NVIDIA Tegra K1 Preview & Architecture Analysis
by Brian Klug & Anand Lal Shimpi on January 6, 2014 6:31 AM ESTCPU Option 2: Dual-Core 64-bit NVIDIA Denver
Three years ago, also at CES, NVIDIA announced that it was working on its own custom ARM based microprocessor, codenamed Denver. Denver was teased back in 2011 as a solution for everything from PCs to servers, with no direct mention of going into phones or tablets. In the second half of 2014, NVIDIA expects to offer a second version of Tegra K1 based on two Denver cores instead of 4+1 ARM Cortex A15s. Details are light but here’s what I’m expecting/have been able to piece together.
Given the 28nm HPM process for Tegra K1, I’d expect that the Denver version is also a 28nm HPM design. NVIDIA claims the two SoCs are pin-compatible, which tells me that both feature the same 64-bit wide LPDDR3 memory interface.

The companion core is gone in the Denver version of K1, as is the quad-core silliness. Instead you get two, presumably larger cores with much higher IPC; in other words, the right way to design a CPU for mobile. Ironically it’s NVIDIA, the company that drove the rest of the ARM market into the core race, that is the first (excluding Apple/Intel) to come to the realization that four cores may not be the best use of die area in pursuit of good performance per watt in a phone/tablet design.
It’s long been rumored that Denver was a reincarnation of NVIDIA’s original design for an x86 CPU. The rumor there being NVIDIA used binary translation to convert x86 assembly to some internal format (optimizing the assembly in the process for proper scheduling/dispatch/execution) before it hit the CPU core itself. The obvious change being instead of being x86 compatible, NVIDIA built something that was compatible with ARMv8.
I believe Denver still works the same way though. My guess is there’s some form of a software abstraction layer that intercepts ARMv8 machine code, translates and optimizes/morphs it into a friendlier format and then dispatches it to the underlying hardware. We’ve seen code morphing + binary translation done in the past, including famously in Transmeta’s offerings in the early 2000s, but it’s never been done all that well at the consumer client level.
Mobile SoC vendors are caught in a tough position. Each generation they are presented with opportunities to increase performance, however at some point you need to move to a larger out of order design in order to efficiently scale performance. Once you make that jump, there’s a corresponding increase in power consumption that you simply can’t get over. Furthermore, subsequent performance increases usually depend on leveraging more speculative execution, which also comes with substantial power costs.
ARM’s solution to this problem is to have your cake and eat it too. Ship a design with some big, speculative, out of order cores but also include some in-order cores when you don’t absolutely need the added performance. Include some logic to switch between the cores and you’re golden.
If Denver indeed follows this path of binary translation + code optimization/morphing, it offers another option for saving power while increasing performance in mobile. You can build a relatively wide machine (NVIDIA claims Denver is a 7-issue design, though it’s important to note that we’re talking about the CPU’s internal instruction format and it’s not clear what type of instructions can be co-issued) but move a lot of the scheduling/ILP complexities into software. With a good code morphing engine the CPU could regularly receive nice bundles of instructions that are already optimized for peak parallelism. Removing the scheduling/OoO complexities from the CPU could save power.
Granted all of this funky code translation and optimization is done in software, which ultimately has to run on the same underlying CPU hardware, so some power is expended doing that. The point being that if you do it efficiently, any power/time you spend here will still cost less than if you had built a conventional OoO machine.
I have to say that if this does end up being the case, I’ve got to give Charlie credit. He called it all back in late 2011, a few months after NVIDIA announced Denver.
NVIDIA announced that Denver would have a 128KB L1 instruction cache and a 64KB L1 data cache. It’s fairly unusual to see imbalanced L1 I/D caches like that in a client machine, which I can only assume has something to do with Denver’s more unique architecture. Curiously enough, Transmeta’s Efficeon processor (2nd generation code morphing CPU) had the exact same L1 cache sizes (it also worked on 8-wide VLIW instructions for what it’s worth). NVIDIA also gave us a clock target of 2.5GHz. For an insanely wide machine 2.5GHz sounds pretty high, especially if we’re talking about 28nm HPM, so I’m betting Charlie is right in that we need to put machine width in perspective.
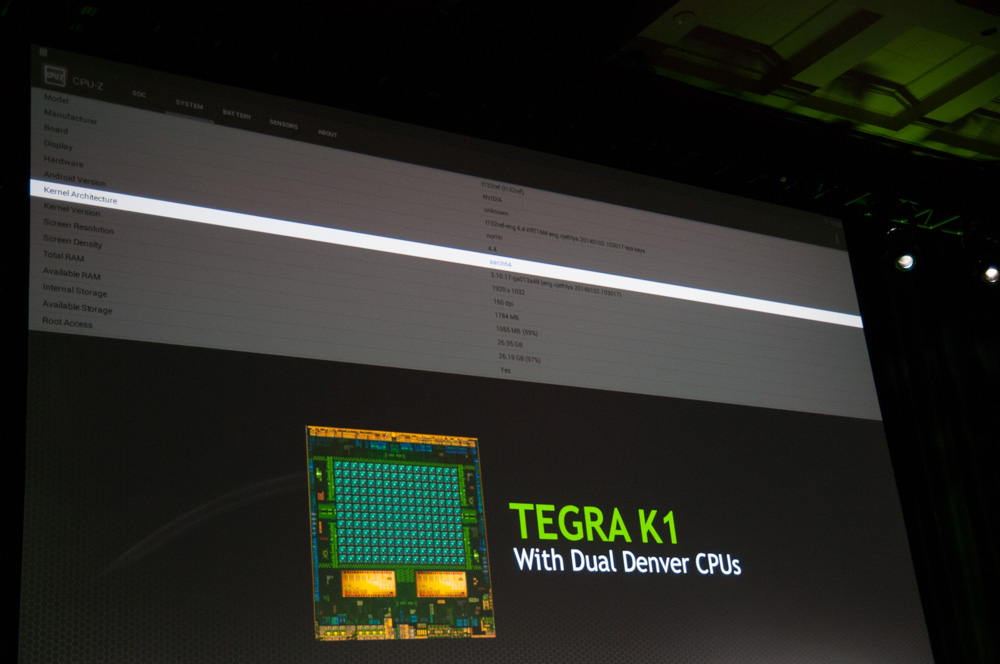
NVIDIA showed a Denver Tegra K1 running Android 4.4 at CES. The design came back from the fab sometime in the past couple of weeks and is already up and running Android. NVIDIA hopes to ship the Denver version of Tegra K1 in the second half of the year.
The Denver option is the more interesting of the two as it not only gives us another (very unique) solution to the power problem in mobile, but it also embraces a much more sane idea of the right balance of core size vs. core count in mobile.








88 Comments
View All Comments
eddman - Monday, January 6, 2014 - link
I'm wondering the same thing.Xbox and PS are gaming machines, running specialized OSes, and programmers can utilize low-level APIs and extract as much performance as possible.
Tegra K1 might be powerful, but it'll still be running general purpose OSes like android and windows RT.
Is there any way to know the performance gain by going low-level vs. high-level APIs for a video game? How much it really is? 5%? 15%? 40%?!!
Krysto - Monday, January 6, 2014 - link
Xbox360 and PS3 support DirectX9 and OpenGL ES 2.0+extensions. Many developers can and have made games with those APIs. Not all games on the consoles are "bare metal". So the "overall" difference in gaming, is probably not going to be very different.The real "problem" is that, those games will need to come to devices that have 1080p or even 2.5k resolutions, which will cut the graphics performance of the games by 2-4x, compared to Xbox/PS3. This is why I hate the OEMs for being so dumb and pushing resolutions even further on mobile.
It's a waste of component money (could be used for different stuff instead), of battery life, and also of GPU resources.
nicolapeluchetti - Monday, January 6, 2014 - link
I guess really good games use low levels API, i mean GTA V looks amazing and the specs of the X-Box 360 are what they are.I agree with you that resolution will be a problem, but actually i really like the added resolution in everyday use. i recently switched from a note 2 to a nexus 5 and the extra resolution is fantastic.
They will probably have to upscale things, render at 720p and render at 1080p
Krysto - Tuesday, January 7, 2014 - link
AMD said Mantle is pretty much bare-metal console API. And they said at their conference at CES that Battlefield 4 with that is 50 percent faster. So the difference is not huge, but significant.By far the biggest impact will be made by the resolution of the device. While games on Xbox 360 run at 720p, most devices with Tegra K1 will probably have at least a 1080p resolution, which is twice as many pixels, so it cuts the performance in half (or the graphics quality).
TheJian - Sunday, January 12, 2014 - link
Link please, and at what point in the vid do they say it (because some of those vids are 1hr+ for conferences)? I have seen only ONE claim and by a single dev who said you might get 20% if lucky. It is telling that we have NO benchmarks yet.But I'm more than happy to read about someone using Mantle actually saying they expect 45-50% IN GAME over a whole benchmark (not some specific operation that might only be used once). But I don't expect it to go ever 20%.
Which makes sense given AMD shot so low with their comment of "we wouldn't do it for 5%". If it was easy to get even 40% wouldn't you say "we wouldn't do it for 25%"? Reality is they have to spend to get a dev to do this at all, because they gain NOTHING financially for using Mantle unless AMD is paying them.
I'll be shocked to see BF4 over 25% faster than with it off (I only say 25% for THIS case because this is their best case I'm assuming, due to AMD funding it big time as a launch vehicle). Really I might be shocked at 20% but you gave me such a wide margin to be right saying 50%. They may not even get 20%.
Why would ANY dev do FREE work to help AMD, and when done be able to charge ZERO over the cost of the game for everyone else that doesn't have mantle? It would be easier to justify it's use if devs could charge Mantle users say $15 extra per game. But that just won't work here. So you're stuck with amd saying "please dev, I know its more work and you won't ever make a dime from it, but it would be REALLY nice for us if you did this work free"...Or "Hi, my name is AMD, here's $8 Million dollars, please use Mantle". Only the 2nd option works at all, and even then you get Mantle being back burner the second the game needs to be fixed for the rest of us (BF4 for instance, all stuff on back burner until BF4 is fixed for regular users). This story is no different than Phsyx etc.
nicolapeluchetti - Tuesday, January 7, 2014 - link
Mantle is said to have 45% performance bonus compared to DirectX on Battlfield. Those are the rumours.OreoCookie - Monday, January 6, 2014 - link
It's great to see that finally the SoC makers are being serious about GPU compute, now it's up to software developers to take advantage of all that compute horsepower. Given Apple's focus on GPU performance in the past, I'm curious to see what their A8 looks like and how it stacks up against Tegra K1 (in particular the Denver version).timchen - Monday, January 6, 2014 - link
The Denver speculation really needs some justification.Doesn't common sense say that the same task is always more power efficient done with hardware rather than software? It would at least need a paragraph or two to explain how OoO or speculative execution or ILC can be more power efficient in software.
Now if it is just that you need to build different binaries specifically for these cores, it then sounds a lot more like a compute GPU actually-- but as far as I understand so far general tasks are not suitable to run on those configurations, and parallelization for general problems is pretty much a dead horse (similar to P=NP?) now.
KAlmquist - Monday, January 6, 2014 - link
That speculation didn't make a lot of sense to me, either.One of the reasons that out of order execution improves performance is that cache misses are expensive. In an out of order processor, when a cache miss occurs the processor can defer the instructions that need that particular piece of data, and execute other instructions while waiting for the read to complete. To create "nice bundles of instructions that are already optimized for peak parallelism," you have to know how long each memory read is going to take.
The writers mention the Transmeta Efficeon processor, which translated x86 instructions to native instructions and then executed them on an in-order processor. That was a fairly effective approach, but doesn't demonstrate that an in-order processor can compete with a modern out of order processor. After all, ARM started out producing in-order processors, which were very energy efficient, but eventually they had to produce an out of order design in order to increase performance without increasing the clock rate.
Loki726 - Monday, January 6, 2014 - link
Transmeta didn't have an in-order design in the same way that a normal CPU is in order. See their CGO paper: http://people.ac.upc.edu/vmoya/docs/transmeta-cgo....Here's the relevant text:
"Compilers typically deal with recovery from speculation by generating compensation code, which re-
executes incorrectly sequenced operations, performs operations omitted from the speculative code path, and
corrects mismatches in register assignments (Freudenberger et al. [13]). With this approach, hardware
support is required to defer faults of potentially faulting instructions moved above branches (e.g.,
boosting,Smith et al. [23]), to detect overlapping memory operations scheduled out of sequence, and to branch to the
compensation code (e.g., memory conflict buffers, Gallagher et al. [14], or the Intel IA-64 ALAT[18]).
In contrast, Crusoe native VLIW processors provide an elegant hardware solution that supports arbitrary kinds of
speculation and subsequent recovery and works hand-in-hand with the Code Morphing Software [8]. All registers
holding x86 state are shadowed; that is, there exist two copies of each register, a working copy and a shadow
copy. Normal atoms only update the working copy of the register. If execution reaches the end of a translation, a
special commit operation copies all working registers into their corresponding shadow registers, committing the
work done in the translation. On the other hand, if any exceptional condition, such as the failure of one of CMS’s
translation assumptions, occurs inside the translation, the runtime system undoes the effects of all molecules
executed since the last commit via a rollback operation that copies the shadow register values (committed at the
end of the previous translation) back into the working registers.
Following a rollback, CMS usually interprets the x86 instructions corresponding to the faulting translation, executing
them in the original program order, handling any special cases that are encountered, and invoking the x86
exception-handling procedure if necessary.
Commit and rollback also apply to memory operations. Store data are held in a gated store buffer, from which they
are only released to the memory system at the time of a commit. On a rollback, stores not yet committed can
simply be dropped from the store buffer. To speed the common case of no rollback, the mechanism was designed so
that commit operations are effectively “free”[27], while rollback atoms cost less than a couple of branch mispredictions."