Westmere-EP to Sandy Bridge-EP: The Scientist Potential Upgrade
by Ian Cutress on March 4, 2013 9:30 AM EST- Posted in
- CPUs
- Xeon
- Westmere-EP
- Sandy Bridge-EP
For completeness, we run our normal motherboard benchmarks.
WinRAR x64 3.93 - link
With 64-bit WinRAR, we compress the set of files used in the USB speed tests. WinRAR x64 3.93 attempts to use multithreading when possible, and provides as a good test for when a system has variable threaded load. If a system has multiple speeds to invoke at different loading, the switching between those speeds will determine how well the system will do.

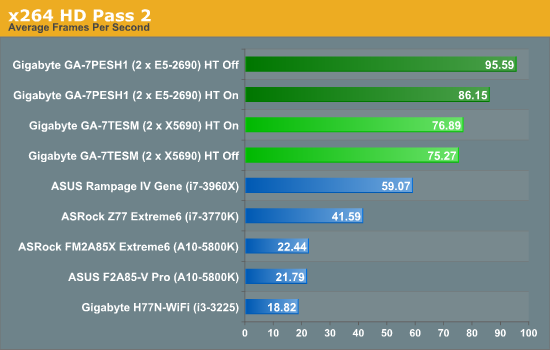
Despite the slight memory difference between the two platforms, using E5-2690s with HT off has a significant 29% advantage over HT being on or the X5690 results.
FastStone Image Viewer 4.2 - link
FastStone Image Viewer is a free piece of software I have been using for quite a few years now. It allows quick viewing of flat images, as well as resizing, changing color depth, adding simple text or simple filters. It also has a bulk image conversion tool, which we use here. The software currently operates only in single-thread mode, which should change in later versions of the software. For this test, we convert a series of 170 files, of various resolutions, dimensions and types (of a total size of 163MB), all to the .gif format of 640x480 dimensions.

With the single thread speeds being similar, the only separation between our systems should be IPC – and thus as expected the Sandy Bridge-EP system is ahead, but only by 3-6%.
Xilisoft Video Converter
With XVC, users can convert any type of normal video to any compatible format for smartphones, tablets and other devices. By default, it uses all available threads on the system, and in the presence of appropriate graphics cards, can utilize CUDA for NVIDIA GPUs as well as AMD APP for AMD GPUs. For this test, we use a set of 32 HD videos, each lasting 30 seconds, and convert them from 1080p to an iPod H.264 video format using just the CPU. The time taken to convert these videos gives us our result.

With XVC having many threads is what counts, meaning that 24 threads on a full X5690 system will equal our small video conversion test. At this level, we would need more content to see significant difference. With HT off however, the Westmere-EP result is nearer that of a single 3960X than the E5-2690s.
x264 HD Benchmark
The x264 HD Benchmark uses a common HD encoding tool to process an HD MPEG2 source at 1280x720 at 3963 Kbps. This test represents a standardized result which can be compared across other reviews, and is dependant on both CPU power and memory speed. The benchmark performs a 2-pass encode, and the results shown are the average of each pass performed four times.









44 Comments
View All Comments
jamyryals - Monday, March 4, 2013 - link
Element is an acceptable term in this case. Anyone confusing a finite element with a chemical element would do well to read up on these types of mathematical models anyways.Your other points are well made, and highlight the difficulty in creating meaningful benchmarks.
Kevin G - Monday, March 4, 2013 - link
I agree that the usage of the word element is technically correct. The thing that threw me off more was its usage in conjunction with particle. When I read that paragraph I had to do a double take to get the proper context. My issue here is just a small editorial quibble than a technical issue. :)IanCutress - Tuesday, March 5, 2013 - link
A majority of the results in the graphs (essentially all the overclocked ones) were on systems out of my control - several users from the Overclock.net HWBot team helped on that one and offered me insight into their setups. Unfortunately I do not have access to a vast array of sockets and systems for comparison.The implicit calculations have a fair few division elements per loop, as noted in the previous article where I posted the code (http://www.anandtech.com/show/6533/8) - for each timestep there are >2 divisions per node calculation. Technically the non-CS scientist might not know what is inside the silicon regarding Ivy's better divisor .
Don't forget the whole point of a review of something like this was to look at the scenario I was in. We went and ordered dual Nehalem systems (E5520s) just because of all the threads. Looking back on it now, I wish we had stuck to single processor systems based on the code we were writing.
Regarding the built-in Ivy PRNG, as noted in the previous review, the code wasn't hand written for each processor. It was written once and applied over. We didn't get extra time or money to find the best way to simulate something, we just had to simulate.
Regarding element and particle, I almost use them synonymously in the text. I like to use 'element' to describe the motion of one point in the simulation, but my Chemistry supervisor thought I was being an idiot when we were dealing with chemicals, despite my pleas that element was a CS term. He preferred the term particle as a mid-way point between the two (and also not to confuse the chemistry people reading our papers) and mentally I have equated the two, which is not always the best thing.
For XVC, I'm not sure why there is such a difference. With HT On, we have 24 threads to do 33 videos, which is one batch of 24 then another of 9 (put your turbos in where appropriate). Without HT, we're slightly faster per core (if we're lucky, or 0 if not), but we have batches of 12, 12 and then 9. Again, apply turbos where appropriate. That's just the program runs - it decides if it wants to commit one thread per video, or multiple threads per video. If it is coding more videos than half the available threads, it does one thread per video - if there is enough threads that each video can get two, it applies two. So the set of 9 videos when HT is on probably gets two threads per video, rather than one thread per video for the 9 videos when HT is off.
Ian
Kevin G - Tuesday, March 5, 2013 - link
The thing with Ivy Bridge's improved division unit is that it can explain some of the speed up. Glancing at the code, those operations don't seem to be that common that it'd make such a noticeable impact. (The real test would be to compile, disassemble and then count the number of division instructions.) The other thing about Ivy Bridge's divisor is that its performance gains are 'free' in the sense that it doesn't require rewriting or recompiling code to take advantage of. It is an architectural tweak that benefits existing code.Upon release, Nehalem was a very good platform and still respectable today. I think the issue is that consumer systems have been catching up. Looking at the charts the only consumer system that's a roughly the same age as the E5520's was an overclocked Phenom II X4's and the dual socket Xeon showed an advantage there. The problem I'm seeing is that the code isn't scaling across multiple sockets and memory controllers very well. Solving that would put performance closer to expectations. If possible, I would suggest enabling memory mirroring across sockets to see if that solves some of the scaling issues. The code wouldn't have to be written to be NUMA aware but usable memory in the system is halved.
If the NUMA problem is not practical to solve, then going single socket makes sense. Howevever, I would expand the discussion into include RAS. I would not recommend a single highly overclocked system to run scientific simulations as the reliability simply isn't there. One way around that is to get two similarly configured systems and run the simulation twice and compare the results for redunancy. With some of these heavily overclocked systems costing less than half the dual Xeon's price tag and running the code twice as fast, it is worth considering such a mirrored configuration. Other options to consider would be a single 8 core Xeon on socket 2011 or some of the quad core Xeon on socket 1155 and gain ECC memory support to forgo the second system.
The XVC results can see some improvements in queuing but those benefits should be able to carry over to the non-HT results with a software tweak. (Most software like that can accept such tuning parameters but I'm personally unfamiliar with XVC.) The results are falling outside the realm of reason. It is like say cooling a gas until you realize you're at -20 kelvin. At that point you have to realize something is erroneous. At best HT can double performance and the results are roughly five times faster. Turbo is a factor but that would benefit the non-HT results more as utilization is lower (ie. fewer transistors switching, less heat, more turbo boost).
toyotabedzrock - Monday, March 4, 2013 - link
I looks like Intel forgot about HT on sandy bridge.IanCutress - Tuesday, March 5, 2013 - link
i5-2500K is a 4C/4T processor.Ian
TeXWiller - Monday, March 4, 2013 - link
Ian, have you tried playing with the numa options of the boards?IanCutress - Tuesday, March 5, 2013 - link
NUMA was enabled in the BIOS, I made sure before I tested :) I also looked at various ways to keep the top turbo in force through all loading, but the limited BIOS options relating to clock speed on server boards are not up to scratch compared to consumer products (as you would expect).Ian
TeXWiller - Tuesday, March 5, 2013 - link
I was thinking about the improved bandwith between the processors in E5 family. Some aplications might prefer node interleaved memory instead.alpha754293 - Monday, March 4, 2013 - link
re: OpenMP vs. MPIMultithreaded codes using OpenMP is known to be quite a lot slower than a proper, MPI code. In the testing that I've done, the difference can be as much as 40% because the OpenMP code just simply cannot keep the CPU/FPU units occupied long enough. I've never really dug in deep as to WHY that is (I'm sooo NOT a programmer), but as an end user; that a HUGE difference.
Secondly, also depending on how you write your MPI code - some of them can be VERY efficient at using multicore/multiprocessors. It depends on the code, the nature and physics of the problem, and a whole bunch of other things. (LS-DYNA for example scales VERY well to the number of processors and/or cores. And my research is showing about an 11-17% benefit with HTT enabled on a 3930K (I don't have 8-core Xeons to play with). :(
Conversely, I've also seen some MPI codes that don't really quite parallelize nearly quite as well. It SAYS that it's MPI, but it looks more like an OpenMP implementation for the parallelization.
Part of it also depends on how much data dependency there is - does the information of one depend on the results or the information/data of another (either on spatial or temporal terms)?
Third - I've had many arguments about this. A single socket, multi-core processor is still a parallel multicore system. Yes, you don't have to deal with NUMA, but unless you have a LOT of traffic going through between your two sockets (something which NO ONE has been able to tell me how to measure so far) - chances are, both either OpenMP OR MPI can scale to single multi-core processor, or multiple multi-core processors. It shouldn't really care (unless you've hard-coded the domain decomposition and the number of "partitions" or "divisions" it makes for the parallelization.)
I think that the statement/comment that you wrote about how some of the benchmarks or some types of simulations/processes favour a single-CPU setup isn't QUITE exactly accurate only because your single-socket, multi-core CPUs were quite highly overclocked. (I've got my 3930K up to 4.5 GHz, and I just re-enabled C1E/EIST in order to cut my idle power consumption).
[brb...to be continued]