The Bulldozer Aftermath: Delving Even Deeper
by Johan De Gelas on May 30, 2012 1:15 AM ESTIPC Analysis: What Is Going On?
We decided to focus our attention on our MS SQL Server benchmark and profile it on the most important hardware events (IPC, cache, and branch prediction). We used Intel's VTune Amplifier XE 2011 and AMD's Code Analyst 3.4.1037.88 to get a better understand of this benchmark. To put things into perspective, we compared the results with the extremely popular Cinebench benchmark and the 7-Zip compression benchmark.
Note that VTune has a rather steep learning curve and the numbers presented are more detailed but also harder to interprete than those of Code Analyst. In some cases we had doubts about our measurements on the brand spanking new Xeon E5. That is why we are refraining from publishing those numbers until we are absolutely sure they are accurate, so some of the Xeon E5 numbers are missing.
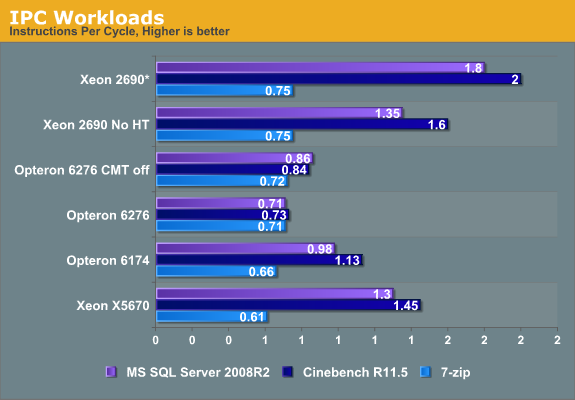
* We add the IPC of the two threads up
It is interesting to note the high Instruction Level Parallelism (ILP) that the Xeon E5 "Sandy Bridge" is able to extract out of these server benchmarks. Almost 1.4 instructions per clock cycle are retired and if you add SMT (Simultaneous Multi Threading), another 0.4 IPC flows through a single core. That is pretty remarkable for a benchmark that consists mostly of SQL statements that result in many branches and loads.
Our Opteron 6200 reveals a bit more about its internal working. Using the extra integer cluster inside the Opteron module causes the separate threads to slow down somewhat. In the case of Cinebench, this is not a real surprise since it contains a lot of SSE floating point commands; a single thread can have the out of order FP cluster all to itself while two threads have to share the SMT capable floating point engine.
But in case of our datamining benchmarks, something else is going on. Single-threaded performance regresses by 18% once you enable the second cluster. We get a 65% speed up (2x 0.71 vs 0.86), which is somewhat lower than the 80% predicted by the AMD slides discussing CMT. So some of the shared resources are slowing down the total performance of our module. We will find out more on the next page.








84 Comments
View All Comments
Aone - Monday, June 4, 2012 - link
Bulldozer's conception was wrong from the scratch.I told it a few time, let's me explain it here again.
I'm sure everyone of you do remember AMD's own words "one BD module has 80% of throughput of two independent cores".
What does this mean in figures?
Let's take the performance of one core as 1.0 point. Therefore two BD modules would have 3.2 points or in other words less than 10% than 3.0 (performance of three independent cores).
Should I remind that with development of independent cores AMD wouldn't had wasted resources (engineering, transistors, money and time) on design and debugging the shared logic. The chip could have been much smaller due to the fact that the chip would have had only 1MB L2 and 2MB L3 per each core and no shared logic. And all of those released resources could have been allocated for development of a more advanced core.
You see that packing two cores inside a one module was wrong even on the conceptional level. I'm very curious who was the main supporter and decision maker of this approach in AMD.
AMD must through away BD conception and return to standard practice. The only question remains: Does AMD have long enough TTL to do it?
BTW, I recommend to look through Spec results again. The comparison of 12c Opteron 62xx w/ 12c Opteron 61xx is of special interest. And let's not forget that Opteron 62xx submissions have higher freq, faster memory and as well as more advanced compiler version and extended instruction set.
TC2 - Monday, June 18, 2012 - link
I'm agree in 100%!!!The BD uA is "unsuccessful" port from graphics uA. There is many and major drawbacks! Note for example one - to write an optimal software you must adopt an application at algorithmic level (in sense of thread specialization)! This is because the both BD-cores are not the same! Also they shares L1 IC, the number of elements is high, ... and many others uA weaknesses.
evolucion8 - Tuesday, June 17, 2014 - link
Northwood was 20 stage pipelines and Prescott was 31, not 39...tipoo - Wednesday, October 8, 2014 - link
Where is the aftermath?"But what about the fourth show stopper? That is probably one of the most interesting ones because it seems to show up (in a lesser degree) in Sandy Bridge too. However, we're not quite ready with our final investigations into this area, so you'll have to wait a bit longer. To be continued...."