AMD Radeon HD 7970 Review: 28nm And Graphics Core Next, Together As One
by Ryan Smith on December 22, 2011 12:00 AM EST- Posted in
- GPUs
- AMD
- Radeon
- ATI
- Radeon HD 7000
A Quick Refresher, Cont
Having established what’s bad about VLIW as a compute architecture, let’s discuss what makes a good compute architecture. The most fundamental aspect of compute is that developers want stable and predictable performance, something that VLIW didn’t lend itself to because it was dependency limited. Architectures that can’t work around dependencies will see their performance vary due to those dependencies. Consequently, if you want an architecture with stable performance that’s going to be good for compute workloads then you want an architecture that isn’t impacted by dependencies.
Ultimately dependencies and ILP go hand-in-hand. If you can extract ILP from a workload, then your architecture is by definition bursty. An architecture that can’t extract ILP may not be able to achieve the same level of peak performance, but it will not burst and hence it will be more consistent. This is the guiding principle behind NVIDIA’s Fermi architecture; GF100/GF110 have no ability to extract ILP, and developers love it for that reason.
So with those design goals in mind, let’s talk GCN.
VLIW is a traditional and well proven design for parallel processing. But it is not the only traditional and well proven design for parallel processing. For GCN AMD will be replacing VLIW with what’s fundamentally a Single Instruction Multiple Data (SIMD) vector architecture (note: technically VLIW is a subset of SIMD, but for the purposes of this refresher we’re considering them to be different).

A Single GCN SIMD
At the most fundamental level AMD is still using simple ALUs, just like Cayman before it. In GCN these ALUs are organized into a single SIMD unit, the smallest unit of work for GCN. A SIMD is composed of 16 of these ALUs, along with a 64KB register file for the SIMDs to keep data in.
Above the individual SIMD we have a Compute Unit, the smallest fully independent functional unit. A CU is composed of 4 SIMD units, a hardware scheduler, a branch unit, L1 cache, a local date share, 4 texture units (each with 4 texture fetch load/store units), and a special scalar unit. The scalar unit is responsible for all of the arithmetic operations the simple ALUs can’t do or won’t do efficiently, such as conditional statements (if/then) and transcendental operations.
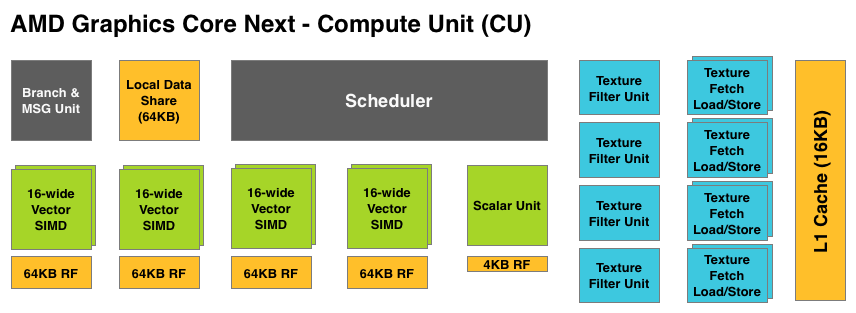
Because the smallest unit of work is the SIMD and a CU has 4 SIMDs, a CU works on 4 different wavefronts at once. As wavefronts are still 64 operations wide, each cycle a SIMD will complete ¼ of the operations on their respective wavefront, and after 4 cycles the current instruction for the active wavefront is completed.
Cayman by comparison would attempt to execute multiple instructions from the same wavefront in parallel, rather than executing a single instruction from multiple wavefronts. This is where Cayman got bursty – if the instructions were in any way dependent, Cayman would have to let some of its ALUs go idle. GCN on the other hand does not face this issue, because each SIMD handles single instructions from different wavefronts they are in no way attempting to take advantage of ILP, and their performance will be very consistent.
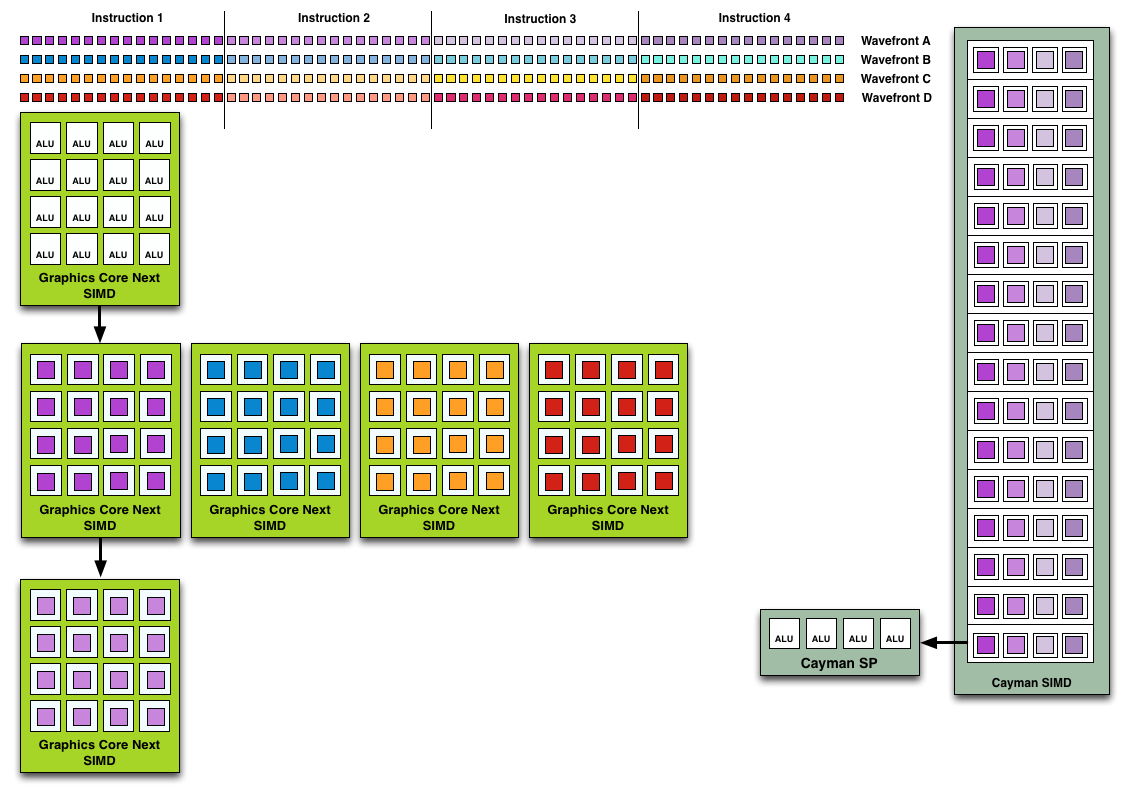
Wavefront Execution Example: SIMD vs. VLIW. Not To Scale - Wavefront Size 16
There are other aspects of GCN that influence its performance – the scalar unit plays a huge part – but in comparison to Cayman, this is the single biggest difference. By not taking advantage of ILP, but instead taking advantage of Thread Level Parallism (TLP) in the form of executing more wavefronts at once, GCN will be able to deliver high compute performance and to do so consistently.
Bringing this all together, to make a complete GPU a number of these GCN CUs will be combined with the rest of the parts we’re accustomed to seeing on a GPU. A frontend is responsible for feeding the GPU, as it contains both the command processors (ACEs) responsible for feeding the CUs and the geometry engines responsible for geometry setup. Meanwhile coming after the CUs will be the ROPs that handle the actual render operations, the L2 cache, the memory controllers, and the various fixed function controllers such as the display controllers, PCIe bus controllers, Universal Video Decoder, and Video Codec Engine.
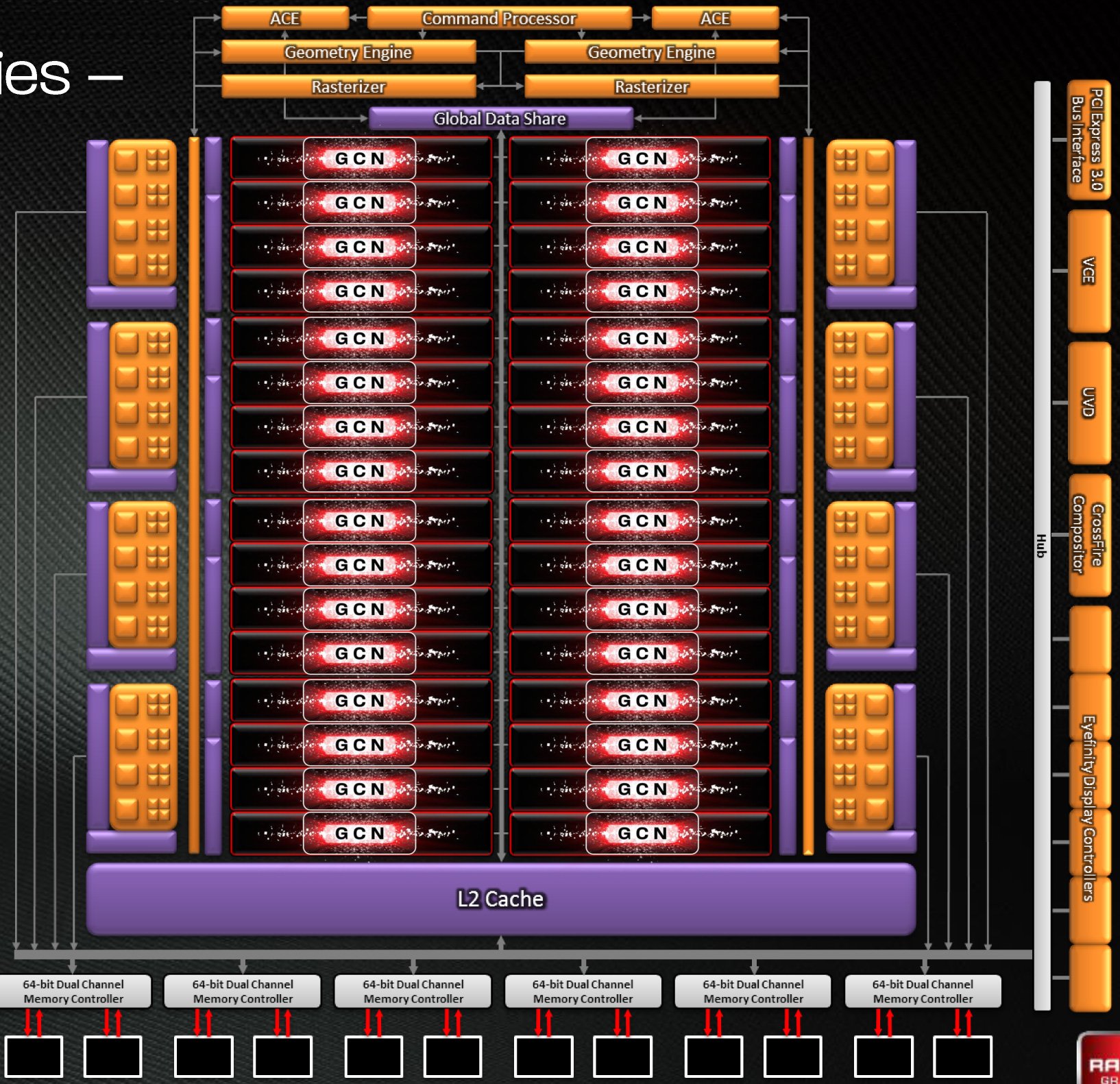
At the end of the day if AMD has done their homework GCN should significantly improve compute performance relative to VLIW4 while gaming performance should be just as good. Gaming shader operations will execute across the CUs in a much different manner than they did across VLIW, but they should do so at a similar speed. And for games that use compute shaders, they should directly benefit from the compute improvements. It’s by building out a GPU in this manner that AMD can make an architecture that’s significantly better at compute without sacrificing gaming performance, and this is why the resulting GCN architecture is balanced for both compute and graphics.








292 Comments
View All Comments
Ananke - Thursday, December 22, 2011 - link
"The 7970 leads the 5870 by 50-60% here and in a number of other games"...and as I see it also carries 500-600% of price premium over the 5870.Meh, this is so so priced for a FireGL card, but very badly placed for a consumer market. Regardless, CUDA is getting more open meanwhile. AMD is still several generations/years behind in the HPC market and marketing a product above the NVidia price targets will not help AMD to make it popular.
Having say so, I am using ATI cards for gaming for several years already, and I am very pleased with their IQ and performance. I have always pre-purchased my ATI cards... What I am missing though is teh promised and never materialized consumer level software that can utilize its calculation ability, aka CyberLink and other video transcoders. If it was not for the naughty Nvidia power draw in the 5th series, I would've gone green to have CUDA. Hence, considering SO MUCH MONEY, I am waiting at least 6 months from now to see what the prices will be for the both new contenders in next GPU architectures :).
Dangerous_Dave - Thursday, December 22, 2011 - link
Seems like AMD can't do anything right these days. Bulldozer was designed for a world that doesn't exist, and now we have this new GPU stinking up the place. I'm sorry but @28nm you have double the transistors per area compared with @40nm, yet the performance is only 30% better for a chip that is virtually the same size! It should be at least twice as far ahead of the 6970 as that, even on immature drivers. As it stands, AMD @ 28nm is only just ahead of Nvidia @ 40nm as far as minimums go (the only thing that matters).I shudder to think how badly AMD is going to get destroyed when Nvidia release their 28nm GPU.
Finally - Friday, December 23, 2011 - link
I shudder to think how badly one Nvidia fanboy's ego is going to get scratched if team red released a better GPU and his favourite team has nothing to offer.Oh... they did?
CeriseCogburn - Thursday, March 8, 2012 - link
We have to let amd "go first" now since they have been so on the brink of bankruptcy collapse for so long that they've had to sell off most of their assets... and refinance by AbuDhabi oil money...I think it's nice our laws and global economy puts pressure on the big winners to not utterly crush the underdogs...
Really, if amd makes another fail it might be the last one before collapse and "restructuring" and frankly not many of us want to see that...
They already made the "last move" a dying company does and slashed with the ax at their people...
If the amd fans didn't constantly demand they be given a few dollars off all the time, amd might not be failing - I mean think about it - a near constant loss, because the excessive demand for price vs perf vs the enemy is all the radeon fans claim to care about.
It would be better for us all if the radeon fans dropped the constant $ complaints and just manned up and supported AMD as real fans, with their pocketbooks... instead of driving their favorite toward bankruptcy and cooked books filled with red ink...
Dangerous_Dave - Thursday, December 22, 2011 - link
On reflection this card is even worse than my initial analysis. For 3.4billion transistors AMD could have done no research at all and simply integrated two 6870s onto a single die (a la 5870 vs 4870) and ramped up the clock speed to somewhere over 1Ghz (since 28nm would have easily allowed that). This would have produced performance similar to a 6990, and far in excess of the 7970.Instead we've done a lot of research and spent 4.1billion transistors creating a card that is far worse than a 6990!
That's the value of AMD's creative thinking.
cknobman - Thursday, December 22, 2011 - link
The sad part is your likely too stupid to realize just how idiotic your post sounds.They introduced a new architecture that facilitates much better compute performance as well as giving more gaming performance.
Did you read the article and look at the compute benchmarks or did you just flip through the game benchmark pages and look at numbers without reading?
Zingam - Thursday, December 22, 2011 - link
Or maybe you just don't realize that they've added another 2 billion transistors for minimal graphics performance increase over the previous generation.That's almost as if you buy a new generation BMW that has instead 300 hp, 600hp but is not able to drag a bigger trailer.
The only benefit for you would be that you can brag that you've just got the most expensive and useless car available.
Finally - Friday, December 23, 2011 - link
Rule 1A:The frequency of a car pseudoanalogy to explain a technical concept increases with thread length. This will make many people chuckle, as computer people are rarely knowledgeable about vehicular mechanics.
cknobman - Friday, December 23, 2011 - link
Holy sh!t are you not reading and understanding the article and posts here??????????The extra transistors and new architecture were to increase COMPUTE PERFORMANCE as well as graphics.
Think bigger picture here dude not just games. Think of fusion and how general computing and graphics computing will merge into one.
This architecture is much bigger than just being a graphics card for games.
This is AMD's fermi except they did it about 100x better than Nvidia keeping power in check and still having amazing performance.
Plus your looking at probably beta drivers (heck maybe alpha) so there could very will be another 10+% increase in performance once this thing hit retail shelves and gets some driver improvements.
CeriseCogburn - Thursday, March 8, 2012 - link
I see. So when nvidia did it, it was abandoning gamers for 6 months of ripping away and gnawing plus... but now, since it's amd, amd has done it 100X better... and no abandonment...Wow.
I love hypocrisy in it's full raw and massive form - it's an absolute wonder to behold.