Rendering and HPC Benchmark Session Using Our Best Servers
by Johan De Gelas on September 30, 2011 12:00 AM ESTCinebench R11.5
Cinebench, based on MAXON's software CINEMA 4D, is probably one of the most popular benchmarks around, and it is pretty easy to perform this benchmark on your own home machine. However, it gets a little bit more complicated when you try to run it on an 80 thread server: the benchmark only supports 64 threads.
First we tested single threaded performance, to evaluate the performance of each core.
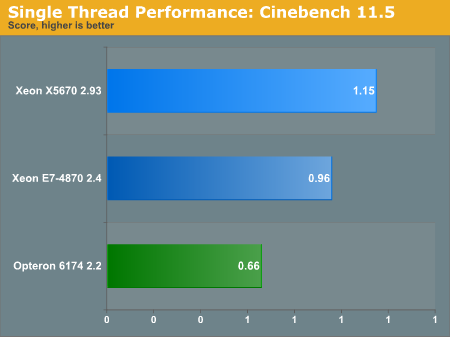
A Core i7-970, which is based on the same "Westmere" architecture gets about 1.2 at 3.2GHz, so there is little surprise that a slightly lower clocked Xeon 5670 is able to reach a 1.15 score. It is interesting to note however that the Westmere core inside the massive Westmere-EX gets a better score than expected. Considering that Cinebench scales almost perfectly with clockspeed, you would expect a score of about 0.9. The E7 can boost clockspeed by 17% from 2.4 to 2.8GHz, while the previously mentioned i7-970 gets only an 8% boost at most (from 3.2 to 3.46GHz). And of course, the massive L3-cache may help too.
The Opteron at 2.2GHz performs like its Phenom II desktop counterparts. A 3.2GHz Phenom II gets a score of about 0.92, so we are not surprised with the 0.66 for our 2.2GHz core.
When we started benchmarking Cinebench on our Xeon E7 platform, we ran into trouble. Cinebench only supports 64 threads at the most and recognized only 32 of our 40 available cores and 80 threads. The results were pretty bad. To get a decent result out of the Xeon E7, we had to disable Hyper-Threading and we forced Cinebench to start up 40 threads. We included a Core i7-970 (Hyper-Threading on) to give you an idea of how a powerful workstation/desktop compares to these servers. This kind of software is run a lot on fast workstations after all.

Even cheap servers will outperform a typical single socket workstation by almost a factor of two. The quad socket machines can offer up to three or four times as much performance. For those of you who can't get enough: you can find some dual Opteron numbers here. The dual Opteron 6174 scores about 15, and a dual Opteron 2435 2.6 "Istanbul" gets about 9.
Cinebench scales very easily as can be noticed from looking at the 32 core and 40 core results of the Xeon E7-4870. Increase the core count by 25% and you get a 22.4% performance increase. The Opteron scales slightly worse. Compare the 48-core result with the 32 core one: a 50% increase in core counts gets you "only" a 37% increase in performance.
Below you can see the rendering performance of two top machines rendering with different numbers of cores.
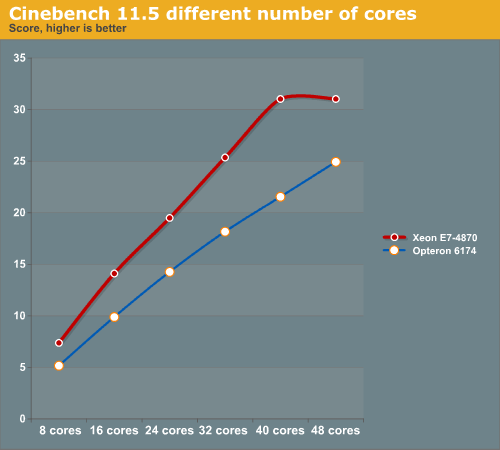
You need about 48 2.2GHz Opteron cores to match 32 Xeon cores. The good news for AMD is that even these 8-core Westmere-EX CPUs are almost twice as expensive. That means that quad AMD Opteron 61xx systems are a viable choice for rendering, at least in CINEMA 4D (assuming it has the same 64-thread limitation as Cinebench). AMD has carved out a niche here, which is one reason why there will be cheaper 4 socket Romley EP systems in the near future.








52 Comments
View All Comments
mino - Saturday, October 1, 2011 - link
Memory channel count has nothing to do with coherency traffic.mino - Saturday, October 1, 2011 - link
Exactly. Actually the optimized way would normally be to split the workload into 12-thread chunks on Opterons and 20-thread chunks on Xeons. That is also a reason why 4S machines rarely seen in HPC.They just do not make sense for 99% of the workloads there.
lelliott73181 - Friday, September 30, 2011 - link
For those of us out there that are seriously into doing distributed computing projects, it'd be cool to see a bit of information on how these systems scale in terms of programs like BOINC, Folding@home, etc.MrSpadge - Friday, September 30, 2011 - link
Scaling is pretty much perfect there, not very interesting. It may have been different back in the days when these big iron systems were starved for memory bandwidth.MrS
fic2 - Friday, September 30, 2011 - link
Was hoping for some Bulldozer server benchmarks since the server chips are "released". ;o)Didn't really think that I would see them though.
rahvin - Friday, September 30, 2011 - link
Have you considered that the Opteron problem could because the software is compiled with the Intel compiler which is disabling advanced features if it doesn't detect an Intel processor? This is a common problem in that the ICC compiler sets flags that if the processor doesn't find an Intel processor it turns off SSE and all the processor extensions and runs the code in x86 compatibility mode (very slow). Any time I see results that drastically off it reads to me that the software in question is using the Intel complier.Chibimyk - Friday, September 30, 2011 - link
Ifort 10 is from 2007 and is not aware of the architectures of any of these machines. It doesn't support the latest sse instructions and likely doesn't know the levels of sse supported by the cpus. You have no idea which math libraries it is linked to. It won't be using the latest Intel MKL which supports the newest chips. It isn't using the AMD optimized ACML libraries either.What you are comparing using these compiled binaries is the performance of both systems when running intel optimized code.
You also have no idea of the levels of optimization used when compiling. Some of the highest optimization speed increases with the Intel compilers drop ANSI accuracy, or at least used to. Whether this impacts results is application specific.
Generally speaking:
Intel chips are fastest with Intel compilers and Intel MKL.
AMD chips are fastest with the Portland Group compilers and AMD ACML.
Some code runs faster with the Goto BLAS libraries.
Ideally you want to compare benchmarks with each system under ideal conditions.
eachus - Saturday, October 1, 2011 - link
Definitely true about AMD chips and the Portland Group. I get slightly better results with GCC than the Intel compiler, partly because I know how to get it to do what I want. ;-) But Portland is still better for Fortran.Second, there is a way to solve the NUMA problem that all HPC programmers know. Any (relatively static) data should be replicated to all processors. Arrays that will be written to by multiple threads can be duplicated with a "fire and forget" strategy, assuming that only one processor is writing to a particular element (well cache line)* in the array between checkpoints. In this particular case, you would use (all that extra) memory to have eight copies of the (frequently modified) data.
Next, if your compiler doesn't use non-temporal memory references for random access floating-point data, you are going to get clobbered just like in the benchmark. (I'm fairly sure that the Portland Group compilers use PrefetchNTA instructions by default. I tend to do my innermost loops by hand on the GCC back end, which is how I get such good results. You can too--but you really need to understand the compiler internals to write--and use--your own intrinsic routines.) What PrefetchNTA does is two things, first
it prefetches the data if it is not already in a local cache. This can be a big win. What kills you with Opteron NUMA fetches is not the Hypertransport bandwidth getting clogged, it is the latency. AMD CPUs hate memory latency. ;-)
The other thing that PrefetchNTA does is to tell the caches not to cache this data. This prevents cache pollution, especially in the L1 data cache. Oh, and don't forget to use PrefetchNTA before writing to part of a cache line. This is where you can really get hit. The processor has to keep the data to be stored around until the cache line is in a local cache. (Or in the magic zeroth level cache AMD keeps in the floating point register file.) Running out of space in the register file can stall the floating point unit when no more registers are available for renaming purposes.
Oh, and one of those "interesting" features of Bulldozer for compiler gurus is that it strongly prefers to have only one NT write stream at a time. (Reading from multiple data streams is apparently not an issue.) Just another reason we have to teach programmers to cache line aligned records for data, rather than many different arrays with the same dimensions. ;-)
* This is another of those multi-processor gotchas that eats up address space--but there is plenty to go around now that everyone is using 64-bit (actually 48-bit) addresses. You really don't want code on two different CPU chips writing to the same cache line at about the same time, even if the memory hardware can (and will) go to extremes to make it work.
It used to be that AMD CPUs used 64-byte cache lines and Intel always used 256-byte lines. When the hardware engineers got together for I think the DDR memory standard, they found that AMD fetched the "partner" 64 byte line if there were no other request waiting, and Intel cut fetches at 128 bytes if there was a waiting memory request. So it turned out that the width of the cache line inside the CPUs were different, but in practice most of the main memory accesses were 128-bytes wide no matter whose CPU you had. ;-) Anyway a data point for fluid flow software tends to have 48 bytes or so per data point. (Six DP values x,y, and z, and x',y' and z'. Aligning to 64-byte boundaries is good, 128-bytes is better, and you may want to try 256-bytes on some Intel hardware...)
mino - Saturday, October 1, 2011 - link
You deserve the paycheck for this article!Howgh.
UrQuan3 - Monday, October 3, 2011 - link
I'd like to add one to the request for a compiler benchmark. It might go well with the HPC study. The hardest part would, of course, be finding an unbiased way to conduct it. There's just so many compiler flags that add their own variables. Then you need source code.If you do decide to give it a try, Visual Studio, GCC, Intel, and Portland would be a must. I don't know how Anandtech would do it, but I've been impressed before.