Memory Scaling on Haswell CPU, IGP and dGPU: DDR3-1333 to DDR3-3000 Tested with G.Skill
by Ian Cutress on September 26, 2013 4:00 PM ESTOne of the touted benefits of Haswell is the compute capability afforded by the IGP. For anyone using DirectCompute or C++ AMP, the compute units of the HD 4600 can be exploited as easily as any discrete GPU, although efficiency might come into question. Shown in some of the benchmarks below, it is faster for some of our computational software to run on the IGP than the CPU (particularly the highly multithreaded scenarios).
Grid Solvers - Explicit Finite Difference on IGP
As before, we test both 2D and 3D explicit finite difference simulations with 2n nodes in each dimension, using OpenMP as the threading operator in single precision. The grid is isotropic and the boundary conditions are sinks. We iterate through a series of grid sizes, and results are shown in terms of ‘million nodes per second’ where the peak value is given in the results – higher is better.
Two Dimensional:

The results on the IGP are 50% higher than those on the CPU, and it would seem that memory can make a difference as well. As long as 1333 MHz is not chosen, there is at least a 2% gain to be had. Otherwise, the next jump up is at 2666 MHz for another 2%, which might not be cost effective.
Three Dimensional:
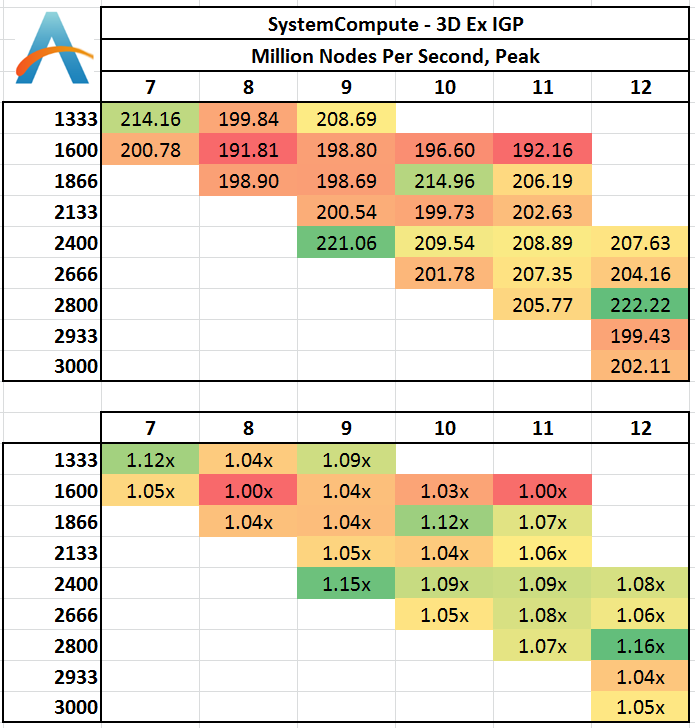
The 3D results seem to be a little haphazard, with 1333 C7 and 2400 C9 both performing well. 1600 C11 definitely is out of the running, although anything 2400 MHz or above affords almost a 10%+ benefit.
N-Body Simulation on IGP
As with the CPU compute, we run a simulation of 10240 particles of equal mass - the output for this code is in terms of GFLOPs, and the result recorded was the peak GFLOPs value.

In terms of a workload that calculates FLOPs, the operational workload does not seem to be affected by memory.
3D Particle Movement on IGP
Similar to our CPU Compute algorithm, we calculate the random motion in 3D of free particles involving random number generation and trigonometric functions. For this application we take the fastest true-3D motion algorithm and test a variety of particle densities to find the peak movement speed. Results are given in ‘million particle movements calculated per second’, and a higher number is better.
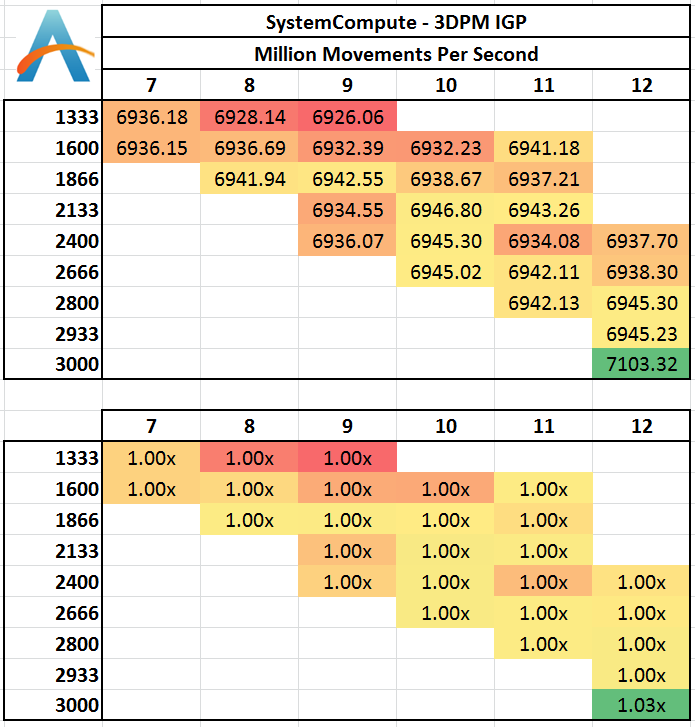
Despite this result being over 35x the equivalent calculation on a fully multithreaded 4770K CPU (200 vs. 7000), again there seems little difference between memory speeds. 3000 C12 gets a small peak over the rest, similar to the n-Body test.
Matrix Multiplication on IGP
Matrix Multiplication occurs in a number of mathematical models, and is typically designed to avoid memory accesses where possible and optimize for a number of reads and writes depending on the registers available to each thread or batch of dispatched threads. He we have a crude MatMul implementation, and iterate through a variety of matrix sizes to find the peak speed. Results are given in terms of ‘million nodes per second’ and a higher number is better.
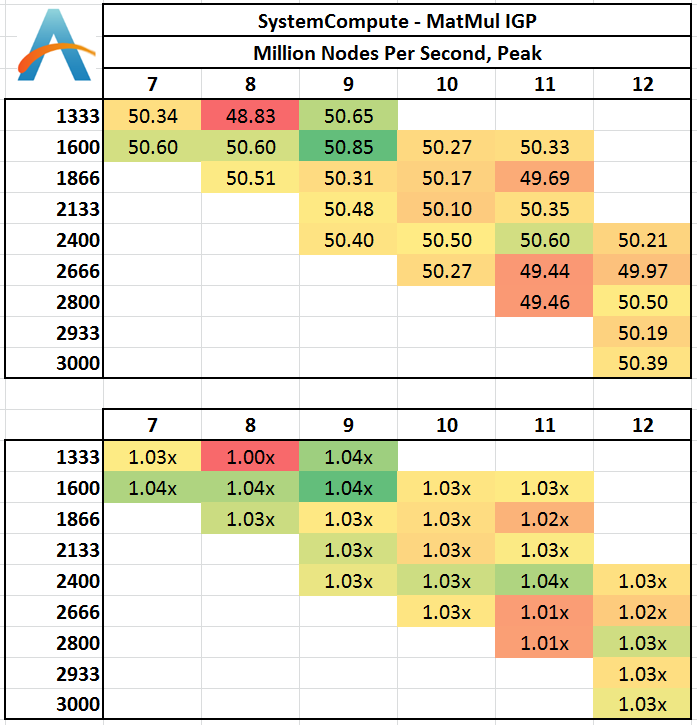
Matrix Multiplication on this scale seems to vary little between memory settings, although a shift towards the lower CL timings gives a marginally (though statistically minor) better result.
3D Particle Movement on IGP
Similar to our 3DPM Multithreaded test, except we run the fastest of our six movement algorithms with several million threads, each moving a particle in a random direction for a fixed number of steps. Final results are given in million movements per second, and a higher number is better.
While there is a slight dip using 1333 C9, in general almost all of our memory timing settings perform roughly the same. The peak shown using our memory kit at its XMP rated timings are presumably more due to the adjustments in BCLK which need to be made in order to hit this memory frequency.








89 Comments
View All Comments
gsuburban - Thursday, November 28, 2013 - link
Interesting article however, "Number of Sticks" as noted above would mean what? Is there a performance gain or loss using the same amount of Gigs of the same RAM in say 16GB in two dims versus 16GB of the same using 4 dimms?neal.a.nelson - Sunday, December 8, 2013 - link
That is a reasonable inference, and given the age of the article and date of the last post, probably all you're going to get. For upgrade ability, it's smart to use the two dual-channel slots instead of filling all four with the same amount.htwingnut - Monday, January 20, 2014 - link
Thanks for this testing and article. This shows 1366x768 for resolution. While I understand that this will test the RAM fully, it's also not realistic. I'd like to see results running single 1080p or 3x1080p because that's more real world.melk - Thursday, January 23, 2014 - link
Am I reading this correctly? That there is literally a 1fps difference at best, in both lowest and avg fps?melk - Thursday, January 23, 2014 - link
So we are talking about a ~1 fps difference in real world testing? Wow...dasa43 - Friday, February 28, 2014 - link
To see gains from faster ram the game needs to be cpu limited while most console ports are totally gpu limitedIncreasing resolution just stresses the gpu more further lightning the load on the cpu
Thief & Arma are two cpu limited games that can see big gains from faster ram
Thief benchmarks
http://forums.atomicmpc.com.au/index.php?showtopic...
Arma benchmarks
http://forums.bistudio.com/showthread.php?166512-A...
NordRack2 - Sunday, June 1, 2014 - link
Quote: "Using the older version of WinRAR shows a 31% advantage moving from 1333 C9 to 3000 C12"That's wrongly calculated.
Correct is: ((213.63-163.11)/213.63) × 100% = 24%
cadman777 - Sunday, April 19, 2015 - link
Dear Sir,Do you have an article that explains the basics for RAM, CPU & m/b matching?
I want to learn the basics on this, but all I keep finding are articles like this with bits and pieces, and general explanations of the various components, but no pragmatic explanations on how they work together and how to match them and do the over-clocking between the various components to arrive at a stable system.
Thanx ... Chris
Nickolai - Sunday, August 13, 2017 - link
Is there a similar article for DDR4?