A Look at Enterprise Performance of Intel SSDs
by Anand Lal Shimpi on February 8, 2012 6:36 PM EST- Posted in
- Storage
- IT Computing
- SSDs
- Intel
Case Study: SSDs in AnandTech's Server Environment
For the majority of the history of AnandTech we've hosted our own server infrastructure. A benefit of running our own infrastructure is that we're able to gain a lot of hands on experience with enterprise environments that we'd otherwise have to report on from a distance.
When I first started covering SSDs four years ago I became obsessed with the idea of migrating nearly every system over to something SSD based. The first to make the switch were our CPU testbeds. Moving away from mechanical drives ensured better benchmark consistency between runs as any variation in IO load was easily absorbed by the tremendous amount of headroom that an SSD offered. The holy grail of course was migrating all of the AnandTech servers over to SSDs. Over the years our servers seem to die in the following order: hard drives, power supplies, motherboards. We tend to stay on a hardware platform until the systems start showing the signs of their age (e.g. motherboards start dying), but that's usually long enough that we encounter an annoying number of hard drive failures. A well validated SSD should have a predictable failure rate, making it an ideal candidate for an enterprise environment where downtime is quite costly and in the case of a small business, very annoying.

Our most recent server move is a long story for a separate article but to summarize the move, we recently switched hosting providers and data centers. Our hardware was formerly on the east coast and the new datacenter is in the middle of the country. At our old host we were trying out a new cloud platform while our new home would be a mixture of a traditional back-end with a virtualized front-end. With a tight timetable for the move and no desire to deploy an easily portable solution at our old home before making the move we were faced with a difficult task: how do we physically move our servers half way across the country with minimal downtime?
Thankfully our new host had temporary hardware very similar in capabilities to our new infrastructure that they were willing to put the site on as we moved our hardware. The only exception was, as you might guess, a relative lack of SSDs. Our new hardware uses a combination of consumer and enterprise SSDs but our new host only had mechanical drives or consumer grade SSDs on tap (Intel SSD 320s). The fact that we had run the site's databases off of a mechanical drive array for years meant that even a small number of consumer drives should be more than capable of handling the load. Remembering back to some of our earliest lessons in the SSD space: a single solid state drive can offer an order of magnitude better random IO performance than even the fastest hard drives. Sequential performance is typically closer, but with modern 3Gbps SSDs you're still looking at roughly a 100MB/s advantage in sequential throughput over the fastest mechanical drives.

Not wanting to deal with any potential IO performance issues, we decided to deploy a bunch of consumer grade Intel SSDs on our temporary DB servers that our host had on hand. This isn't uncommon, in fact a huge percentage of enterprise workloads are served just fine by consumer SSDs. It's only the absolute heaviest of workloads that demand eMLC or SLC drives. Given that we were going to stay on this platform for a short period of time, there was no need for eMLC/SLC drives. As we know from years of dealing with SSDs, NAND cells have a finite lifespan. Consumer grade MLC NAND is good for about 5000 program/erase cycles per cell, while enterprise grade MLC (eMLC/MLC-HET) can get you over 6x that. While most client workloads won't ever hit 5000 p/e cycles, a heavy enough enterprise workload can definitely reach that point. It's not just the amount of writing you do, it's also how much each write is amplified. Remember that although NAND is programmed at the page level (4KB - 8KB), it can only be erased at the block level (512KB - 2048KB). This imbalance in write/erase granularity means that eventually you'll have to write more to NAND than you've sent to the host (e.g. go to write 8KB but have to read, modify, write an entire 2048KB block as there are no empty blocks to write to). The ratio of NAND to host writes is referred to as write amplification. The combination of workload and write amplification are what determine the longevity of any SSD, but in the enterprise world it's something you actually need to pay attention to.
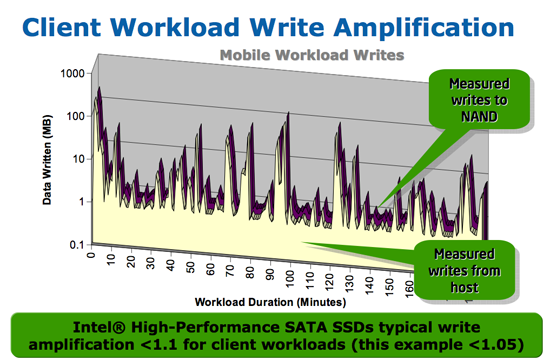
Write amplification around 1 may be realistic for client (read heavy) workloads, but not in the enterprise
Our host had eight Intel SSD 320s (120GB) on hand that we could use for our temporary database servers. From a performance standpoint these drives should be more than enough to handle our workload, but would they be reliable?
The easiest way to combat write amplification is to increase the amount of spare area on an SSD. NAND that isn't user addressable can be used for background operations and will help ensure that there are empty blocks to be written to as often as possible. If writes happen on empty vs. full blocks, write amplification goes down considerably.
We deployed the Intel SSD 320s partitioned down to 100GB each. Curious as to how they've been holding up over the past ~9 days that they've been running as our primary environment, I installed and ran Intel's SSD Toolbox on our DB servers.
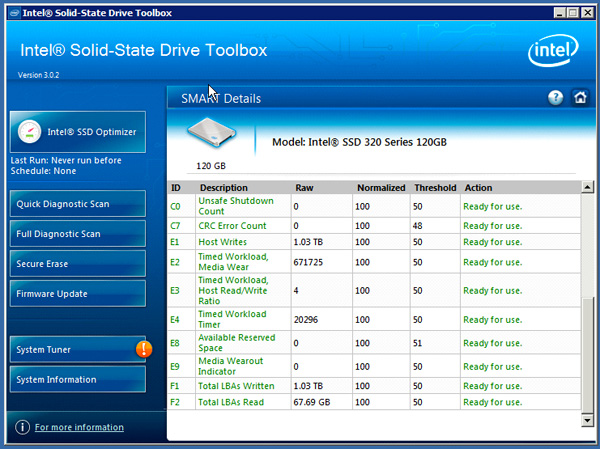
As I mentioned in our review of Intel's SSD 710 you can actually measure things like write amplification, host writes and estimated lifespan using SMART attributes on the latest Intel SSDs. This won't work on the Intel SSD 510, X25-E or first generation X25-M, but on all other Intel SSDs it will.
The attributes of importance are E1, E2, E3 and E4 (these are hex representations of the SMART attribute numbers 225 - 228). E2 - E4 are all timer dependent, while E1 gives you an indication of just how much you've written to the NAND over the life of the drive. I'll get into the timer based counters shortly, but when we originally setup the servers I didn't have the foresight to reset the counters to get an accurate estimate of write amplification on our workload. Instead I'll look at total bytes written and use some internal estimates for write amplification to gauge lifespan.
The eight drives are divided among two database servers running two different applications (one for the main site and one for the forums/ads). The latter more heavily loaded but both are pretty demanding. The four drives are configured in a RAID10 to increase capacity and offer some redundancy. A simple RAID1 of larger drives would be fine, but 120GB drives are all we had on hand at the time. The total number of writes across all of the drives for the past 9 days is documented in the table below:
| AnandTech Database Server SSD Workload | ||||
| SMART Attribute E1 | MS SQL Server (Main Site DB) | MySQL Server (Forums/Ads DB) | ||
| Drive 0 | 576.28GB | 1.03TB | ||
| Drive 1 | 563.28GB | 1.03TB | ||
| Drive 2 | 564.44GB | 1.13TB | ||
| Drive 3 | 568.03GB | 1.13TB | ||
Each drive in the first DB server has seen around 570GB of writes in 9 days, or roughly 63GB/day. The drives in the second DB server have gone through 1.03TB of writes in the same period of time or 114GB/day. Note that both workloads are an order of magnitude greater than an average consumer workload of 5 - 10GB/day. That's not to say that we can't run these workloads on consumer SSDs, we just need to be careful.
With no write amplification we could run on these consumer drives indefinitely. With each MLC NAND cell good for 5000 program/erase cycles, we could write to the drives 5000 times over before we started to lose NAND. Based on the numbers above, we'd blow through a p/e cycle every ~2 days on the first DB server and every ~1 day on the second server.
While we like to assume write amplification is nice and low, in reality it isn't. Intel's own datasheets tell us the worst case write amplification for the 320:
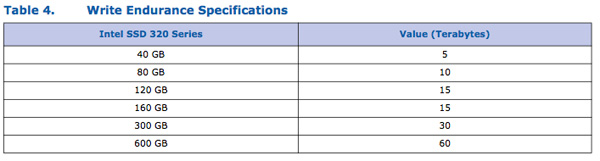
If you divide the column on the right by the column on the left you'll come up with 125 program/erase cycles per cell (if you define 1TB as one trillion bytes). If we assume that each cell is good for 5000 p/e cycles (Intel's 25nm MLC NAND spec) then it means that we're actually writing 40x what we think we're writing. This 40x value gives us an upper bound for write amplification on Intel's SSD 320. That's far lower than the peak theoretical max write amplification of 256 (writing 2048KB for every 8KB write sent to the host), but it's safe to say that Intel's firmware won't let things get that bad.
Write amplification of 40x isn't very good but it's also not very realistic for the majority of workloads. Our database workloads are heavy but they are not perfectly random writes over all LBAs for the life of the drive. Those workloads do exist, but we're simply not an example of one. A more realistic, but still conservative estimate for write amplification in our case would be 10x (just based on some internal estimates for write amplification). The actual write amp is likely less than half that but again, I wanted to be conservative.
Calculating longevity based on this data is pretty simple. Multiply the total bytes written by estimated write amplification and that's how we can scale up/down:
| Intel SSD 320 - 120GB - SSD Longevity | ||||
| MS SQL Server (Main Site DB) | MySQL Server (Forums/Ads DB) | |||
| Total Bytes Written (9 days) | 576GB | 1030GB | ||
| Estimated Write Amplification | 10x | 10x | ||
| Drive Capacity | 120GB | 120GB | ||
| Cycles Used | 48 | 85.8 | ||
| Cycles Used per Day | 5.33 | 9.53 | ||
| Worst Case P/E Cycles Available | 5000 | 5000 | ||
| Estimated Lifespan (Days) | 937.5 | 524.3 | ||
| Estimated Life (Years) | 2.57 years | 1.44 years | ||
With 10x write amplification we're looking at roughly 2.5 years for one set of drives and 1.4 years for the other set. From a cost standpoint, it's likely cheaper to go the consumer drive route and proactively replace drives compared to jumping to eMLC although that's not always desirable from an uptime perspective. If our write amplification estimates are off (they are) then you can expect something more along the lines of 5 years for the first set of drives and 3 for the second set.
We could combat write amplification by setting aside even more spare area for the drives. Partitioning them as 80GB or even 60GB drives would tangibly reduce write amplification and give us even more time on these consumer drives.
This isn't so much an issue for us as our stay on the 320s is temporary, but it did bring up an interesting question. As enterprise SSD endurance is heavily dependent on write amplification, how would Intel's SandForce based SSD 520 handle enterprise workloads given that its effective write amplification is often times less than 1x?
If you were able to average 0.5x write amplification with Intel's SSD 520, your 5000 p/e cycle MLC NAND would behave more like 10000 p/e cycle NAND. While that's still short of what you get from eMLC, it is perhaps enough to be a better balance of price/performance for many SMB enterprise customers.
It was time to do some investigating...








55 Comments
View All Comments
ckryan - Thursday, February 9, 2012 - link
Very true. And again, many 60/64GB could do 1PB with an entirely sequential workload. Under such conditions, most non-SF drives typically experience a WA of 1.10 to 1.20.Reality has a way of biting you in the ass, so in reality, be conservative and reasonable about how long a drive will last.
No one will throw a parade if a drive lasts 5 years, but if it only lasts 3 you're gonna hear about it.
ckryan - Thursday, February 9, 2012 - link
The 40GB 320 failed with almost 700TB, not 400. Remember though, the workload is mostly sequential. That particular 320 40GB also suffered a failure of what may have been an entire die last year, and just recently passed on to the SSD afterlife.So that's pretty reassuring. The X25-V is right around 700TB now, and it's still chugging along.
eva2000 - Thursday, February 9, 2012 - link
Would be interesting to see how consumer drives in the tests and life expectancy if they are configured with >40% over provisioning.vectorm12 - Thursday, February 9, 2012 - link
Thanks for the insight into this subject Anand.However I am curios as to why controller manufacturers haven't come up with a controller to manage cell-wear across multiple drives without raid.
Basically throw more drives at a problem. As you would be to some extent be mirroring most of your P/E cycles in a traditional raid I feel there should be room for an extra layer of management. For instance having a traditional raid 1 between two drive and keeping another one or two as "hot spare" for when cells start to go bad.
After all if you deploy SSD in raid you're likely to be subjecting them to a similar if not identical number of P/E cycles. This would force you to proactively switch out drives(naturally most would anyway) in order to guarantee you won't be subjected to a massive, collective failure of drives risking loss of data.
Proactive measures are the correct way of dealing with this issue but in all honesty I love "set and forget" systems more than anything else. If a drive has exhausted it's NAND I'd much rather get an email from a controller telling me to replace the drive and that it's already handled the emergency by allocating data to a spare drive.
Also I'm still seeing 320 8MB-bugg despite running the latest firmware in a couple of servers hosting low access-rate files for some strange reason. It seems as though they behave fine as long as the are constantly stressed but leave them idle for too long and things start to go wrong. Have you guys observed anything like this behavior?
Kristian Vättö - Thursday, February 9, 2012 - link
I've read some reports of the 8MB bug persisting even after the FW update. Your experience sounds similar - problems start to occur when you power off the SSD (i.e. power cycling). A guy I know actually bought the 80GB model just to try this out but unfortunately he couldn't make it repeatable.vectorm12 - Monday, February 13, 2012 - link
Unfortunately I'm in the same boat. 320s keep failing left and right(up to three now) all running latest firmware. However the issues aren't directly related to powercycles as these drives run 24/7 without any offtime.I've made sure drive-spinndown is deactivated as well as all other powermanagement features I could think of. I've also move the RAIDs from Adaptec controllers to the integrated SAS-controllers and still had a third drive fail.
I've actually switched out the remaining 320s for Samsung 830s now to see how they behave in this configuration.
DukeN - Thursday, February 9, 2012 - link
One with RAID'd drives, whether on a DAS or a high end SAN?Would love to see how 12 SSDs in (for argument's sake) an MSA1000 compare to 12 15K SAS drives.
TIA
ggathagan - Thursday, February 9, 2012 - link
Compare in what respect?FunBunny2 - Thursday, February 9, 2012 - link
Anand:I've been thinking about the case where using SSD, which has calculable (sort of, as this piece describes) lifespan, as swap (linux context). Have you done (and I can't find) or considering doing, such an experiment? From a multi-user, server perspective, the bang for the buck might be very high.
varunkrish - Thursday, February 9, 2012 - link
I have recently seen 2 SSDs fail without warning and they are completely not detected currently. While I love the performance gains from an SSD , lower noise and cooler operation, i feel you have to be more careful while storing critical data on a SSD as recovery is next to impossible.I would love to see an article which addresses SSDs from this angle.