The Xeon Phi at work at TACC
by Johan De Gelas on November 14, 2012 1:44 PM EST- Posted in
- Cloud Computing
- CPUs
- IT Computing
- Intel
- Larrabee
- Xeon
- Xeon Phi
The Xeon Phi family of co-processors was announced in June, but Intel finally disclosed additional details.The Xeon Phi die is a massive chip: Almost 5 billion transistors using Intel's most advanced 22nm process technology with 3D tri-gate transistors.
A maximum of 62 cores can fit on a single die. Each core is a simple in order x86 CPU (derived from the original Pentium) with a 512-bit SIMD unit. There is a twist though: the core can handle 4 threads simultaneously. Nehalem, Sandy and Ivy Bridge also use SMT, but those cores uses SMT mostly to make better use of their ample execution resources.
In case of the Xeon Phi core, the 4 threads are mostly a way to hide memory latency. In the best case, two threads will execute in parallel.
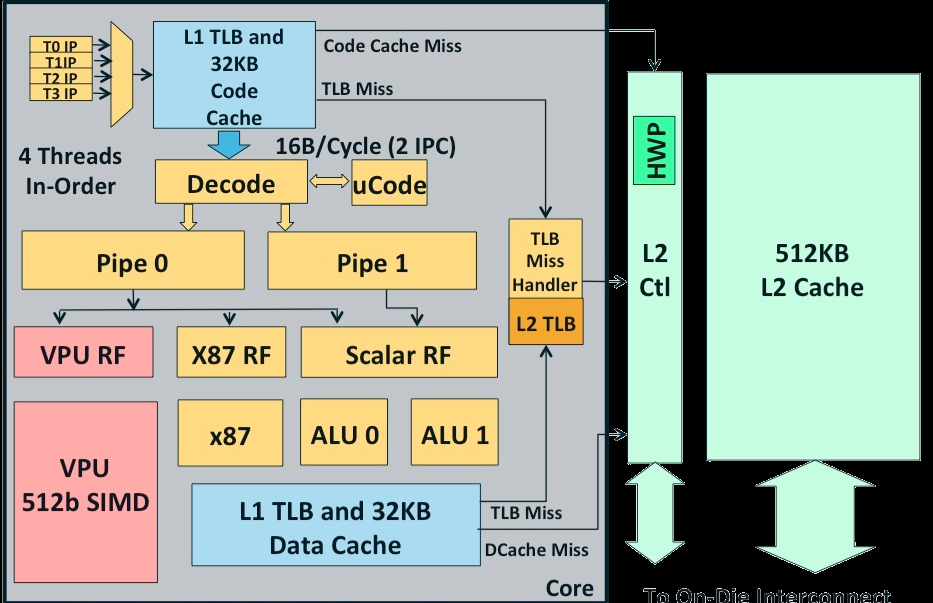
Each of these cores is a 64-bit x86 core. However, only 2% of the core logic (excluding the L2-cache) is spent on x86 logic. The SIMD unit does not support MMX, SSE or AVX: the Xeon Phi has its own vector format.
All of the cores are connected together with a bi-directional ring, similar to what's used in the Xeon E7 and the Sandy Bridge EP CPUs.
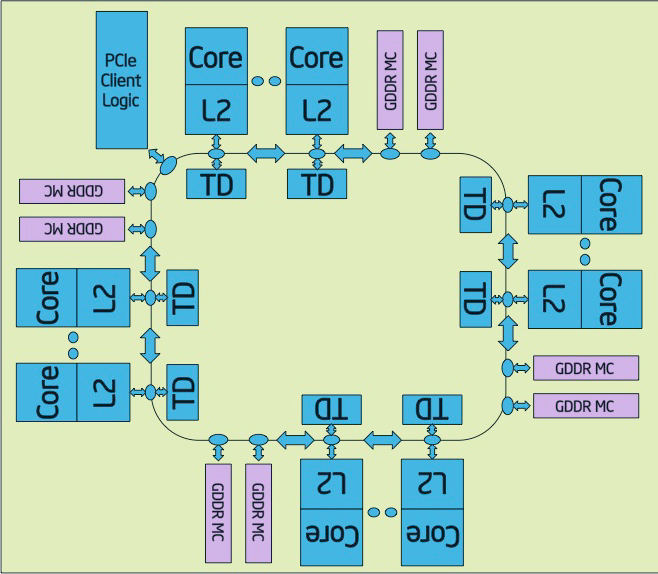
Eight memory channels (512-bit interface) support up to 8 GB of RAM, and PCIe logic is on chip.








46 Comments
View All Comments
SodaAnt - Wednesday, November 14, 2012 - link
It does support the x86 instruction set though, so it shouldn't be too hard to port.MrSpadge - Wednesday, November 14, 2012 - link
But you have to use the custom vector format to stampede anything.Kevin G - Saturday, November 17, 2012 - link
In theory it should run the current the Linux version of F@H without modification. That catch is that the current version is going to be horribly suboptimal as it doesn't natively support the 512 bit wide vector format used by the Xeon Phi. This would leave only the x87 FPU for calculations. This would allow the 60 scalar FPU's to be used but limit performance to a mere 60 GFLOP across all the cores. There maybe some weird scheduling oddities with Linux and/or F@H due to the chips ability to expose 240 logical processors to the host OS (the result would be better performance from running multiple instances in parallel instead of one large instance using 240 threads).An OpenCL version of F@H might be coaxed to working and it that would utilize the 512 bit vector units. Intel would have to have OpenCL drivers available for this to even have a chance of working. This would allow the full ~1 TFLOP performance to be utilized.
SydneyBlue120d - Wednesday, November 14, 2012 - link
Why did Intel choose a custom SIMD format? Why not AVX?Jaybus - Thursday, November 15, 2012 - link
Because they needed heavier duty vector units. Each Phi core has 32 512-bit registers, where Core i7 has 16 256-bit registers. They just didn't implement the backward compatibility, probably to reduce complexity. It is certainly possible to do, and we may indeed see AVX, SSE, etc. added in a future revision.Kevin G - Saturday, November 17, 2012 - link
The 512 bit vector instructions change how exceptions and the register masking are handled in comparison to AVX. Outside of that, the vector instructions are similar to how AVX instructions are formatted and the output complies with IEEE floating point standards. So while there is a distinct break in ISA capabilities, it does appear that it is possible to bridge the two together in future designs. Still it is odd that Intel has forked their ISA.coder543 - Wednesday, November 14, 2012 - link
I just want to know how much it will cost.Why is Intel keeping this such a ridiculous secret? Knowing Intel, these will easily be $2,000+ a piece, if not much higher, but I still want to *know.*
LogOver - Wednesday, November 14, 2012 - link
Did you read the article at all? Check the second page again.Comdrpopnfresh - Wednesday, November 14, 2012 - link
How could PCIe 3.0 result in more overhead?nutgirdle - Wednesday, November 14, 2012 - link
I concur. A major dis-advantage to co-processor computing is the time it takes to move data on and off the card. The PCIe 2.0 bus is already a bottleneck in our workflow involving a Tesla card. This was a very short-sighted omission.