The Intel Xeon E7 v2 Review: Quad Socket, Up to 60 Cores/120 Threads
by Johan De Gelas on February 21, 2014 6:00 AM EST- Posted in
- IT Computing
- Intel
- Xeon
- Ivy Bridge EX
- server
- Brickland
Bandwidth Monster
Previous versions of Intel's flagship Xeon always came with very conservative memory configurations as RAM capacity and reliability was the priority. Typically, these systems came with memory extension buffers for increased capacity, but those memory buffers also increase memory latency. As a result, these quad- and octal-socket monsters had a hard time competing with the best dual-Xeon setups in memory intensive applications.
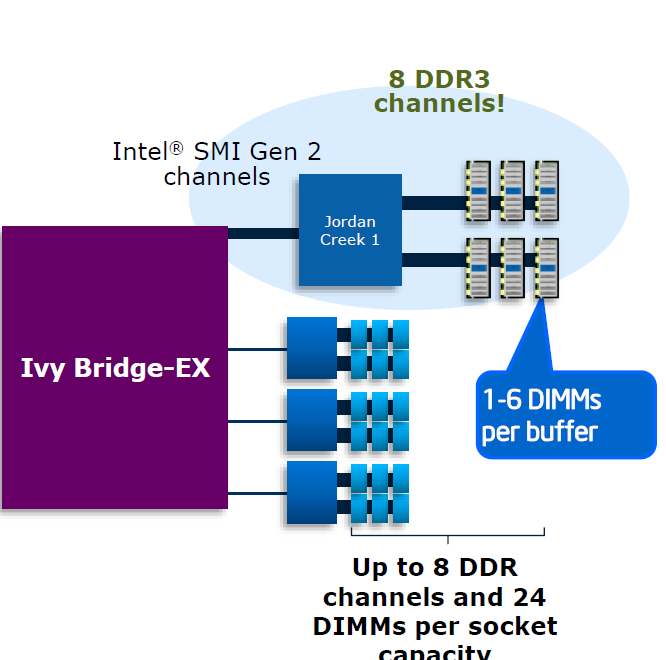
The new Xeon E7 v2 still has plenty of memory buffers (code named "Jordan Creek"), and it now supports three instead of two DIMMs per channel. The memory riser cards with two buffers now support 12 instead of eight DIMMs (Xeon Westmere-EX). Using relatively affordable 32GB DIMMs, this allows you to load a system machine up to 3TB RAM. If you break the bank and use 64GB LRDIMMs, 6TB RAM is possible.
With the previous platform, having eight memory channels only increased capacity and not bandwidth as they ran in lockstep. Each channel delivers half a cache line, then the Jordan Creek buffer combines those halves and sends off the result to the requesting memory controller. The high speed serial interface or scalable memory interconnect (SMI) channels must run at the same speed as the DDR3 channels. With Westmere-EX, this resulted in an SMI running at a maximum of 1066MHz. With the Xeon E7 v2, we get four SMI interconnects running at speeds up to 1600MHz. In lockstep, the system can survive a dual-device error. As result, the RAS (Reliability, Accessibility, Serviceability) is best in Lockstep.
With the Ivy Bridge EX version of the Xeon E7, the channels can also run independently. This mode is called performance mode and each channel can deliver one cache line. To cope with twice the amount of bandwidth, the SMI interconnect must run twice as fast as the memory channels. In this case, the SMI channel can run at 2667 MT/s while the two channels work at 1333 MT/s. That means in theory, the E7 v2 chip could deliver as much as 85GB/s (1333 * 8 channels * 8 bytes per channel) of bandwidth, which is 2.5x more than what the previous platform delivered. The disadvantage is that only a single device error can be corrected—more speed, less RAS.
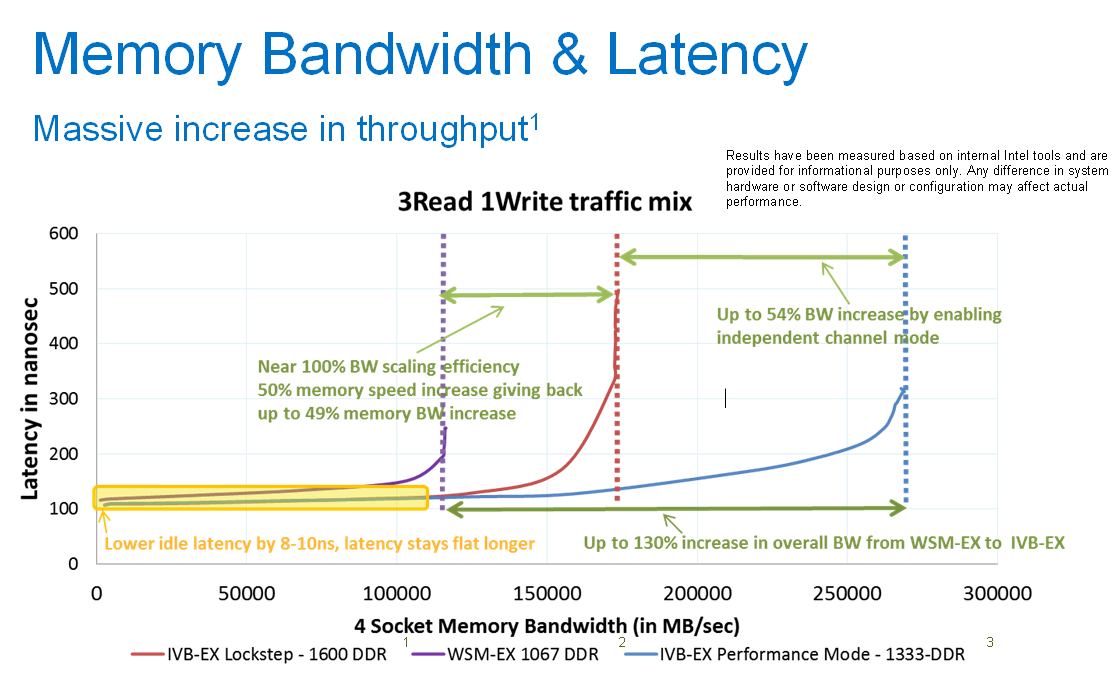
According to Intel, both latency and bandwidth are improved tremendously compared to the Westmere-EX platform. As a result, the new quad Xeon E7 v2 platform should perform a lot better in memory intensive HPC applications.








125 Comments
View All Comments
Brutalizer - Tuesday, February 25, 2014 - link
Clusters can not replace SMP servers. Clusters can not run SMP workloads.Kevin G - Tuesday, February 25, 2014 - link
I'm sorry, but it is considered best practice to run databases in pairs for redundancy. For example, here is an Oracle page explaining how clustering is used to maintain high availability: http://docs.oracle.com/cd/B28359_01/server.111/b28...Other databases like MySQL and MS SQL Server have similar offerings.
There is a reason why big hardware like this is purchased in pair or sets of three.
EmmR - Friday, March 14, 2014 - link
Kevin G. you are actually correct. We are in the process for comparing performance of Power7+ vs Xeon v2 for SAP batch workload and we got pretty much the same arguments from our AIX guys as Brutalizer mentionned.We are using real batch jobs rather than an synthetic benchmark and we set up each system to compare core-for-core, down to running a memory defrag on the Power system to make sure memory access is a good as possible. The only thing we could not fix is that in terms of network access, the Intel system was handicapped.
What we are seeing is that we can tune the Intel system to basically get similar performance (< 5% difference of total runtime) than from the Power7+ system (P780). This was quite unexpected but it's an illustration of how far Intel and the hardware vendors building servers/blades based on those CPUs have come.
Kevin G - Monday, March 17, 2014 - link
Looking at the Xeon E7 V2's right now is wise since they're just hitting market and the core infrastructure is expected to last three generations. It wouldn't surprise me if you can take a base system today using memory daughter cards and eventually upgrade it to Broadwell-EX and more DDR4 memory by the end of the product life cycle. This infrastructure is going to be around for awhile.POWER7+ on the other hand is going to be replaced by the POWER8 later this year. I'd expect it to perform better than the POWER7+ though how much will have to wait for the benchmarks after it is released. There is always going to be something faster/better/cheaper coming down the road in the computing world. Occasionally waiting makes sense due to generational changes like this. Intel and IBM tend to leap frog each other and it is IBM's turn to jump.
Ultimately if you gotta sign the check next week, I'd opt for the Xeon but if you can hold off a few months, I'd see what the POWER8 brings.
EmmR - Monday, March 17, 2014 - link
Power8 will be interesting to look at, but based on current data it will have to yield a pretty impressive performance boost over Power7+ (and Xeon v2) in order to be competitive on a performance per dollar spent.Kevin G - Monday, March 17, 2014 - link
IBM is claiming two to three times the throughput over POWER7+. Most of that gain isn't hard to see where it comes from: increasing the core count from 8 to 12. That change alone will put it ahead of the Xeon E7 v2's in terms of raw performance. Minor IPC and clock speed increases are expected too. The increase from 4 way to 8 way SMT will help some workloads, though it could also hurt others (IBM does support dynamic changes in SMT so this is straightforward to tune). The rest will likely come from system level changes like lower memory access times thanks to the L4 cache on the serial-to-parallel memory buffer and more bandwidth all around. What really interests me is that IBM is finally dropping the GX bus they introduced for coherency in the POWER4. What the POWER8 does is encapsulates coherency over a PCIe physical link. It'll be interesting to see how it plays out.As you may suspect, the cost of this performance may be rather high. We'll have to see when IBM formally launches systems.
amilayajr - Thursday, March 6, 2014 - link
I think Brutalizer is saying that, this new Xeon CPU is pretty much for targeted market. Unix since then has been the backbone of the internet, Intel as much as they can they want to cover the general area of server market. Sure it's a nice CPU, but as reliability goes, I would rather use a slower system but reliable in terms of calculations. I would still give intel the thumbs up for trying something new or updating the cpu. As for replacing unix servers for large database enterprise servers, probably not in a long time for intel. I would say to intel to leave on the real experts on this area that just focuses on these market. Intel is just covering their turf for smaller scale server market.Kevin G - Thursday, March 6, 2014 - link
The x86 servers have caught up in RAS features. High end features like hot memory add/remove are available on select systems. (Got a bad DIMM? Replace it while the systems is running.) Processor add/remove on a running system is also possible on newer systems but requires some system level support (though I'm not immediately familiar with a system offering it.) In most cases with the base line RAS features, Xeons are more than good enough for the job. Hardware lockstep is also an option on select systems.Uses for ultra high end features like two bit error correction for memory, RAID5-like parity across memory channels, and hot processor add/remove are a very narrow niche. Miscellaneous features like instruction replay don't actually add much in terms of RAS (replay on Itanium is used mainly to fill up unused instruction slots in its VLIW architecture, where as lock step would catch a similar error in all cases). Really, the main reason to go with Unix is on the software side, not the hardware side anymore.
djscrew - Wednesday, March 12, 2014 - link
"Sound like we are solving a problem with hardware instead of being innovative in software."that doesn't happen... ever... http://www.anandtech.com/show/7793/imaginations-po... ;)
mapesdhs - Sunday, February 23, 2014 - link
Brutalizer writes;
"Some examples of Scale-out servers (clusters) are all servers on the Top-500 supercomputer list. Other examples are SGI Altix / UV2000 servers or the ScaleMP server, they have 10,000s of cores and 64 TB RAM or more, i.e. cluster. Sure, they run a single unified Linux kernel image - but they are still clusters. ..."
Re the UV, that's not true at all. The UV is a shared memory system with a hardware MPI
implentation. It can scale codes well beyond just a few dozen sockets. Indeed, some key
work going on atm is how to scale relevant codes beyond 512 CPUs, not just 32 or 64.
The Cosmos installation is one such example. Calling a UV a cluster is just plain wrong.
Its shared memory architecture means it can handle very large datasets (hundreds of
GB) and extremely demanding I/O workloads; no conventional 'cluster' can do that.
Ian.