Imagination's PowerVR Rogue Architecture Explored
by Ryan Smith on February 24, 2014 3:00 AM EST- Posted in
- GPUs
- Imagination Technologies
- PowerVR
- PowerVR Series6
- SoCs
How Rogues Get Executed: Wavefronts & Superscalar ILP
Now that we’ve seen the basic makeup of a single Rogue pipeline, let’s expand our view to the wider USC.
A single Rogue USC is comprised of 16 pipelines, making the design a 16 wide array. This, along with a texture unit, comprises one “cluster” when we’re talking about a multi-cluster (multiple USC) Rogue setup. In a setup with multiple USCs, the texture unit will then be shared among a pair of USCs.
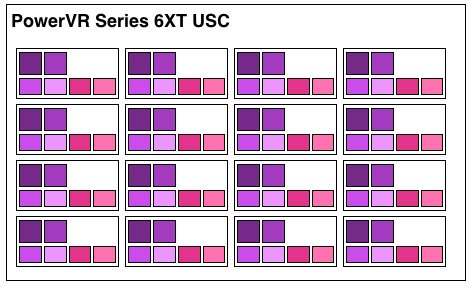
We don’t have a great deal of information on the texture units themselves, but we do know that a Rogue texture unit can fetch 4 32bit bilinear texels per clock. So for a top-end 6 USC part, we’d be looking at a texture rate of 12 texels/clock.
Now by PC standards the Rogue pipeline/USC setup is a bit unusual due to its width. Both AMD and NVIDIA’s architectures are fairly narrow at this level, possessing just a small number of ALUs per shader core/pipeline. The impact of this is that by having multiple ALUs per pipeline in Rogue’s case, there is a need to extract some degree of instruction level parallelism (ILP) out of threads to feed as many ALUs as possible. Extracting ILP in turn requires having instructions in a single thread that have no dependencies on each other that can be executed in parallel. This can be many (but not all) instructions, so it’s worth noting that the efficiency of a USC is going to depend in part on the instructions in a thread. We call this property a superscalar design.
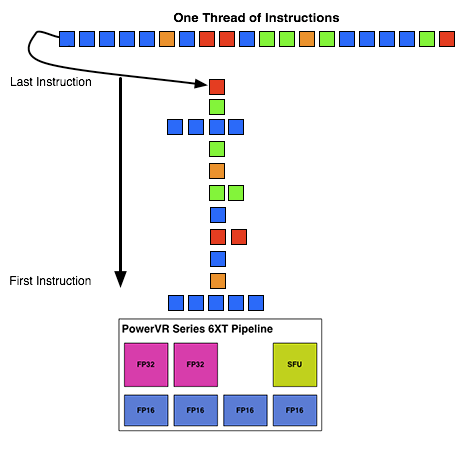
For the sake of comparison, AMD’s Graphics Core Next is not a superscalar design at all, while NVIDIA’s Kepler is superscalar in a similar manner. NVIDIA’s CUDA cores only have 1 FP32 ALU per core, but there are additional banks of CUDA cores that can be co-issued additional instructions, conditions permitting. So Rogue has a similar reliance on ILP within a thread, needing it to achieve maximum efficiency.
What makes Rogue all the more interesting is just how wide it is. For FP32 operations it’s only 2-wide, but if we throw in the FP16 operations we’re technically looking at a 6-wide design. The odds of having FP16 and FP32 operations ready to co-issue in such a manner is far rarer than having just a pair of FP32 instructions to co-issue, so again Rogue technically is very unlikely to achieve 100% utilization of a pipeline.
That said, the split between FP16 and FP32 units makes it clear that Imagination expects to be using one or the other most of the time rather than both, so as far as the design goes this is not unexpected. For FP32 instructions then it’s a simpler 2-wide setup, while FP16 instructions are going to be trickier as full utilization of FP16 is going to require a full 4 instruction setup (say 4 MADs following each other). The fact that Series 6XT has 4 FP16 units despite that is interesting, as it implies that it was worth the extra die space compared to the Series 6 setup of 2 FP16 units.
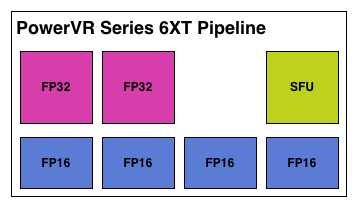
With that out of the way, let’s talk about how work is dispatched to the pipelines within a USC. Each pipeline works on one thread at a time, the same as any other modern GPU architecture. Consequently we’d expect the wavefront size to be 16 threads.
However there’s an interesting fact that we found out about the USCs, and that is that they don’t run at the same clockspeed throughout. The ALUs themselves run at the published clockspeed for the GPU, but the frontends that feed them – the decoders and operand collectors do not. Imagination has not specified at what rate they run at, but the only thing that makes sense is ½ the rate of the ALUs. So a 300MHz USC would have its decoder frontend running at 150MHz, etc.
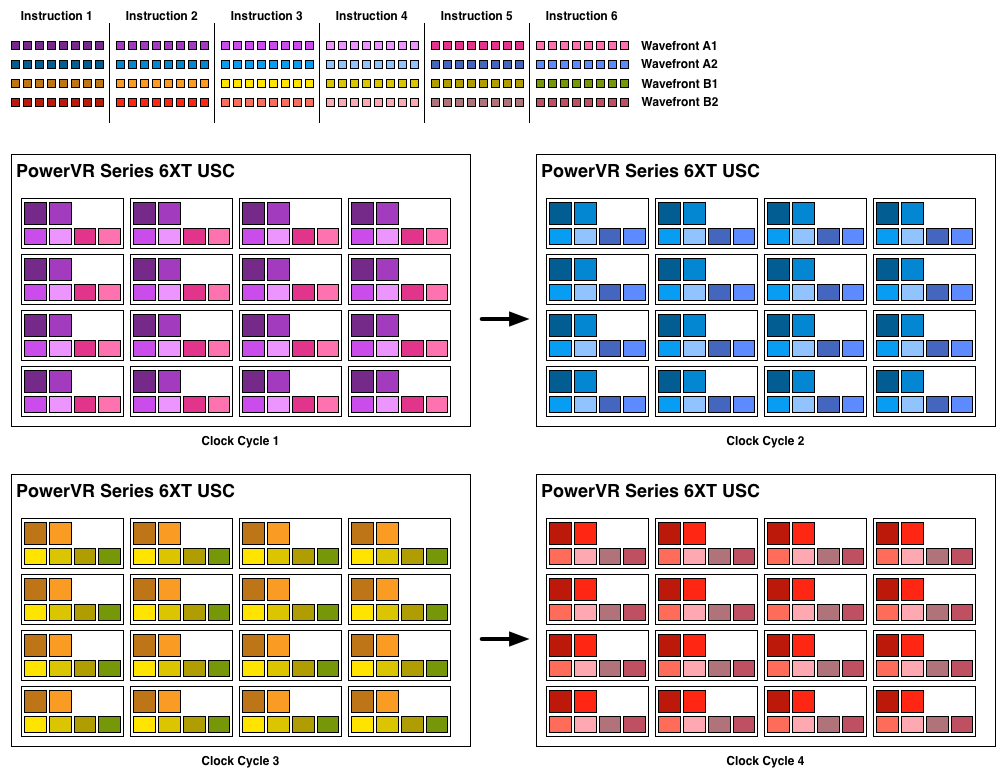
An example of a wavefront executing. Instructions per thread not to scale
Consequently we believe that the size of a wavefront is not 16 threads, but rather 32 threads, executed over 2 cycles of the ALUs. This is not the first time we’ve seen this design – NVIDIA did something similar for their retired Fermi architecture – but this isn’t something we were expecting to see again. But with the idiosyncrasies of the SoC space, this is apparently something that still makes sense. Imagination did tell us that there are tangible power savings from doing this, and since SoC GPUs are power limited in most cases anyhow, this is essentially the higher performance option. Go faster by going slower.
Finally, this brings us to the highest level, the USC array. Each USC in an array receives its own thread to work on, so the number of threads actively being executed will be identical to the number of USCs in a design. For a high-end 6 module design, we’d be looking at 6 threads, whereas for a smaller 2 module design it would be just 2 threads.








95 Comments
View All Comments
MrPoletski - Sunday, March 9, 2014 - link
Factor of 4X, where is the edit button?iwod - Monday, February 24, 2014 - link
So that is a pretty decent GPU even from Desktop perspective. But Why we dont see this being used on Laptop or Desktop? It doesn't seem hard to scale the Imagination PVR GX6650 to NVIDIA GTX 650 level.StevoLincolnite - Monday, February 24, 2014 - link
Imagination used to build graphics processors for the Desktop, they were unable to compete with ATI, nVidia, Matrox, S3, 3dfx, NEC etc'. - Instead they shifted their focus to a niche market, the low-powered market, if only the other players knew how big that market would eventually grow to.Intel has also used PowerVR graphics chips for it's IGP's in the past like the GMA 3600 in the Intel Atom.
In general, they are far from ideal, they leave much to be desired in the drivers department.
One of the earlier PowerVR chips in the Intel Atom still doesn't have it's decoder functioning.
Krysto - Monday, February 24, 2014 - link
Imagination is losing the war for the exact same reason they lost the last time - their tile-based rendering, that was only meant for low-end "embedded" chips. But the chips are becoming "desktop class" these days, and need to work on a lot more advanced content with super high resolutions - and that's why Imagination's tile-based rendering will fail. Tile-based rendering is meant for simple operations, and that's where it shows its greater efficiency. The more complex those operations (the games) get the harder it will be for the PowerVR architecture to keep up.It used to be that their competitors couldn't even touch them. Now every single one will match or exceed their performance and features, and I imagine next year's 16nm FinFET Mobile Maxwell will leave it in the dust (wouldn't surprise me to see higher performance than Xbox One in it, or at least 1 TF).
michael2k - Monday, February 24, 2014 - link
You mean Imagination is still winning the war because everyone else only just realized there was a market in SoC? Intel is only barely in the game, AMD isn't, and Mali and Adreno is the only real competitor in terms of unit share. Unlike GPU, this market is tied to the success of your SoC, and PVR has a strong ally in Apple unless NVIDIA can convince Apple to license some of their GPU tech.Apple ships something like 1 in 5 smartphones, 1 in 2 tablets, etc. They have a huge presence in the market right now. Qualcomm definitely ships more SoC, but their GPUs don't all sit in the high end performance space.
ryszu - Monday, February 24, 2014 - link
Our TBDR front-end is absolutely not just designed for simple operations. Pure FUD, it scales very well.Scali - Monday, February 24, 2014 - link
How do you figure that TBDR is only for simple operations? It actually excels at more complex pixel operations, because it defers most of the shading and texturing until after visibility has been solved.khanov - Monday, February 24, 2014 - link
Pure nonsense. Go back to the kiddy table.Tile-Based Deferred Rendering eliminates overdraw and the performance gains it achieves INCREASE with scene complexity.
phoenix_rizzen - Friday, February 28, 2014 - link
Haven't you been saying the same thing for the past two years with the release of Tegra3 and Tegra4? And nVidia is still way behind.Series 6 is out now in products you can actually buy. Tegra K1 isn't.
Series 6 XT will be out in the next year-ish. Tegra K1 will probably be out by then.
The follow-up to 6XT will probably be out in two years. Who knows when the next Tegra after K1 will actually be out?
Until there's actual, physical devices out there with an nVidia chipset in it that betters the other, actual, physical devices out there, you're just barking smoke.
MrPoletski - Sunday, March 9, 2014 - link
You are completely wrong!