AMD Radeon HD 7970 Review: 28nm And Graphics Core Next, Together As One
by Ryan Smith on December 22, 2011 12:00 AM EST- Posted in
- GPUs
- AMD
- Radeon
- ATI
- Radeon HD 7000
A Quick Refresher, Cont
Having established what’s bad about VLIW as a compute architecture, let’s discuss what makes a good compute architecture. The most fundamental aspect of compute is that developers want stable and predictable performance, something that VLIW didn’t lend itself to because it was dependency limited. Architectures that can’t work around dependencies will see their performance vary due to those dependencies. Consequently, if you want an architecture with stable performance that’s going to be good for compute workloads then you want an architecture that isn’t impacted by dependencies.
Ultimately dependencies and ILP go hand-in-hand. If you can extract ILP from a workload, then your architecture is by definition bursty. An architecture that can’t extract ILP may not be able to achieve the same level of peak performance, but it will not burst and hence it will be more consistent. This is the guiding principle behind NVIDIA’s Fermi architecture; GF100/GF110 have no ability to extract ILP, and developers love it for that reason.
So with those design goals in mind, let’s talk GCN.
VLIW is a traditional and well proven design for parallel processing. But it is not the only traditional and well proven design for parallel processing. For GCN AMD will be replacing VLIW with what’s fundamentally a Single Instruction Multiple Data (SIMD) vector architecture (note: technically VLIW is a subset of SIMD, but for the purposes of this refresher we’re considering them to be different).

A Single GCN SIMD
At the most fundamental level AMD is still using simple ALUs, just like Cayman before it. In GCN these ALUs are organized into a single SIMD unit, the smallest unit of work for GCN. A SIMD is composed of 16 of these ALUs, along with a 64KB register file for the SIMDs to keep data in.
Above the individual SIMD we have a Compute Unit, the smallest fully independent functional unit. A CU is composed of 4 SIMD units, a hardware scheduler, a branch unit, L1 cache, a local date share, 4 texture units (each with 4 texture fetch load/store units), and a special scalar unit. The scalar unit is responsible for all of the arithmetic operations the simple ALUs can’t do or won’t do efficiently, such as conditional statements (if/then) and transcendental operations.
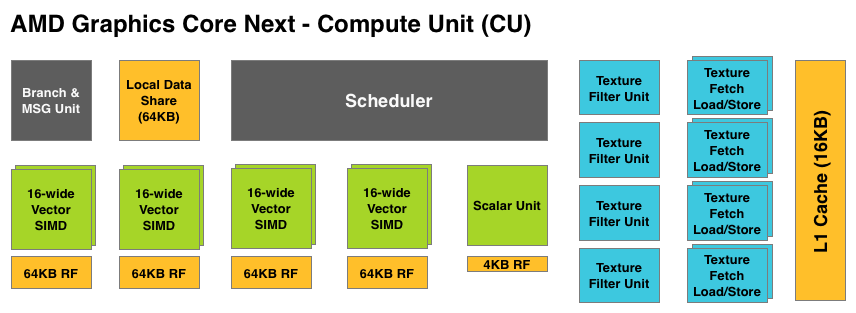
Because the smallest unit of work is the SIMD and a CU has 4 SIMDs, a CU works on 4 different wavefronts at once. As wavefronts are still 64 operations wide, each cycle a SIMD will complete ¼ of the operations on their respective wavefront, and after 4 cycles the current instruction for the active wavefront is completed.
Cayman by comparison would attempt to execute multiple instructions from the same wavefront in parallel, rather than executing a single instruction from multiple wavefronts. This is where Cayman got bursty – if the instructions were in any way dependent, Cayman would have to let some of its ALUs go idle. GCN on the other hand does not face this issue, because each SIMD handles single instructions from different wavefronts they are in no way attempting to take advantage of ILP, and their performance will be very consistent.
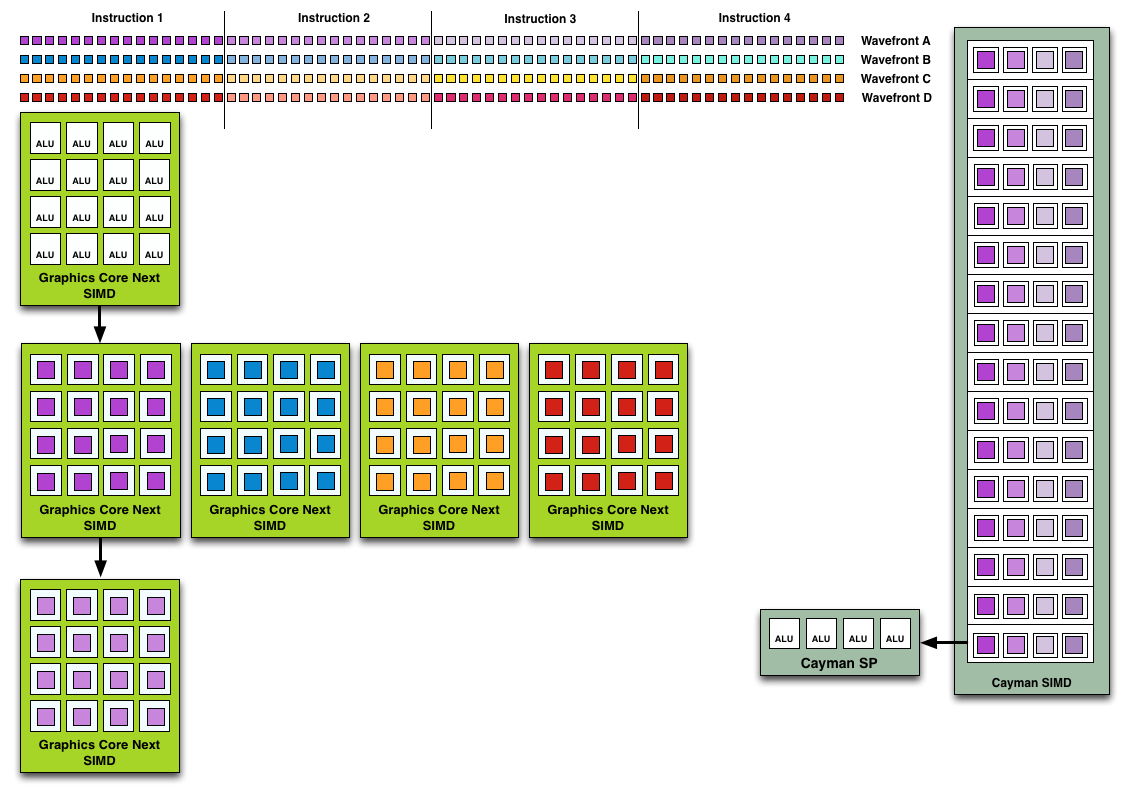
Wavefront Execution Example: SIMD vs. VLIW. Not To Scale - Wavefront Size 16
There are other aspects of GCN that influence its performance – the scalar unit plays a huge part – but in comparison to Cayman, this is the single biggest difference. By not taking advantage of ILP, but instead taking advantage of Thread Level Parallism (TLP) in the form of executing more wavefronts at once, GCN will be able to deliver high compute performance and to do so consistently.
Bringing this all together, to make a complete GPU a number of these GCN CUs will be combined with the rest of the parts we’re accustomed to seeing on a GPU. A frontend is responsible for feeding the GPU, as it contains both the command processors (ACEs) responsible for feeding the CUs and the geometry engines responsible for geometry setup. Meanwhile coming after the CUs will be the ROPs that handle the actual render operations, the L2 cache, the memory controllers, and the various fixed function controllers such as the display controllers, PCIe bus controllers, Universal Video Decoder, and Video Codec Engine.
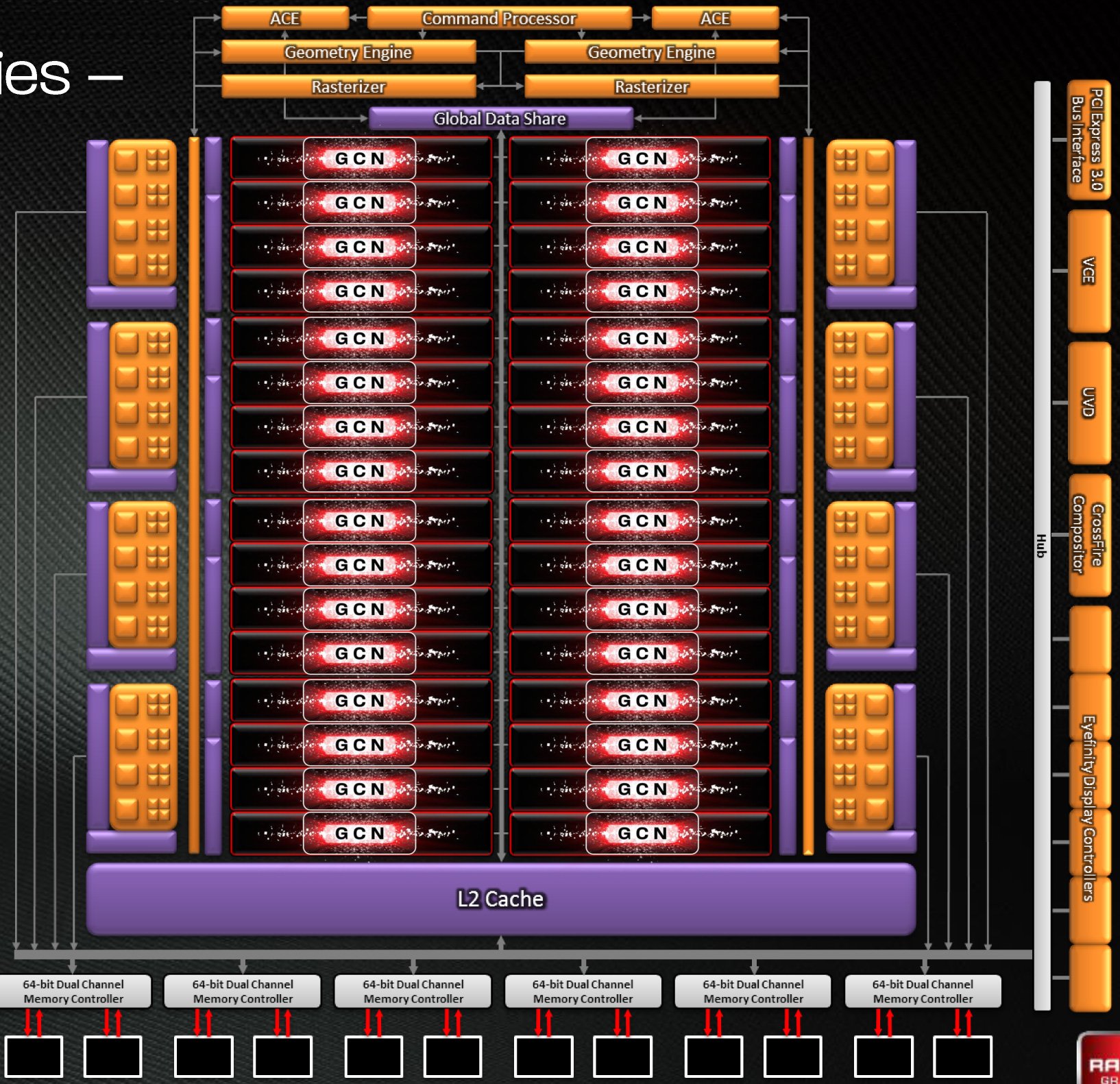
At the end of the day if AMD has done their homework GCN should significantly improve compute performance relative to VLIW4 while gaming performance should be just as good. Gaming shader operations will execute across the CUs in a much different manner than they did across VLIW, but they should do so at a similar speed. And for games that use compute shaders, they should directly benefit from the compute improvements. It’s by building out a GPU in this manner that AMD can make an architecture that’s significantly better at compute without sacrificing gaming performance, and this is why the resulting GCN architecture is balanced for both compute and graphics.








292 Comments
View All Comments
RussianSensation - Thursday, December 22, 2011 - link
That's not what the review says. The review clearly explains that it's the best single-GPU for gaming. There is nothing biased about not being mind-blown by having a card that's only 25% faster than GTX580 and 37% faster than HD6970 on average, considering this is a brand new 28nm node. Name a single generation where AMD's next generation card improved performance so little since Radeon 8500?There isn't any!
SlyNine - Friday, December 23, 2011 - link
2900XT ? But I Don't remember if that was a new node and what the % of improvement was beyond the 1950XT.But still this is a 500$ card, and I don't think its what we have come to expect from a new node and generation of card. However some people seem more then happy with it, Guess they don't remember the 9700PRO days.
takeulo - Thursday, December 22, 2011 - link
as ive read the review this is not a disappointment infact its only a single gpu card but it toughly competing or nearly chasing with the dual gpu's graphics card like 6990 and gtx 590 performance...imagine that 7970 is also a dual gpu?? it will tottally dominate the rest... sorry for my bad english..
eastyy - Thursday, December 22, 2011 - link
the price vs performance is the most important thing for me at the moment i have a 460 that cost me about £160 at the time and that was a few years ago...seems like the cards now for the same price dont really give that much of a increaseMorg. - Thursday, December 22, 2011 - link
What seems unclear to the writer here is that in fact 6-series AMD was better in single GPU than nVidia.Like miles better.
First, the stock 6970 was within 5% of the gtx580 at high resolutions (and excuse me, but if you like a 500 bucks graphics board with a 100 bucks screen ... not my problem -- ).
Second, if you put a 6970 OC'd at GTX580 TDP ... the GTX580 is easily 10% slower.
So overall . seriously ... wake the f* up ?
The only thing nVidia won at with fermi series 2 (gtx5xx) is making the most expensive highest TDP single GPU card. It wasn't faster, they just picked a price point AMD would never target .. and they got i .. wonderful.
However, AMD raped nVidia all the way in perf/watt/dollar as they did with Intel in the Server CPU space since Opteron Istanbul ...
If people like you stopped spouting random crap, companies like AMD would stand a chance of getting the market share their products deserve (sure their drivers are made of shit).
Leyawiin - Thursday, December 22, 2011 - link
The HD 7970 is a fantastic card (and I can't wait to see the rest of the line), but the GTX 580 was indisputably better than the HD 6970. Stock or OC'd (for both).Morg. - Friday, December 23, 2011 - link
Considering TDP, price and all - no.The 6970 lost maximum 5% to the GTX580 above full HD, and the bigger the resolution, the smaller the GTX advantage.
Every benchmark is skewed, but you should try interpreting rather than just reading the conclusion --
Keep in mind the GTX580 die size is 530mm² whereas the 6970 is 380mm²
Factor that in, aim for the same TDP on both cards . and believe me .. the GTX580 was a complete total failure, and a total loss above full HD.
Yes it WAS the biggest single GPU of its time . but not the best.
RussianSensation - Thursday, December 22, 2011 - link
Your post is ill-informed.When GTX580 and HD6970 are both overclocked, it's not even close. GTX580 destroyed it.
http://www.xbitlabs.com/articles/graphics/display/...
HD6950 was an amazing value card for AMD this generation, but HD6970 was nothing special vs. GTX570. GTX580 was overpriced for the performance over even $370 factory preoverclocked GTX570 cards (such as the almost eerily similar in performance EVGA 797mhz GTX570 card for $369).
All in all, GTX460 ~ HD6850, GTX560 ~ HD6870, GTX560 Ti ~ HD6950, GTX570 ~ HD6970. The only card that had really poor value was GTX580. Of course if you overclocked it, it was a good deal faster than the 6970 that scaled poorly with overclocking.
Morg. - Friday, December 23, 2011 - link
I believe you don't get what I said :AT THE SAME TDP, THE HD6xxx TOTALLY DESTROYED THE GTX 5xx
THAT MEANS : the amd gpu was better even though AMD decided to sell it at a TDP / price point that made it cheaper and less performing than the GTX 5xx
The "destroyed it" statement is full HD resolution only . which is dumb . I wouldn't ever get a top graphics board to just stick with full HD and a cheap monitor.
Peichen - Friday, December 23, 2011 - link
According to your argument, all we'd ever need is IGP because no stand-alone card can compete with IGP at the same TDP / price point.