AMD Radeon HD 7970 Review: 28nm And Graphics Core Next, Together As One
by Ryan Smith on December 22, 2011 12:00 AM EST- Posted in
- GPUs
- AMD
- Radeon
- ATI
- Radeon HD 7000
Partially Resident Textures: Not Your Father’s Megatexture
John Carmack’s id Software may not be the engine licensing powerhouse it was back in the Quake 3 days, but that hasn’t changed the revolutionary nature of his engine designs. The reason we bring this up is because there’s a great deal of GPU technology that can be directly mapped to concepts Carmack first implemented. For id Tech 4 Carmack implemented shadow volume technology, which was then first implemented in hardware by NVIDIA as their UltraShadow technology, and has since then been implemented in a number of GPUs. For id Tech 5 the trend has continued, now with AMD doing a hardware implementation of a Carmack inspired technology.
Among the features added to Graphics Core Next that were explicitly for gaming, the final feature was Partially Resident Textures, which many of you are probably more familiar with in concept as Carmack’s MegaTexture technology. The concept behind PRT/Megatexture is that rather than being treated as singular entities, due to their size textures should be broken down into smaller tiles, and then the tiles can be used as necessary. If a complete texture isn’t needed, then rather than loading the entire texture only the relevant tiles can be loaded while the irrelevant tiles can be skipped or loaded at a low quality. Ultimately this technology is designed to improve texture streaming by streaming tiles instead of whole textures, reducing the amount of unnecessary texture data that is streamed.

Currently MegaTexture does this entirely in software using existing OpenGL 3.2 APIs, but AMD believes that more next-generation game engines will use this type of texturing technology. Which makes it something worth targeting, as if they can implement it faster in hardware and get developers to use it, then it will improve game performance on their cards. Again this is similar to volume shadows, where hardware implementations sped up the process.
In order to implement this in hardware AMD has to handle two things: texture conversion, and cache management. With texture conversion, textures need to be read and broken up into tiles; AMD is going with a texture format agnostic method here that can simply chunk textures as they stand, keeping the resulting tiles in the same format. For AMD’s technology each tile will be 64KB, which for an uncompressed 32bit texture would be enough room for a 128 x 128 chunk.
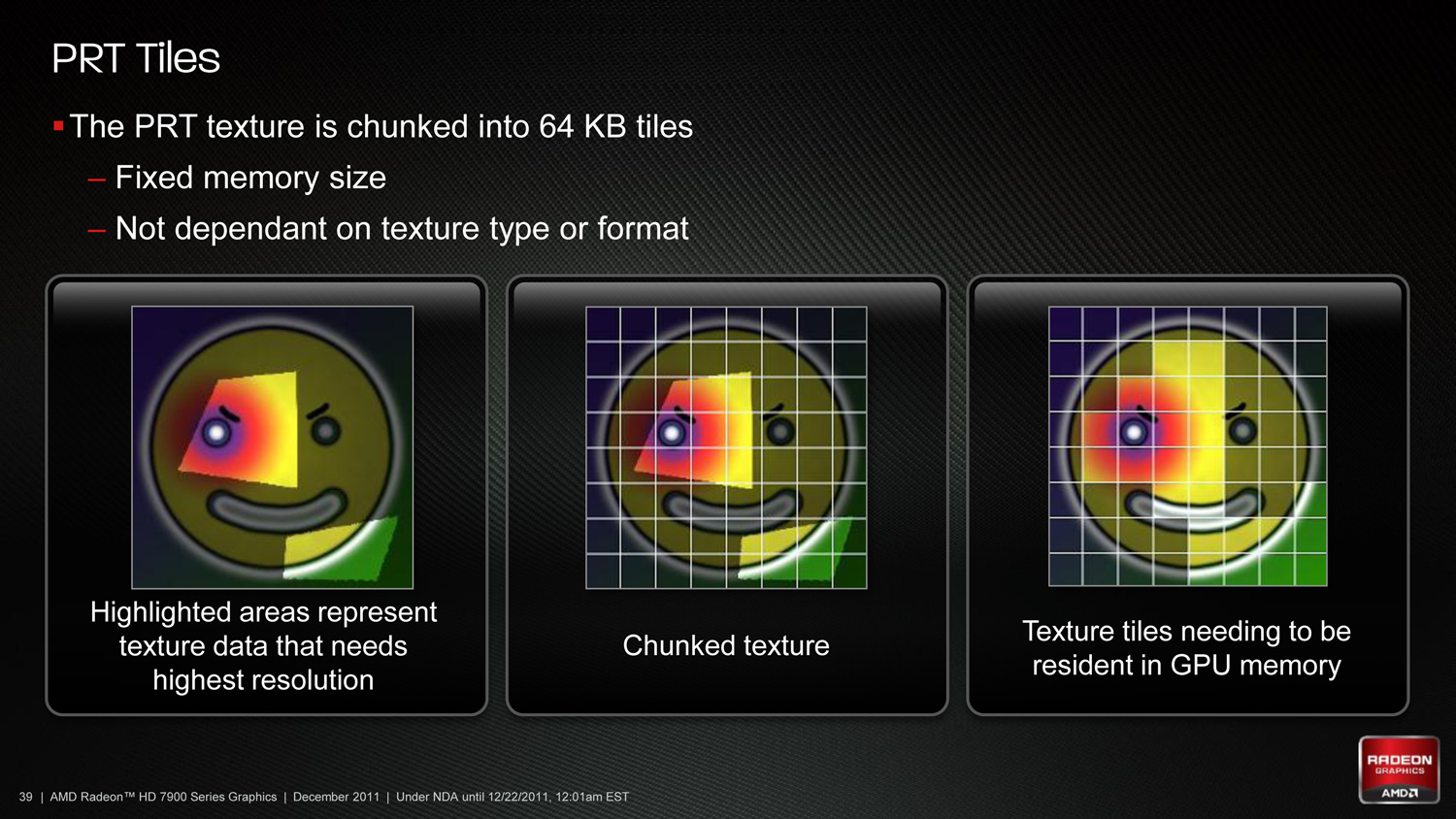
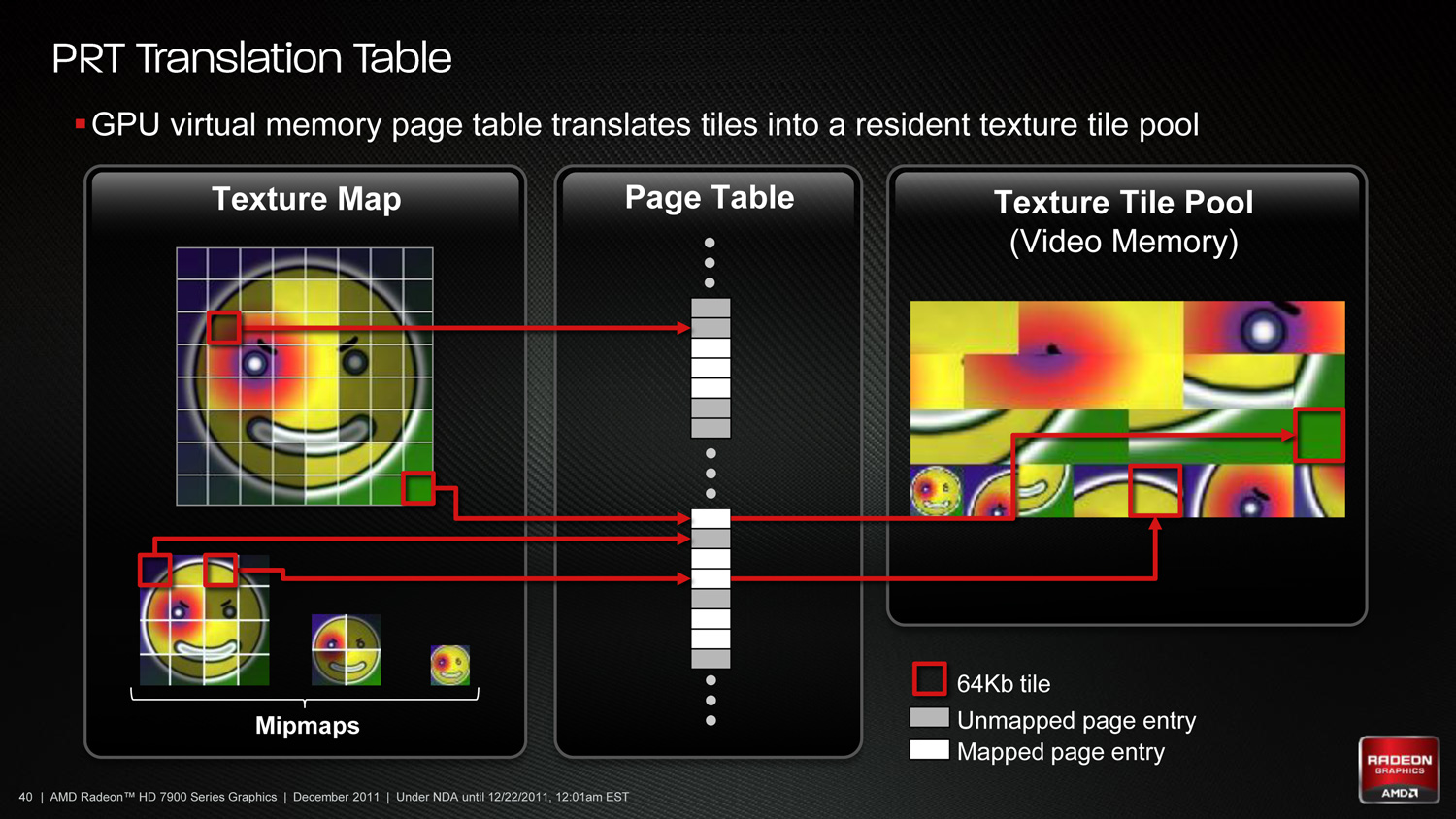
The second aspect of PRT is managing the tiles. In essence PRT reduces local video memory to a very large cache, where tiles are mapped/pinned as necessary and then evicted as per the cache rules, and elsewhere the hardware handles page/tile translation should a tile not already be in the cache. Large tomes have been written on caching methods, and this aspect is of particular interest to AMD because what they learn about caching here they can apply to graphical workloads (i.e. professional) and not just gaming.
To that end AMD put together a technology demo for PRT based on Per-Face Texture Mapping (PTEX), a Disney-developed texture mapping technique that maps textures to polygons in a 1:1 ratio. Disney uses this technique for production rendering, as by constraining textures to a single polygon they don’t have to deal with any complexities that arise as a result of mapping a texture over multiple polygons. In the case of AMD’s demo it not only benefits for the reasons that Disney uses it, but also because when combined with tessellation it trivializes vector displacement, making art generation for tessellated games much easier to create. Finally, PRT fits into all of this by improving the efficiency of accessing and storing the Ptex texture chunks.
Wrapping things up, for the time being while Southern Islands will bring hardware support for PRT software support will remain limited. As D3D is not normally extensible it’s really only possible to easily access the feature from other APIs (e.g. OpenGL), which when it comes to games is going to greatly limit the adoption of the technology. AMD of course is working on the issue, but there are few ways around D3D’s tight restrictions on non-standard features.











292 Comments
View All Comments
Zingam - Thursday, December 22, 2011 - link
I think this card is a kinda fail. Well, maybe it is a driver issue and they'll up the performance 20-25% in the future but it is still not fast enough for such huge jump - 2 nodes down!!!It smell like a graphics Bulldozer for AMD. Good ideas on paper but in practice something doesn't work quite right. Raw performance is all that counts (of course raw performance/$).
If NVIDIA does better than usual this time. AMD might be in trouble. Well, will wait and see.
Hopefully they'll be able to release improved CPUs and GPUs soon because this generation does not seem to be very impressive.
I've expected at least triple performance over the previous generation. Maybe the drivers are not that well optimized yet. After all it is a huge architecture change.
I don't really care that much about that GPU generation but I'm worried that they won't be able to put something impressively new in the next generation of consoles. I really hope that we are not stuck with obsolete CPU/GPU combination for the next 7-8 years again.
Anyway: massively parallel computing sounds tasty!
B3an - Thursday, December 22, 2011 - link
You dont seem to understand that all them extra transistors are mostly there for computing. Thats mostly what this was designed for. Not specifically for gaming performance. Computing is where this card will offer massive increases over the previous AMD generation.Look at Nvidia's Fermi, that had way more transistors than the previous generation but wasn't that much faster than AMD's cards at the time. Because again all the extra transistors were mainly for computing.
And come on LOL, expecting over triple the performance?? That has never happened once with any GPU release.
SlyNine - Friday, December 23, 2011 - link
The 9700pro was up to 4x faster then the 4600 in certian situations. So yes it has happened.tzhu07 - Thursday, December 22, 2011 - link
LOL, triple the performance?Do you also have a standard of dating only Victoria's Secret models?
eanazag - Thursday, December 22, 2011 - link
I have a 3870 which I got in early 2007. It still does well for the main games I play: Dawn of War 2 and Starcraft 2 (25 fps has been fine for me here with settings mostly maxed). I have eyeing a new card. I like the power usage and thermals here. I am not spending $500+ though. I am thinking they are using that price to compensate for the mediocre yields they getting on 28nm, but either way the numbers look justified. I will be look for the best card between $150-$250, maybe $300. I am counting on this cards price coming down, but I doubt it will hit under $400-350 next year.No matter what this looks like a successful soft launch of a video card. For me, anything smokes what I have in performance but not so much on power usage. I'd really not mind the extra noise as the heat is better than my 3870.
I'm in the single card strategy camp.
Monitor is a single 42" 1920x1200 60 Hz.
Intel Core i5 760 at stock clocks. My first Intel since the P3 days.
Great article.
Death666Angel - Thursday, December 22, 2011 - link
Can someone explain the different heights in the die-size comparison picture? Does that reflect processing-changes? I'm lost. :D Otherwise, good review. I don't see the HD7970 in Bench, am I blind or is it just missing.Ryan Smith - Thursday, December 22, 2011 - link
The Y axis is the die size. The higher a GPU the bigger it is (relative to the other GPUs from that company).Death666Angel - Friday, December 23, 2011 - link
Thanks! I thought the actual sizes were the sizes and the y-axis meant something else. Makes sense though how you did it! :-)MonkeyPaw - Thursday, December 22, 2011 - link
As a former owner of the 3870, mine had the short-lived GDDR4. That old card has a place in my nerd heart, as it played Bioshock wonderfully.Peichen - Thursday, December 22, 2011 - link
The improvement is simply not as impressive as I was led to believed. Rumor has it that a single 7970 would have the power of a 6990. In fact, if you crunch the numbers, it would be at least 50% faster than 6970 which should put it close to 6990. (63.25% increase in transistors, 40.37% in TFLOP and 50% increase in memory bandwidth.)What we got is a Fermi 1st gen with the price to match. Remember, this is not a half-node improvement in manufacturing process, it is a full-node and we waited two years for this.
In any case, I am just ranting because I am waiting for something to replace my current card before GTA 5 came out. Nvidia's GK104 in Q1 2012 should be interesting. Rumored to be slightly faster than GTX 580 (slower than 7970) but much cheaper. We'll see.