NVIDIA Tegra K1 Preview & Architecture Analysis
by Brian Klug & Anand Lal Shimpi on January 6, 2014 6:31 AM ESTCPU Option 2: Dual-Core 64-bit NVIDIA Denver
Three years ago, also at CES, NVIDIA announced that it was working on its own custom ARM based microprocessor, codenamed Denver. Denver was teased back in 2011 as a solution for everything from PCs to servers, with no direct mention of going into phones or tablets. In the second half of 2014, NVIDIA expects to offer a second version of Tegra K1 based on two Denver cores instead of 4+1 ARM Cortex A15s. Details are light but here’s what I’m expecting/have been able to piece together.
Given the 28nm HPM process for Tegra K1, I’d expect that the Denver version is also a 28nm HPM design. NVIDIA claims the two SoCs are pin-compatible, which tells me that both feature the same 64-bit wide LPDDR3 memory interface.

The companion core is gone in the Denver version of K1, as is the quad-core silliness. Instead you get two, presumably larger cores with much higher IPC; in other words, the right way to design a CPU for mobile. Ironically it’s NVIDIA, the company that drove the rest of the ARM market into the core race, that is the first (excluding Apple/Intel) to come to the realization that four cores may not be the best use of die area in pursuit of good performance per watt in a phone/tablet design.
It’s long been rumored that Denver was a reincarnation of NVIDIA’s original design for an x86 CPU. The rumor there being NVIDIA used binary translation to convert x86 assembly to some internal format (optimizing the assembly in the process for proper scheduling/dispatch/execution) before it hit the CPU core itself. The obvious change being instead of being x86 compatible, NVIDIA built something that was compatible with ARMv8.
I believe Denver still works the same way though. My guess is there’s some form of a software abstraction layer that intercepts ARMv8 machine code, translates and optimizes/morphs it into a friendlier format and then dispatches it to the underlying hardware. We’ve seen code morphing + binary translation done in the past, including famously in Transmeta’s offerings in the early 2000s, but it’s never been done all that well at the consumer client level.
Mobile SoC vendors are caught in a tough position. Each generation they are presented with opportunities to increase performance, however at some point you need to move to a larger out of order design in order to efficiently scale performance. Once you make that jump, there’s a corresponding increase in power consumption that you simply can’t get over. Furthermore, subsequent performance increases usually depend on leveraging more speculative execution, which also comes with substantial power costs.
ARM’s solution to this problem is to have your cake and eat it too. Ship a design with some big, speculative, out of order cores but also include some in-order cores when you don’t absolutely need the added performance. Include some logic to switch between the cores and you’re golden.
If Denver indeed follows this path of binary translation + code optimization/morphing, it offers another option for saving power while increasing performance in mobile. You can build a relatively wide machine (NVIDIA claims Denver is a 7-issue design, though it’s important to note that we’re talking about the CPU’s internal instruction format and it’s not clear what type of instructions can be co-issued) but move a lot of the scheduling/ILP complexities into software. With a good code morphing engine the CPU could regularly receive nice bundles of instructions that are already optimized for peak parallelism. Removing the scheduling/OoO complexities from the CPU could save power.
Granted all of this funky code translation and optimization is done in software, which ultimately has to run on the same underlying CPU hardware, so some power is expended doing that. The point being that if you do it efficiently, any power/time you spend here will still cost less than if you had built a conventional OoO machine.
I have to say that if this does end up being the case, I’ve got to give Charlie credit. He called it all back in late 2011, a few months after NVIDIA announced Denver.
NVIDIA announced that Denver would have a 128KB L1 instruction cache and a 64KB L1 data cache. It’s fairly unusual to see imbalanced L1 I/D caches like that in a client machine, which I can only assume has something to do with Denver’s more unique architecture. Curiously enough, Transmeta’s Efficeon processor (2nd generation code morphing CPU) had the exact same L1 cache sizes (it also worked on 8-wide VLIW instructions for what it’s worth). NVIDIA also gave us a clock target of 2.5GHz. For an insanely wide machine 2.5GHz sounds pretty high, especially if we’re talking about 28nm HPM, so I’m betting Charlie is right in that we need to put machine width in perspective.
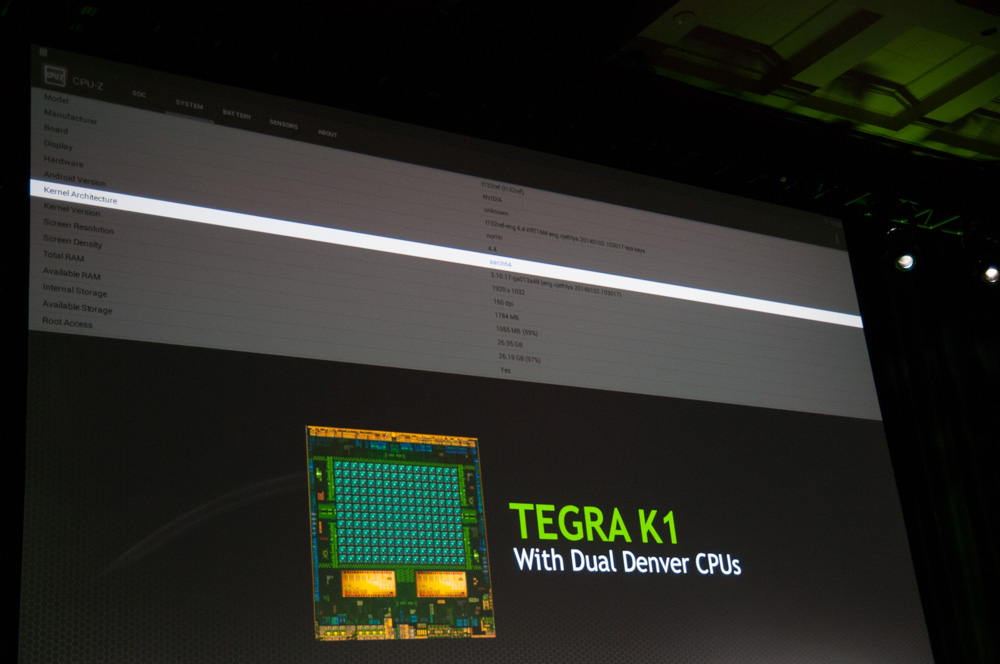
NVIDIA showed a Denver Tegra K1 running Android 4.4 at CES. The design came back from the fab sometime in the past couple of weeks and is already up and running Android. NVIDIA hopes to ship the Denver version of Tegra K1 in the second half of the year.
The Denver option is the more interesting of the two as it not only gives us another (very unique) solution to the power problem in mobile, but it also embraces a much more sane idea of the right balance of core size vs. core count in mobile.








88 Comments
View All Comments
da_asmodai - Monday, January 6, 2014 - link
This articles says first, first, first for Kepler core in mobile but it's not out yet and I believe everything that's claimed as a first in this article is also supported by the Adreno 420 in the already announced Snapdragon 805. I'd like to see a side by side spec comparison of Kepler, Adreno 420, and PowerVR Series 6XT.dwforbes - Monday, January 6, 2014 - link
"FP64 support is also present, at 1/24 the FP32 rate"Should this 1/2 the FP32 rate, or is it really so crippled?
Ryan Smith - Monday, January 6, 2014 - link
No, 1/24 is correct. It's so that you have native FP64 when you need it, but you aren't wasting die space on precision you aren't going to use.ddriver - Monday, January 6, 2014 - link
nvidia being cheap once again, deliberately ruining compute performance like they did with desktop GPUs for years. And let me guess, no openCL support either? Thanks but no thanks, gonna stick to qualcomm and samsung mobile platforms and amd/radeon on the desktop. And for what? To push their ridiculously and shamelessly overpriced "professional" products?GTX 780 DP @ 1/24 SP
R9 290 DP @ 1/8 SP
R9 280 DP @ 1/4 SP
Loki726 - Monday, January 6, 2014 - link
Adding big double precision units has real area and power costs (you typically can't rail gate off individual functional units). If you put full-rate double precision units in a mobile SoC it would just sit there draining your battery life.ddriver - Monday, January 6, 2014 - link
Unfortunately, power efficiency is just the excuse to deliberately cripple compute performance of consumer products. As you see, AMD has no problem providing DP support with lower penalty, which is the reason my compute farm runs radeons exclusively, because the performance per $ ratio completely destroys prosumer products. I do realize I am a very specific and narrow case, since I couldn't care less about gaming and graphics performance, since I use it only to rasterize the compute output, but still... why not go for a more performing design, considering it is not that much about efficiency but the greed for the fat profit margins of teslas and quadros that motivates nvidia to cripple DP performance to such a horrendous extent.Loki726 - Monday, January 6, 2014 - link
AMD doesn't release a mobile GPU part, and the Qualcomm parts which are based off of the old AMD VLIW5 design that they bought from AMD don't include double precision. Every little bit of power matters in mobile.ddriver - Monday, January 6, 2014 - link
The 1/24 DP performance does not come as a mobile-dedicated design, even the GTX 780 is crippled this way, even though it is an enthusiast part, where power efficiency is the least concern.Loki726 - Monday, January 6, 2014 - link
They are different strategies. Neither one is ideal for everyone.Putting double precision hardware into consumer parts is effectively asking
gamers to pay for extra area and power. I do agree that this is less of an
issue in desktop parts compared to mobile, but it is still an issue and GPUs
have enough ALUs in them that you would notice it if every one of them got 10%
less efficient in benchmarks.
AMD builds one chip and sells it into both compute and graphics markets. In
order to make it appealing for compute applications they add double precision.
They make gamers pay for this even though they never use it, but they don't have
to pay the design costs of building multiple chips. NVIDIA builds two
different designs. One chip for compute and another one for graphics (although
this round they also sold the compute chip into the graphics market - Titan).
Presumably they do this because they think that they can recoup the extra cost
of building a different chip that only compute users buy, and by doing so
they don't make gamers pay extra for double precision.
The compute chip has extra features like more registers, ECC, more double
precision units, dynamic parallelism, etc. Chip design is expensive. Think
hundreds of millions of dollars for a new design. If there were just as many
users of compute GPUs as there are gamers who buy graphics cards, the prices
would probably come down a lot.
I'm with you that I would like to have cheaper compute parts with full double
precision support, but I think the only real way to drive down chip prices is to
make them a commodity. It won't happen until there is a killer compute app
that makes every desktop owner want to go out and buy a compute GPU.
ddriver - Tuesday, January 7, 2014 - link
And how do consumers exactly "pay extra" for the better DP performance when AMD GPUs are overall much better value than nvidia gpus? It seems to me that if the extra cost is as high as you believe it is (which it really isn't) then it is AMD that pays it with its profit margins.