Intel's Haswell Architecture Analyzed: Building a New PC and a New Intel
by Anand Lal Shimpi on October 5, 2012 2:45 AM ESTDecoupled L3 Cache
With Nehalem Intel introduced an on-die L3 cache behind a smaller, low latency private L2 cache. At the time, Intel maintained two separate clock domains for the CPU (core + uncore) and a third for what was, at the time, an off-die integrated graphics core. The core clock referred to the CPU cores, while the uncore clock controlled the speed of the L3 cache. Intel believed that its L3 cache wasn't incredibly latency sensitive and could run at a lower frequency and burn less power. Core CPU performance typically mattered more to most workloads than L3 cache performance, so Intel was ok with the tradeoff.
In Sandy Bridge, Intel revised its beliefs and moved to a single clock domain for the core and uncore, while keeping a separate clock for the now on-die processor graphics core. Intel now felt that race to sleep was a better philosophy for dealing with the L3 cache and it would rather keep things simple by running everything at the same frequency. Obviously there are performance benefits, but there was one major downside: with the CPU cores and L3 cache running in lockstep, there was concern over what would happen if the GPU ever needed to access the L3 cache while the CPU (and thus L3 cache) was in a low frequency state. The options were either to force the CPU and L3 cache into a higher frequency state together, or to keep the L3 cache at a low frequency even when it was in demand to prevent waking up the CPU cores. Ivy Bridge saw the addition of a small graphics L3 cache to mitigate this situation, but ultimately giving the on-die GPU independent access to the big, primary L3 cache without worrying about power concerns was a big issue for the design team.
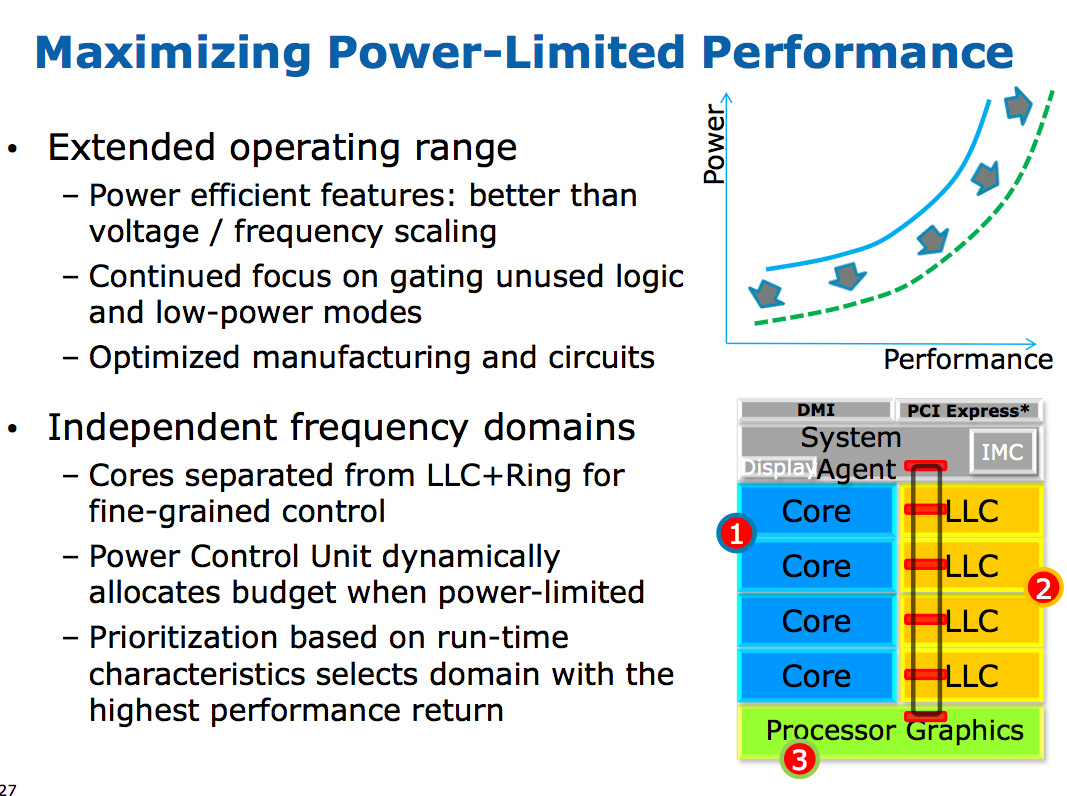
When it came time to define Haswell, the engineers once again went to Nehalem's three clock domains. Ronak (Nehalem & Haswell architect, insanely smart guy) tells me that the switching between designs is simply a product of the team learning more about the architecture and understanding the best balance. I think it tells me that these guys are still human and don't always have the right answer for the long term without some trial and error.
The three clock domains in Haswell are roughly the same as what they were in Nehalem, they just all happen to be on the same die. The CPU cores all run at the same frequency, the on-die GPU runs at a separate frequency and now the L3 + ring bus are in their own independent frequency domain.
Now that CPU requests to L3 cache have to cross a frequency boundary there will be a latency impact to L3 cache accesses. Sandy Bridge had an amazingly fast L3 cache, Haswell's L3 accesses will be slower.
The benefit is obviously power. If the GPU needs to fire up the ring bus to give/get data, it no longer has to drive up the CPU core frequency as well. Furthermore, Haswell's power control unit can dynamically allocate budget between all areas of the chip when power limited.
Although L3 latency is up in Haswell, there's more access bandwidth offered to each slice of the L3 cache. There are now dedicated pipes for data and non-data accesses to the last level cache.
Haswell's memory controller is also improved, with better write throughput to DRAM. Intel has been quietly telling the memory makers to push for even higher DDR3 frequencies in anticipation of Haswell.








245 Comments
View All Comments
Penti - Saturday, October 6, 2012 - link
Also FPU/SIMD has been a large part in later ARM designs and implementations. It's really a big deal as we saw with the chips lacking some of those parts. You shouldn't forget how important those bits are. Others have failed because they didn't take it seriously. That was 15-20 years ago even. Doesn't mean they are yet fighting x86-64 chips in high-end servers and workstation though. We will certainly see them entering that market by 2015 though.Arbee - Friday, October 5, 2012 - link
Cortex A9's big IPC improvement came from going out-of-order, which kind of ruins your argument.Similarly, the X360/PS3 PowerPC chips are strict in order and super ultra slow as a result - at 3.2 GHz they can't match a PowerMac G5 with out-of-order at 2.2 GHz. But I suspect that wasn't the point - Sony and MS can claim the eye-popping (in 2006) 3.2 GHz figure, and the heat production is certainly less than a PPC G5.
wumpus - Friday, October 5, 2012 - link
Has anyone seen an A9 in the wild? I don't doubt huge IPC improvements (back when O-O-O was new, it tended to double performance). My statement is that it will kill GIPS/W and that Intel can much more easily design a chip that can beat it in both raw performance and GIPS/W (note that your mention of heat production agrees with me).Also note I suspect that the goal of A9 is to keep the power low enough to keep it out of where Intel wants to go. A rough guess is that ARM might have a chance with dual issue o-o-o, but past that (roughly where Pentium Pro was designed) they can't really go.
ElvenLemming - Friday, October 5, 2012 - link
The Cortex A9 has been in most major phone/tablet SoCs for the past two or so years. Apple's A5, A5X; Samsung's Exynos 4210, 4212, 4412; TI's OMAP 4 series; Nvidia's Tegra 2 and 3.Cortex A15 is probably what you were thinking of that we've yet to see out in the wild. It's out-of-order like the A9, but with a great deal of other improvements.
ericore - Friday, October 5, 2012 - link
Currently AMD has the upper hand on the notebook segment on battery life. Haswell changes that, but as is always the case with Intel, they will be pricey. And that's why AMD will still have 50% of the market because vendors are cheap.Power savings are much less relevant on desktop front; I don't care so much about power as i do of heat. AMD X4 700, ship an awsome 4 core cpu for 75$. Technically, it has all that you need from a CPU. Add a Radeon 7770 (again cheap) and your golden. Ya Intel is faster, but both Intel and Nvidia have shitty low end products and that's even more true when you think of atom. 5-15% single threaded performance is not anything that is going to burry AMD lol.
On top of that, AMD has an atom KILLER, a contracts with all major console vendors.
Haswell will have surprisingly little impact on AMD; what I am saying is if you look at your own expectations, you'll realize they were highly inflated and you'll wonder why it didn't do more damage to AMD. I've explained the why. Nevertheless broadwell is a significant threat, and we'll probably see AMD start to lose market share (much more than with haswell) unless AMD can fight back and it will; but nobody knows if it will be enough.
A5 - Friday, October 5, 2012 - link
Uh, wow.Zink - Saturday, October 6, 2012 - link
http://www.tomshardware.com/reviews/gaming-cpu-rev...tipoo - Friday, October 5, 2012 - link
"Overall performance gains should be about 2x for GT3 (presumably with eDRAM) over HD 4000 in a high TDP part."Does this mean the regular GT3 without eDRAM cache will be twice the performance of the HD4000 and the one with the cache will be 4x? Or that the one with the cache will be 2x? In which case, what would the one with no cache perform like, with so many more EUs the first is probably correct, right?
tipoo - Friday, October 5, 2012 - link
"presumably with eDRAM"...So the GT3 in Haswel has over double the EUs of Ivy Bridge, but without the cache it doesn't even get to 2x the performance? Seems off to me, doesn't it seem like the GT3 on its own would be 2x the performance while the eDRAM cache would make for another 2x?DanNeely - Saturday, October 6, 2012 - link
It probably means that, like AMD, Intel is hitting the wall on memory bandwidth for IGPs. When it finally arrives, DDR4 will shake things up a bit; but DDR3 just isn't fast enough.