Imagination's PowerVR Rogue Architecture Explored
by Ryan Smith on February 24, 2014 3:00 AM EST- Posted in
- GPUs
- Imagination Technologies
- PowerVR
- PowerVR Series6
- SoCs
How Rogues Get Executed: Wavefronts & Superscalar ILP
Now that we’ve seen the basic makeup of a single Rogue pipeline, let’s expand our view to the wider USC.
A single Rogue USC is comprised of 16 pipelines, making the design a 16 wide array. This, along with a texture unit, comprises one “cluster” when we’re talking about a multi-cluster (multiple USC) Rogue setup. In a setup with multiple USCs, the texture unit will then be shared among a pair of USCs.
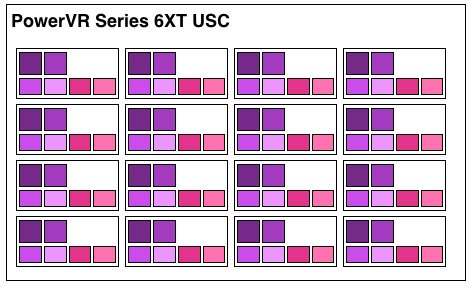
We don’t have a great deal of information on the texture units themselves, but we do know that a Rogue texture unit can fetch 4 32bit bilinear texels per clock. So for a top-end 6 USC part, we’d be looking at a texture rate of 12 texels/clock.
Now by PC standards the Rogue pipeline/USC setup is a bit unusual due to its width. Both AMD and NVIDIA’s architectures are fairly narrow at this level, possessing just a small number of ALUs per shader core/pipeline. The impact of this is that by having multiple ALUs per pipeline in Rogue’s case, there is a need to extract some degree of instruction level parallelism (ILP) out of threads to feed as many ALUs as possible. Extracting ILP in turn requires having instructions in a single thread that have no dependencies on each other that can be executed in parallel. This can be many (but not all) instructions, so it’s worth noting that the efficiency of a USC is going to depend in part on the instructions in a thread. We call this property a superscalar design.
For the sake of comparison, AMD’s Graphics Core Next is not a superscalar design at all, while NVIDIA’s Kepler is superscalar in a similar manner. NVIDIA’s CUDA cores only have 1 FP32 ALU per core, but there are additional banks of CUDA cores that can be co-issued additional instructions, conditions permitting. So Rogue has a similar reliance on ILP within a thread, needing it to achieve maximum efficiency.
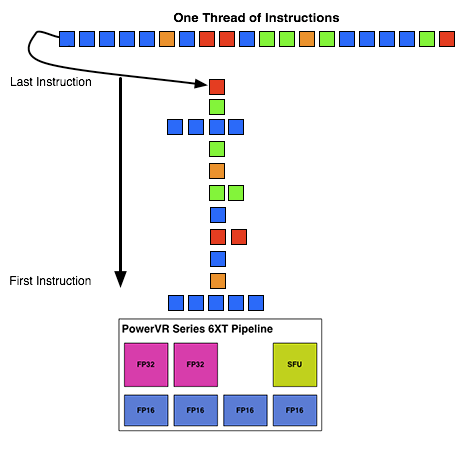
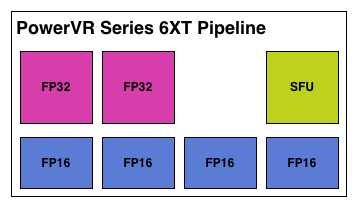
What makes Rogue all the more interesting is just how wide it is. For FP32 operations it’s only 2-wide, but if we throw in the FP16 operations we’re technically looking at a 6-wide design. The odds of having FP16 and FP32 operations ready to co-issue in such a manner is far rarer than having just a pair of FP32 instructions to co-issue, so again Rogue technically is very unlikely to achieve 100% utilization of a pipeline.
That said, the split between FP16 and FP32 units makes it clear that Imagination expects to be using one or the other most of the time rather than both, so as far as the design goes this is not unexpected. For FP32 instructions then it’s a simpler 2-wide setup, while FP16 instructions are going to be trickier as full utilization of FP16 is going to require a full 4 instruction setup (say 4 MADs following each other). The fact that Series 6XT has 4 FP16 units despite that is interesting, as it implies that it was worth the extra die space compared to the Series 6 setup of 2 FP16 units.
With that out of the way, let’s talk about how work is dispatched to the pipelines within a USC. Each pipeline works on one thread at a time, the same as any other modern GPU architecture. Consequently we’d expect the wavefront size to be 16 threads.
However there’s an interesting fact that we found out about the USCs, and that is that they don’t run at the same clockspeed throughout. The ALUs themselves run at the published clockspeed for the GPU, but the frontends that feed them – the decoders and operand collectors do not. Imagination has not specified at what rate they run at, but the only thing that makes sense is ½ the rate of the ALUs. So a 300MHz USC would have its decoder frontend running at 150MHz, etc.
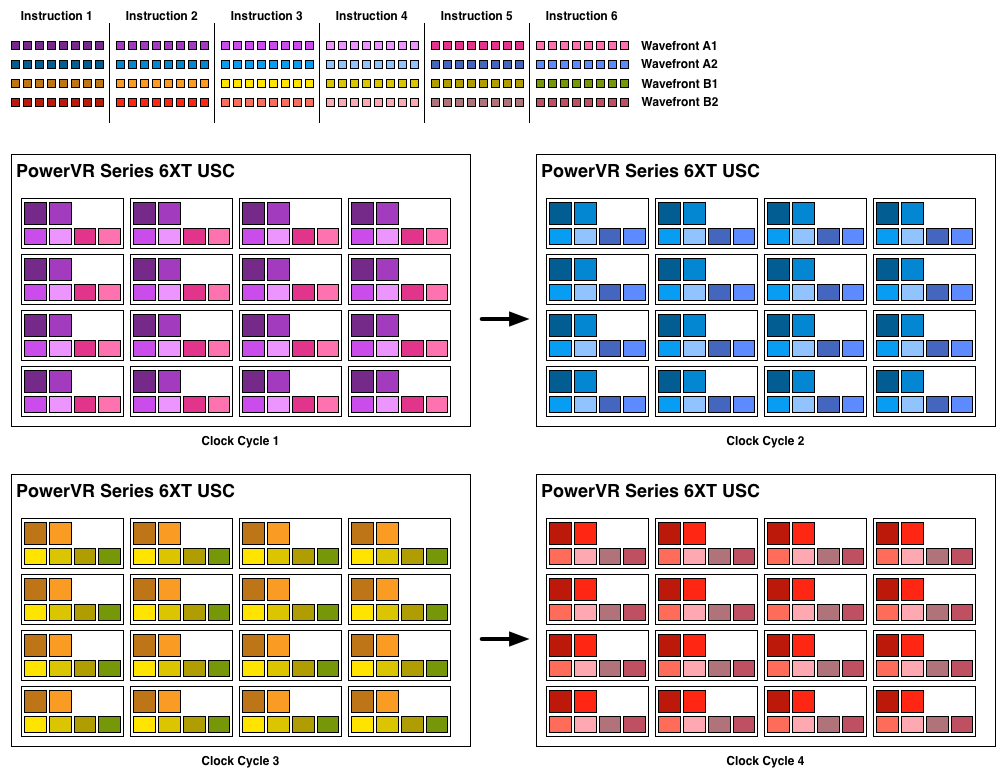
An example of a wavefront executing. Instructions per thread not to scale
Consequently we believe that the size of a wavefront is not 16 threads, but rather 32 threads, executed over 2 cycles of the ALUs. This is not the first time we’ve seen this design – NVIDIA did something similar for their retired Fermi architecture – but this isn’t something we were expecting to see again. But with the idiosyncrasies of the SoC space, this is apparently something that still makes sense. Imagination did tell us that there are tangible power savings from doing this, and since SoC GPUs are power limited in most cases anyhow, this is essentially the higher performance option. Go faster by going slower.
Finally, this brings us to the highest level, the USC array. Each USC in an array receives its own thread to work on, so the number of threads actively being executed will be identical to the number of USCs in a design. For a high-end 6 module design, we’d be looking at 6 threads, whereas for a smaller 2 module design it would be just 2 threads.








95 Comments
View All Comments
dragonsqrrl - Tuesday, February 25, 2014 - link
... and the 64-bit architecture in the A7 is a completely different story. Apple wasn't first to market with 64-bit because they had an accelerated development schedule compared to other chipmakers. Apple was first to market because they started development first, ahead of everyone else.Apple doesn't develop Series 6, they license it, and we know when it becomes available for integration and when devices based on it come to market. We also know how long it usually takes between tapeout of an SOC, production, and final availability in devices, and based on this it would be very difficult if not impossible for Apple to put a 6XT in the A8 if they keep to their regular release schedule. I think going from an ~18 to ~8 month schedule is a bit much even for Apple, especially considering the new process shrink.
michael2k - Wednesday, February 26, 2014 - link
It's available for license now. Doesn't that normally mean that, as soon as the computer finishes synthesizing the design, it can be taped out now as well? The issue then is how much work needs to be done to get the design to work at the desired power envelope and clock, and if said work is worth it.Samus - Monday, February 24, 2014 - link
Considering the highly parallel nature of graphics processing, PowerVR's low core count and non-linear arrangement will make then weak in real-world gaming but strong in synthetic GFLOPS since their cores are stronger.For example, ATI has the weakest GPU cores of everybody but they cram over 2000 onto a GPU, seems to be doing pretty good for their performance.
michael2k - Tuesday, February 25, 2014 - link
Your example is irrelevant since ATI has no mobile solution and PowerVR has been the strongest in real world gaming since, well, until the K1 ships, PowerVR has had no real competition.Adreno is technically competent, but Qualcomm isn't seeking to push their transistor budget too high.
extide - Friday, February 28, 2014 - link
Wow, so you basically didn't read the article at all did you? This nonsense is exactly what this article is trying to prevent. Lol.Anders CT - Tuesday, February 25, 2014 - link
And what chip is using a GX6650 GPU? None existing that I know of.The Tegra K1 is a chip. Kepler and PowerVR 6XT is GPU architectures. And kepler has been around for several years.
dragonsqrrl - Wednesday, February 26, 2014 - link
Not sure how to respond to this, other than you completely misinterpreted my comment.dragonsqrrl - Wednesday, February 26, 2014 - link
Apologies, you weren't responding to my comment. I was wondering why it made no sense in the context of what I said.The comments section on Anandtech makes it really difficult sometimes to see who's responding to who, especially when it gets really long like this.
Sonicadvance1 - Monday, February 24, 2014 - link
So they have 2x Float32 ALU cores, 4x Float16 ALU cores, and a SFU core.This has no mention of Integer cores.
Am I to assume that integers won't run on the F32/F16 cores but instead of the SFU core so using integers will be 1/6th the speed of floats?
Seems like a large drawback, Mali and Adreno both run integers at the same speed as 32bit floats.
ryszu - Monday, February 24, 2014 - link
Integer happens on the F32 hardware.