Imagination's PowerVR Rogue Architecture Explored
by Ryan Smith on February 24, 2014 3:00 AM EST- Posted in
- GPUs
- Imagination Technologies
- PowerVR
- PowerVR Series6
- SoCs
How Rogues Get Executed: Wavefronts & Superscalar ILP
Now that we’ve seen the basic makeup of a single Rogue pipeline, let’s expand our view to the wider USC.
A single Rogue USC is comprised of 16 pipelines, making the design a 16 wide array. This, along with a texture unit, comprises one “cluster” when we’re talking about a multi-cluster (multiple USC) Rogue setup. In a setup with multiple USCs, the texture unit will then be shared among a pair of USCs.
We don’t have a great deal of information on the texture units themselves, but we do know that a Rogue texture unit can fetch 4 32bit bilinear texels per clock. So for a top-end 6 USC part, we’d be looking at a texture rate of 12 texels/clock.
Now by PC standards the Rogue pipeline/USC setup is a bit unusual due to its width. Both AMD and NVIDIA’s architectures are fairly narrow at this level, possessing just a small number of ALUs per shader core/pipeline. The impact of this is that by having multiple ALUs per pipeline in Rogue’s case, there is a need to extract some degree of instruction level parallelism (ILP) out of threads to feed as many ALUs as possible. Extracting ILP in turn requires having instructions in a single thread that have no dependencies on each other that can be executed in parallel. This can be many (but not all) instructions, so it’s worth noting that the efficiency of a USC is going to depend in part on the instructions in a thread. We call this property a superscalar design.
For the sake of comparison, AMD’s Graphics Core Next is not a superscalar design at all, while NVIDIA’s Kepler is superscalar in a similar manner. NVIDIA’s CUDA cores only have 1 FP32 ALU per core, but there are additional banks of CUDA cores that can be co-issued additional instructions, conditions permitting. So Rogue has a similar reliance on ILP within a thread, needing it to achieve maximum efficiency.
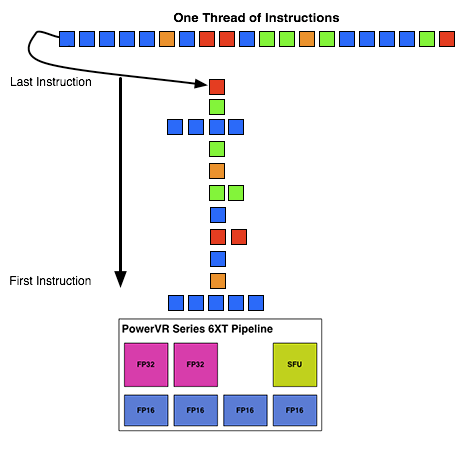
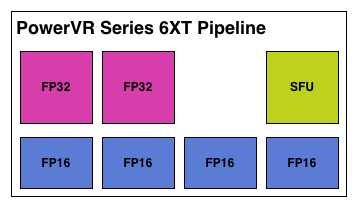
What makes Rogue all the more interesting is just how wide it is. For FP32 operations it’s only 2-wide, but if we throw in the FP16 operations we’re technically looking at a 6-wide design. The odds of having FP16 and FP32 operations ready to co-issue in such a manner is far rarer than having just a pair of FP32 instructions to co-issue, so again Rogue technically is very unlikely to achieve 100% utilization of a pipeline.
That said, the split between FP16 and FP32 units makes it clear that Imagination expects to be using one or the other most of the time rather than both, so as far as the design goes this is not unexpected. For FP32 instructions then it’s a simpler 2-wide setup, while FP16 instructions are going to be trickier as full utilization of FP16 is going to require a full 4 instruction setup (say 4 MADs following each other). The fact that Series 6XT has 4 FP16 units despite that is interesting, as it implies that it was worth the extra die space compared to the Series 6 setup of 2 FP16 units.
With that out of the way, let’s talk about how work is dispatched to the pipelines within a USC. Each pipeline works on one thread at a time, the same as any other modern GPU architecture. Consequently we’d expect the wavefront size to be 16 threads.
However there’s an interesting fact that we found out about the USCs, and that is that they don’t run at the same clockspeed throughout. The ALUs themselves run at the published clockspeed for the GPU, but the frontends that feed them – the decoders and operand collectors do not. Imagination has not specified at what rate they run at, but the only thing that makes sense is ½ the rate of the ALUs. So a 300MHz USC would have its decoder frontend running at 150MHz, etc.
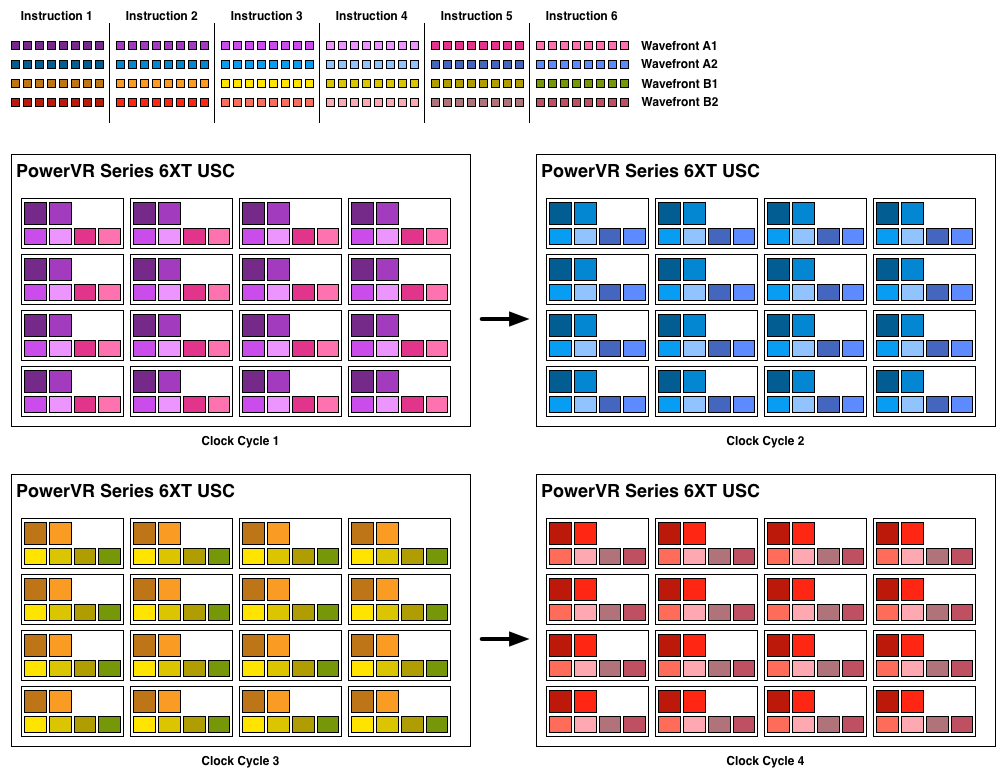
An example of a wavefront executing. Instructions per thread not to scale
Consequently we believe that the size of a wavefront is not 16 threads, but rather 32 threads, executed over 2 cycles of the ALUs. This is not the first time we’ve seen this design – NVIDIA did something similar for their retired Fermi architecture – but this isn’t something we were expecting to see again. But with the idiosyncrasies of the SoC space, this is apparently something that still makes sense. Imagination did tell us that there are tangible power savings from doing this, and since SoC GPUs are power limited in most cases anyhow, this is essentially the higher performance option. Go faster by going slower.
Finally, this brings us to the highest level, the USC array. Each USC in an array receives its own thread to work on, so the number of threads actively being executed will be identical to the number of USCs in a design. For a high-end 6 module design, we’d be looking at 6 threads, whereas for a smaller 2 module design it would be just 2 threads.








95 Comments
View All Comments
Sonicadvance1 - Tuesday, February 25, 2014 - link
Thanks for the response. Good to know. The article didn't really note anything about it.ryszu - Tuesday, February 25, 2014 - link
I misspoke actually, integer is a separate pipe in Rogue.Sonicadvance1 - Thursday, February 27, 2014 - link
Alright, then how much slower is Integer performance compared to floating point? Integer performance is an area that Nvidia struggles with as well.MrSpadge - Saturday, March 1, 2014 - link
This sounds different from any material Ryan showed or discussed. Could you elaborate, may directly to Ryan and have him update the article?Frenetic Pony - Monday, February 24, 2014 - link
I'm not sure what exactly is being babbled on about with tile based deferred rendering. It's just software, anyone can write and run it. Go onto a friendly GPU programming forum and they'll take you through it step by step.Scali - Monday, February 24, 2014 - link
Deferred rendering is a software solution. Tile-based deferred rendering is a hardware solution. The GPU cuts up the triangles in a set of tiles. Inside the GPU, there is a superfast 'framebuffer' the size of a tile (think of a special L1-cache). The GPU renders one tile at a time into this buffer, solving overdraw very quickly and efficiently, then it burst-writes the tile out to the framebuffer in videomemory. PowerVR has been using this technology since the early days of 3D acceleration (I have a PowerVR PCX2 card myself, and did a blog on it a while ago: http://scalibq.wordpress.com/2012/12/18/just-keepi...I suggest you read up on it, it is very interesting technology, and unlike any competing GPU.
Frenetic Pony - Monday, February 24, 2014 - link
No it isn't. Anyone with the proper feature set can do tile based deferred, most next gen games are going to be culling light lists out on something like an 8x8 pixel per tile basis, whether that's for forward rending or deferred. Which sounds exactly like what you described.It might be nice that there's some special little cache for it in PowerVr. But the basic idea as you've described it sounds exactly the same in principle as what DICE/EA's Frostbite does, as well as any number of other papers and games coming do.
Scali - Monday, February 24, 2014 - link
No, I don't think you quite get it. Culling lights in tiles is something different.In this case the geometry is batched up before drawing, then binned to tiles, and then the visibility (z-order) is solved on a per-tile basis.
It may sound the same as deferred rendering tricks in software, but it is not quite the same. These software tricks depend on multiple rendering passes, with z/stenciltesting to determine which pixels to shade. PowerVR can do it in a single pass (as far as the software is concerned).
Again, I suggest you read up on it.
Scali - Monday, February 24, 2014 - link
In fact, the PowerVR PCX2 card did not even need a z-buffer in videomemory at all. What "feature set" on a regular GPU would be able to render properly without a z-buffer?MrPoletski - Sunday, March 9, 2014 - link
Exactly, the Z-buffer is on chip. Incidentally, Multi-sampling AA increases your Z-buffer and framebuffer bandwidth requirements by a factor of x (for 4x AA). What if that were all on chip?I can't believe IMGTEC haven't made more noise about this.