Intel's Haswell Architecture Analyzed: Building a New PC and a New Intel
by Anand Lal Shimpi on October 5, 2012 2:45 AM ESTThe Haswell Front End
Conroe was a very wide machine. It brought us the first 4-wide front end of any x86 micro-architecture, meaning it could fetch and decode up to 4 instructions in parallel. We've seen improvements to the front end since Conroe, but the overall machine width hasn't changed - even with Haswell.
Haswell leaves the overall pipeline untouched. It's still the same 14 - 19 stage pipeline that we saw with Sandy Bridge depending on whether or not the instruction is found in the uop cache (which happens around 80% of the time). L1/L2 cache latencies are unchanged as well. Since Nehalem, Intel's Core micro-architectures have supported execution of two instruction threads per core to improve execution hardware utilization. Haswell also supports 2-way SMT/Hyper Threading.
The front end remains 4-wide, although Haswell features a better branch predictor and hardware prefetcher so we'll see better efficiency. Since the pipeline depth hasn't increased but overall branch prediction accuracy is up we'll see a positive impact on overall IPC (instructions executed per clock). Haswell is also more aggressive on the speculative memory access side.
The image below is a crude representation I put together of the Haswell front end compared to the two previous tocks. If you click the buttons below you'll toggle between Haswell, Sandy Bridge and Nehalem diagrams, with major changes highlighted.
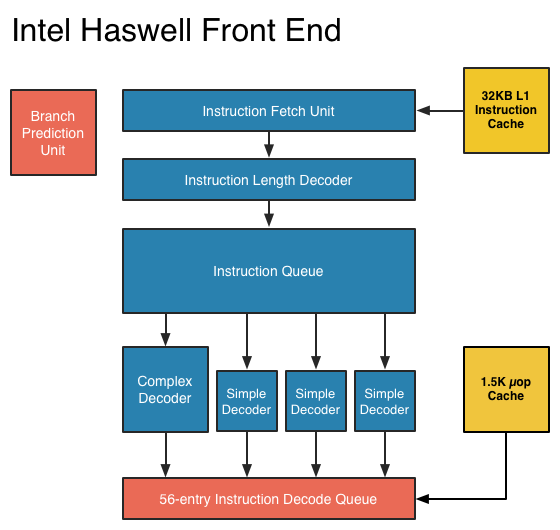
In short, there aren't many major, high-level changes to see here. Instructions are fetched at the top, sent through a bunch of steps before getting to the decoders where they're converted from macro-ops (x86 instructions) to an internally understood format known to Intel as micro-ops (or µops). The instruction fetcher can grab 4 - 5 x86 instructions at a time, and the decoders can output up to 4 micro-ops per clock.
Sandy Bridge introduced the 1.5K µop cache that caches decoded micro-ops. When future instruction fetch requests are made, if the instructions are contained within the µop cache everything north of the cache is powered down and the instructions are serviced from the µop cache. The decode stages are very power hungry so being able to skip them is a boon to power efficiency. There are also performance benefits as well. A hit in the µop cache reduces the effective integer pipeline to 14 stages, the same length as it was in Conroe in 2006. Haswell retains all of these benefits. Even the µop cache size remains unchanged at 1.5K micro-ops (approximately 6KB in size).
Although it's noted above as a new/changed block, the updated instruction decode queue (aka allocation queue) was actually one of the changes made to improve single threaded performance in Ivy Bridge.
The instruction decode queue (where instructions go after they've been decoded) is no longer statically partitioned between the two threads that each core can service.
The big changes in Haswell are at the back end of the pipeline, in the execution engine.








245 Comments
View All Comments
kukreknecmi - Friday, October 5, 2012 - link
I hope i know it right. L3 on SB/IB doest used by GPU. L3 still servers as cache on system via memory controller. If GPU nneds to acess to memory, it sends request to memory controller. L3 is not directly accessable to GPU as a texture cache etc.On IB, they added a 512k cache which is seperated to half, 256k of it is used as texture system as backfeeding and other 256k half is used for other things.Article implies that L3 cache on IB is used as a texture buffer like on ordinary graphic cards. Only on Haswell L3 cache will be accessable and can be used as a some kind of GPU specific buffer.
Kevin G - Friday, October 5, 2012 - link
The confusing thing is that consumer Ivy Bridge parts have a L3 cache just for the GPU which is separate memory than the L3 cache that the CPU uses. The Ivy Bridge GPU's can use the CPU's L3 cache as the GPU's L4 cache to a degree.To confuse things further, the CPU side really has four levels of cache too. There is the small 1.5 KB micro-uop cache for instructions which comes before the 32 KB L1 instruction cache.
mayankleoboy1 - Friday, October 5, 2012 - link
From the article, its not very clear : Which platform (DT, Mobile, ultra mobile) will have the integrated voltage regulators/controllers ?Ryan Smith - Friday, October 5, 2012 - link
Ultra Mobile.Anand Lal Shimpi - Friday, October 5, 2012 - link
It's not clear how much of the VR circuitry gets integrated into Haswell or necessarily which parts will have it and which ones won't. Ultra mobile is a shoe in, but I've even heard of desktop parts getting it as well. We'll have to wait and see.DanNeely - Friday, October 5, 2012 - link
Rats. Reading the article I was hoping that Intel had decided to only bake the VRMs into their ultra-mobile parts. Better VRMs are an important factor in high end OCing; with desktop boards not cramped for space I really hope Intel keeps them off the package.Peanutsrevenge - Friday, October 5, 2012 - link
Seconded.However, I wonder whether the VRMs on high end mobos will still be an option, where the on package VRMs will simply extend the capabilities?
But given Intels recent distaste for overclocking, it wouldn't suprise me if we'll soon see CPUs completely locked from overclocking completely or only on E series, high profit chips.
Homeles - Saturday, October 6, 2012 - link
"However, I wonder whether the VRMs on high end mobos will still be an option, where the on package VRMs will simply extend the capabilities?"Bingo.
Homeles - Saturday, October 6, 2012 - link
Low end motherboards won't need them. High end overclocking boards will have them in addition to the ones on package.tuxRoller - Friday, October 5, 2012 - link
Using lvds reclocking you can reduce idle screen induced wakeups to 30 (ditto for the memory controller if the cpu supports self refresh for the sram ).eDP may allow even less.