decoders and operand collectors do not. Imagination has not specified at what rate they run at, but the only thing that makes sense is ½ the rate of the ALUs. So a 300MHz USC would have its decoder frontend running at 150MHz, etc.
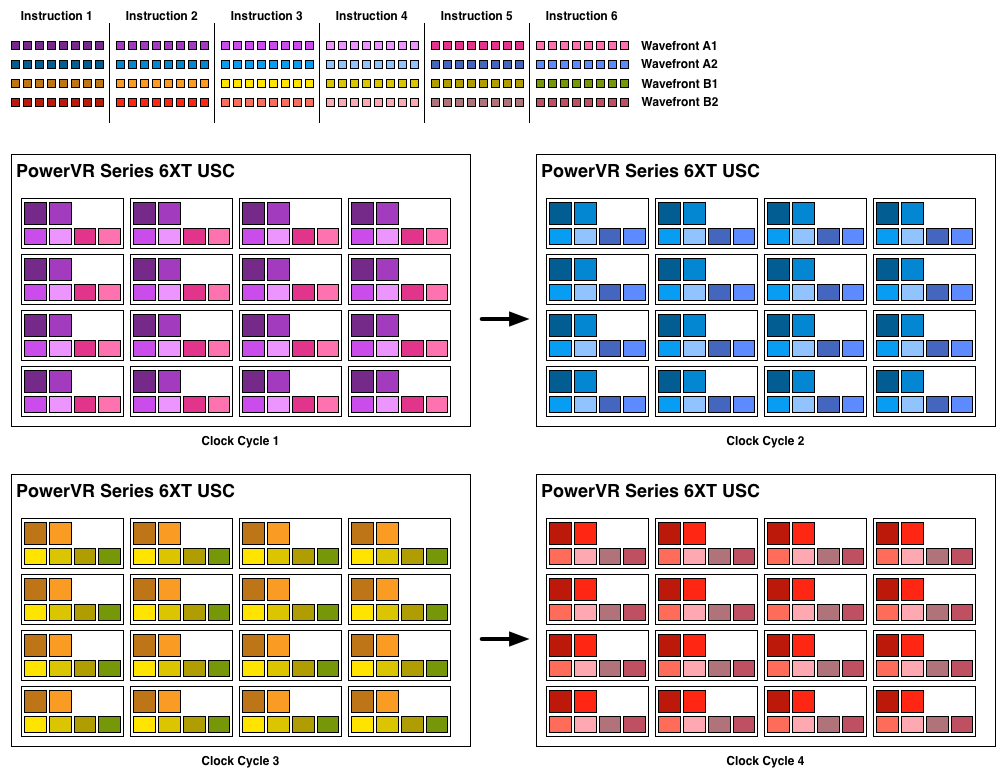
An example of a wavefront executing. Instructions per thread not to scale
Consequently we believe that the size of a wavefront is not 16 threads, but rather 32 threads, executed over 2 cycles of the ALUs. This is not the first time we’ve seen this design – NVIDIA did something similar for their retired Fermi architecture – but this isn’t something we were expecting to see again. But with the idiosyncrasies of the SoC space, this is apparently something that still makes sense. Imagination did tell us that there are tangible power savings from doing this, and since SoC GPUs are power limited in most cases anyhow, this is essentially the higher performance option. Go faster by going slower.
Finally, this brings us to the highest level, the USC array. Each USC in an array receives its own thread to work on, so the number of threads actively being executed will be identical to the number of USCs in a design. For a high-end 6 module design, we’d be looking at 6 threads, whereas for a smaller 2 module design it would be just 2 threads.








95 Comments
View All Comments
vladz - Monday, February 24, 2014 - link
So what does flexible hardware or flexible rendering mean exactly?Ryan Smith - Monday, February 24, 2014 - link
Flexible hardware in the context I used it would mean programmable.TMUs aren't flexible. They fetch texels, apply filtering, and that's it.
Shaders are flexible. They accept threads of instructions and the result on a pixel/vertex will be whatever the program dictates, as opposed to a fixed outcome.
ifrit39 - Monday, February 24, 2014 - link
I believe your math is off on the last table. GTX 650 would produce 230.4 GFLOPS @ 300MHz, not 330.4.Its interesting to me that these mobile designs are so close to full desktop performance (albeit with the low 300MHz clock). But memory bandwidth, power, and clocks will always hold these SoCs back in the real world.
Thanks for the great article, as always.
hoboville - Monday, February 24, 2014 - link
I love these kinds of articles, simply because of the explanations of how various hardware and underlying systems work. Probably the best part of Anandtech reviews.Laststop311 - Tuesday, February 25, 2014 - link
Gotta give imagination tech some credit. They have the highest performing gpu's in the soc market. Very flexible too, they make a 2 core cluster , 3 core, 4 core and 6 core. If only we could have the best cpu performance (qualcomm snapdragon krait cpu's) mixed with the best gpu (powervr 6xt 6 core version) on the same soc. Tho nvidia dual core denver design that throws away all the extra cores and devotes more die space to 2 higher performing more complex cores might take the cpu crown since there arent many workloads on a phone that needs more then 2 threads going.nosirrah123 - Tuesday, February 25, 2014 - link
Wow, this is an amazingly written article, good work!patrickjchase - Tuesday, February 25, 2014 - link
Are you sure that Rogue is superscalar rather than VLIW?Briefly the difference between the two comes down to when independent instructions (ones that can execute in parallel) are identified. In a VLIW it happens at compile time, while in a superscalar design it happens at runtime. It would actually surprise me if Rogue does runtime dependency analysis for such a wide backend - If I had to bet I'd say "VLIW".
D16700605001 - Wednesday, February 26, 2014 - link
is there a similar article comparing Nvidia to AMD? I've seen block diagrams of Nvidia chips on their web site but haven't found any for AMD. Even if I did, an article like this one would be better than me trying to make inferences and decode the vendor spin. I want to buy a compute engine and I keep getting the impression AMDs offering is better but would like to be convinced from a technical discussion rather than stats about game performance and unpacking textures.Bawl - Saturday, March 1, 2014 - link
Great article. Thank you so much. PowerVR has so much power inside, I can only think their power are underutilized because of the others GPUs.MrSpadge - Saturday, March 1, 2014 - link
I wonder how many instructions they can dispatch per clock. That's a significant factor when discussing how to feed up to 7 execution units. Actually I'd be surprised if it's more than 2, maybe 3 under special circumstances.. which would make me wonder how they're feeding 4 FP16 ALUs. But then I also wonder if these are truly 4 independebt units.. I guess not.