Intel's Haswell Architecture Analyzed: Building a New PC and a New Intel
by Anand Lal Shimpi on October 5, 2012 2:45 AM ESTHaswell's Wide Execution Engine
Conroe introduced the six execution ports that we've seen used all the way up to Ivy Bridge. Sandy Bridge saw significant changes to the execution engine to enable 256-bit AVX operations but without increasing the back end width. Haswell does a lot here.
Just as before, I put together a few diagrams that highlight the major differences throughout the past three generations for the execution engine.
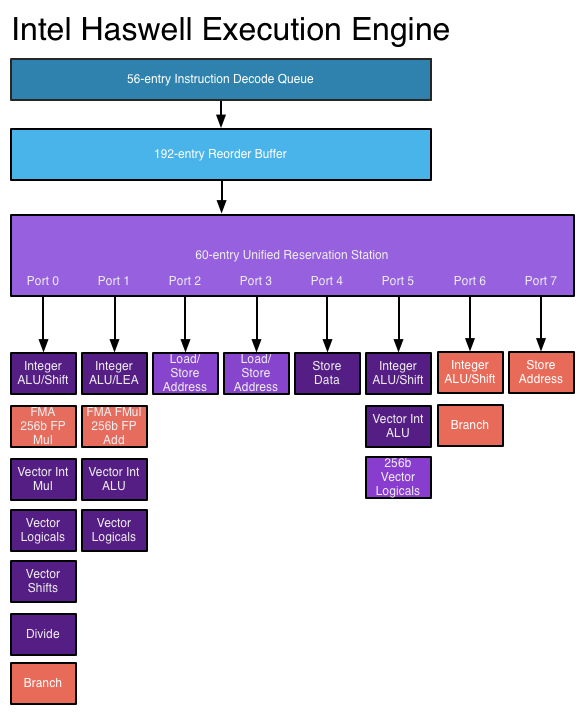
The reorder buffer is one giant tracking structure for all of the micro-ops that are in various stages of execution. The size of this buffer is directly impacted by the accuracy of the branch predictor as that will determine how many instructions can be kept in flight at a given time.
The reservation station holds micro-ops as they wait for the data they need to begin execution. Both of these structures grow by low double-digit percentages in Haswell.
Simply being able to pick from more instructions to execute in parallel is one thing, we haven't seen an increase in the number of parallel execution ports since Conroe. Haswell changes that.
From Conroe to Ivy Bridge, Intel's Core micro-architecture has supported the execution of up to six micro-ops in parallel. While there are more than six execution units in the system, there are only six ports to stacks of execution units. Three ports are used for memory operations (loads/stores) while three are on math duty. Over the years Intel has added additional types and widths of execution units (e.g. Sandy Bridge added 256-bit AVX operations) but it hasn't strayed from the 6 port architecture.
Haswell finally adds two more execution ports, one for integer math and branches (port 6) and one for store address calculation (port 7). Including both additional compute and memory hardware is a balanced decision on Intel's part.
The extra ALU and port does one of two things: either improve performance for integer heavy code, or allow integer work to continue while FP math occupies ports 0 and 1. Remember that Haswell, like its predecessors, is an SMT design meaning each core will see instructions from up to two threads at the same time. Although a single app is unlikely to mix heavy vector FP and integer code, it's quite possible that two applications running at the same time may produce such varied instructions. Having more integer ALUs is never a bad thing.
Also using port 6 is another unit that can handle x86 branch instructions. Branch heavy code can now enjoy two independent branch units, or if port 0 is occupied with other math the machine can still execute branches on port 6. Haswell moved the original Core branch unit from port 5 over to port 0, the most capable port in the system, so a branch unit on a lightly populated port makes helps ensure there's no performance regression as a result of the change.
Sandy Bridge made ports 2 & 3 equal class citizens, with both capable of being used for load or store address calculation. In the past you could only do loads on port 2 and store addresses on port 3. Sandy Bridge's flexibility did a lot for load heavy code, which is quite common. Haswell's dedicated store address port should help in mixed workloads with lots of loads and stores.
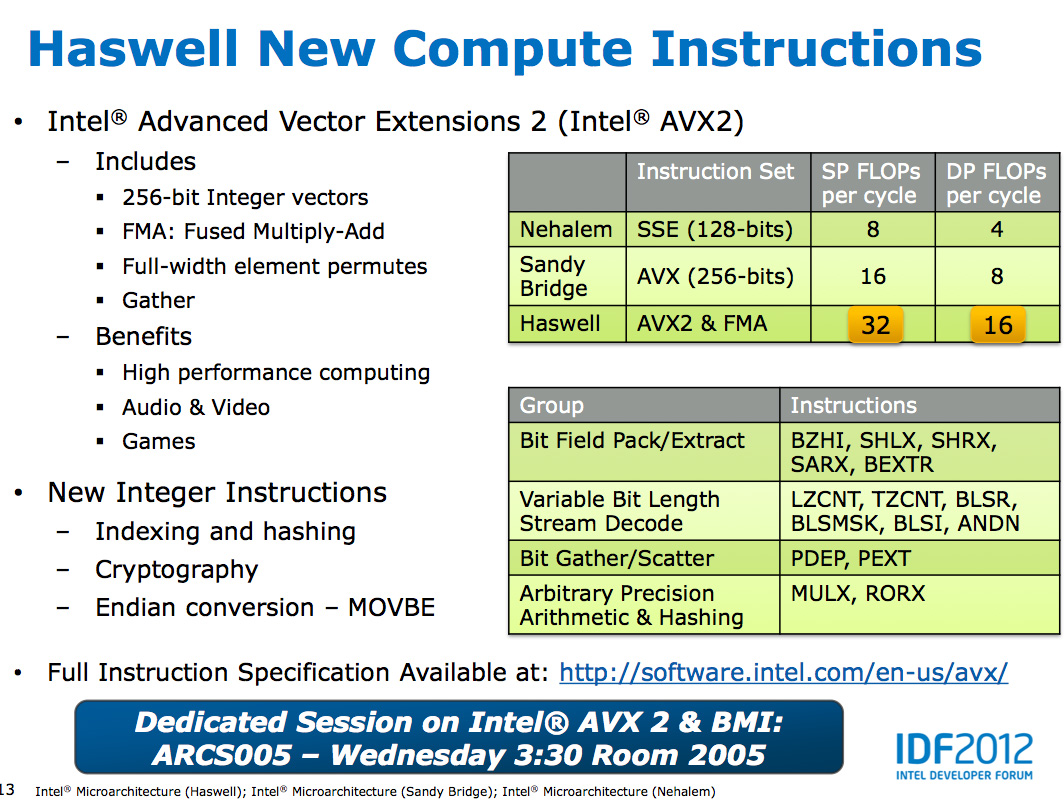
The other major addition to the execution engine is support for Intel's AVX2 instructions, including FMA (Fused Multiply-Add). Ports 0 & 1 now include newly designed 256-bit FMA units. As each FMA operation is effectively two floating point operations, these two units double the peak floating point throughput of Haswell compared to Sandy/Ivy Bridge. A side effect of the FMA units is that you now get two ports worth of FP multiply units, which can be a big boon to legacy FP code.
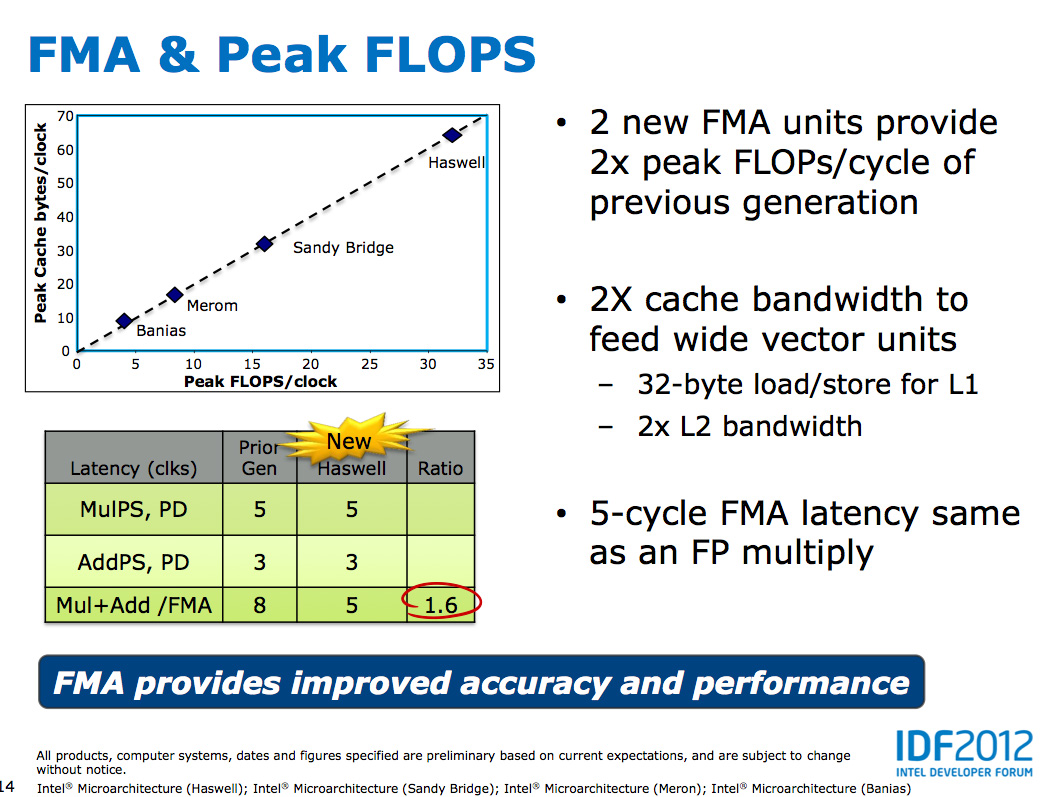
Fused Multiply-Add operations are incredibly handy in all sorts of media processing and 3D work. Rather than having to independently multiply and add values, being able to execute both in tandem via a single execution port increases the effective execution width of the machine. Note that a single FMA operation takes 5 cycles in Haswell, which is the same latency as a FP multiply from Sandy/Ivy Bridge. In the previous generation a floating point multiply+add took 8 cycles, so there's a good latency improvement here as well as the throughput boost from having two FMA units.
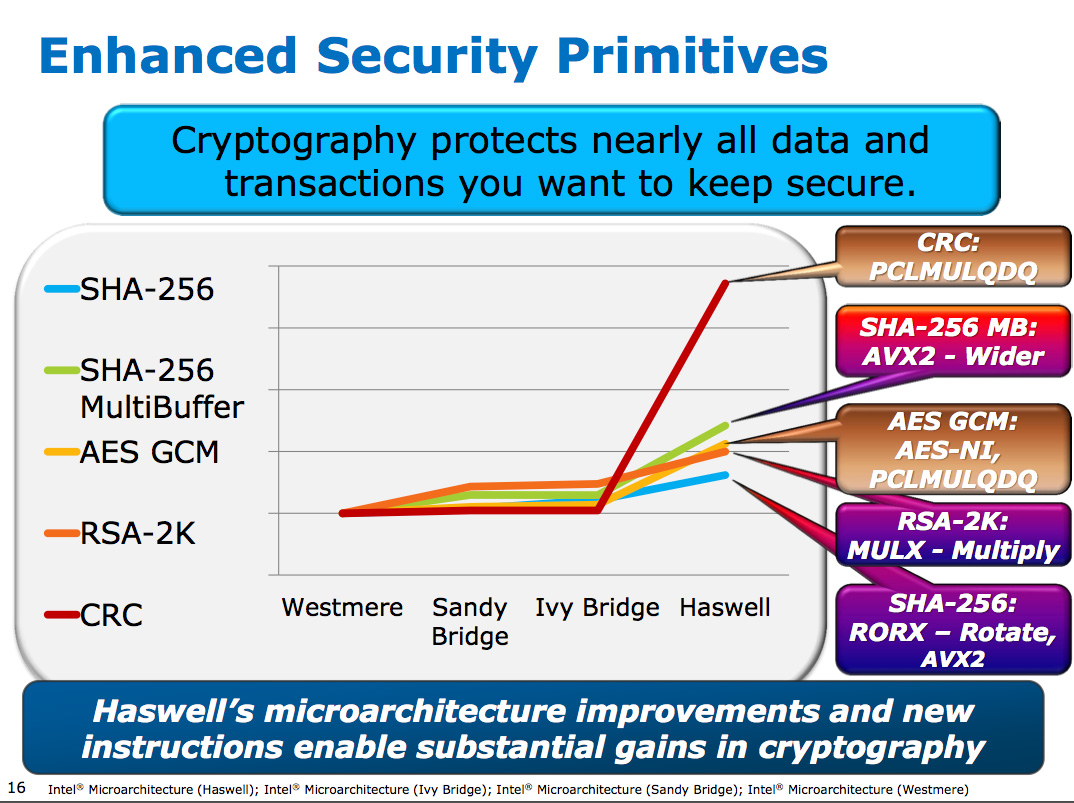
Intel focused a lot on adding more execution horsepower in Haswell without creating a power burden for legacy use cases. All of the new units can be shut off when not in use. Furthermore, Intel went in and ensured that this applied to the older execution units as well: in Haswell if you're not doing work, you're not consuming power.








245 Comments
View All Comments
Magik_Breezy - Sunday, October 14, 2012 - link
Anything delivers "solid performance" on Facebook & iWorkWhy pay $2,000 for that?
random2 - Friday, October 5, 2012 - link
I agree. admittedly I am not an apple fan and view them as people who have undergone a degree of brainwashing compounded by the need for some to keep up with the Jone's. A certain degree of mind control must be necessary to stick with a company that has had some questionable business practices as far as customer relations, dealing with product issues and denying said issues, not to mention the whole hypocritical stance by apple in regards to copyright infringement has also left a bad taste in my mouth.hasseb64 - Saturday, October 6, 2012 - link
Disagree, not that much new from already published IDF reports almost 1 month ago. What is intresting is the claimed 40 EU GT3, other sources say lower amounts.JKflipflop98 - Saturday, October 6, 2012 - link
I totally agree. It's articles like this that have kept me coming back for years. Keep up the good work Anand!tipoo - Sunday, October 7, 2012 - link
"You can expect CPU performance to increase by around 5 - 15% at the same clock speed as Ivy Bridge. "That seems terribly disappointing for a tock, even IVB as a Tick managed 10% in most cases.
medi01 - Tuesday, October 9, 2012 - link
One can't be biased !@# !@#@ and a good journalist at the same time.One needs to be blind not to see how glass is always half empty for AMD, and half full for nVidia/Intel. F**!@#'s were shameless enough, to test 45W APU with 1000W PSU and such crap is all over the place.
Paulman - Friday, October 5, 2012 - link
As I was reading this article, about part way into the low platform power sections I suddenly had this thought: "Oh man, AMD is gonna die...!"I don't know if that's true for the entire microprocessor side of AMD, since they look like they're already starting to transition out of the desktop space, but I don't know if they're going to stand much of a chance if they're planning on entering the same TDP range as Haswell.
Do you think there's a chance AMD will start focussing on designing ARM ISA cores? Or will expanding on their x86 Bobcat-type cores be enough for them?
sean.crees - Friday, October 5, 2012 - link
I also worry about AMD. AMD has been 1-2 steps behind Intel for a while now, and now it seems Intel is at least 1 or 2 steps behind ARM and the future. Is that going to mean AMD is just too far behind to stay relevant now? If nothing else, i suppose AMD can fall back on graphic cards with it's ATI acquisition.Da W - Friday, October 5, 2012 - link
If Haswell keeps x86 relevant in the tablet space and thus Windows 8 has the upper edge over Windows RT and Windows tablets can grab +-50% market share from the iPad, then it can be good for AMD, provided they survive that long.RedemptionAD - Friday, October 5, 2012 - link
If AMD can create a team to focus on increasing IPC with a goal to one up Intel and have the ATI graphics people keep doing what they do with a time goal of say 2 years, (Note: Portables/Notebooks/Desktops should all be x64 by then), then I think that AMD will be able to return to their Athlon 64 glory days or better.