AMD's Graphics Core Next Preview: AMD's New GPU, Architected For Compute
by Ryan Smith on December 21, 2011 9:38 PM ESTPrelude: The History of VLIW & Graphics
Before we get into the nuts & bolts of Graphics Core Next, perhaps it’s best to start at the bottom, and then work our way up.
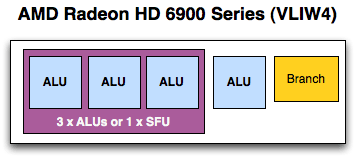
The fundamental unit of AMD’s previous designs has been the Streaming Processor, previously known as the SPU. In every modern AMD design other than Cayman (6900), this is a Very Long Instruction Word 5 (VLIW5) design; Cayman reduced this to VLIW4. As implied by the architectural name, each SP would in turn have 5 or 4 fundamental math units – what AMD now calls Radeon cores – which executed the individual instructions in parallel over as many clocks as necessary. Radeon cores were coupled with registers, a branch unit, and a special function (transcendental) unit as necessary to complete the SP.
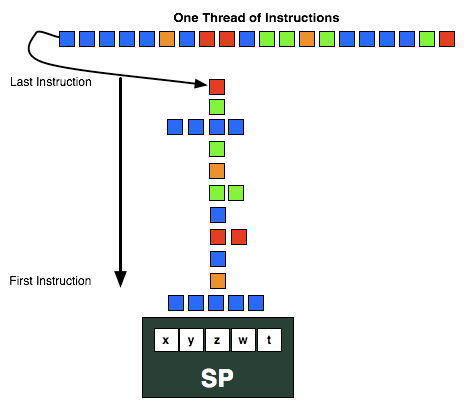
VLIW designs are designed to excel at executing many operations from the same task in parallel by breaking it up into smaller groupings called wavefronts. In AMD’s case a wavefront is a group of 64 pixels/values and the list of instructions to be executed against them. Ideally, in a wavefront a group of 4 or 5 instructions will come down the pipe and be completely non-interdependent, allowing every Radeon core to be fed. When dependent instructions would come down however, fewer instructions could be scheduled at once, and in the worst case only a single instruction could be scheduled. VLIW designs will never achieve perfect efficiency in this regard, but the farther real world utilization is from ideal efficiency, the weaker the benefits of VLIW.
The use of VLIW can be traced back to the first AMD DX9 GPU, R300 (Radeon 9700 series). If you recall our Cayman launch article, we mentioned that AMD initially used a VLIW design in those early parts because it allowed them to process a 4 component dot product (e.g. w, x, y, z) and a scalar component (e.g. lighting) at the same time, which was by far the most common graphics operation. Even when moving to unified shaders in DX10 with R600 (Radeon HD 2900), AMD still kept the VLIW5 design because the gaming market was still DX9 and using those kinds of operations. But as new games and GPGPU programs have come out efficiency has dropped over time, and based on AMD’s own internal research at the time of the Cayman launch the average shader program was utilizing only 3.4 out of 5 Radeon cores. Shrinking from VLIW5 to VLIW4 fights this some, but utilization will always be a concern.
Finally, it’s worth noting what’s in charge of doing all of the scheduling. In the CPU world we throw things at the CPU and let it schedule actions as necessary – it can even go out-of-order (OoO) within a thread if it will be worth it. With VLIW, scheduling is the domain of the compiler. The compiler gets the advantage of knowing about the full program ahead of time and can intelligently schedule some things well in advance, but at the same time it’s blind to other conditions where the outcome is unknown until the program is run and data is provided. Because of this the schedule is said to be static – it’s set at the time of compilation and cannot be changed in-flight.
So why in an article about AMD Graphics Core Next are we going over the quick history of AMD’s previous designs? Without understanding the previous designs, we can’t understand what is new about what AMD is doing, or more importantly why they’re doing it.








83 Comments
View All Comments
Targon - Saturday, June 18, 2011 - link
With Windows 7 having a 80 percent(or higher at this point) install base being 64 bit, it will take until late 2013 before we see the majority of the old 32 bit install base being phased out in the home computer market(as people replace their computers at the four-five year mark). Until then, application developers have to expect that they MUST support both 32 and 64 bit platforms. Lowest common denominator for your user base is what developers generally have to compile for.DanNeely - Saturday, June 18, 2011 - link
I assume you're using the steam hardware survey since they're showing 4:1. Unfortunately steam's not a good source for broad market stats since it excludes the low end boxes bought by non-gamers and corporate boxes. Surveys that capture these numbers only show a 2:1ish ratio for win7 64:32.Beyond that, it's the people with the low end 32bit boxes that will keep their old clunkers the longest. You're also underestimating how long support for legacy OSes will continue despite their very small market shares. Firefox 4 still runs on win2k, despite it's market share having been negligible for several years and being officially out of support for almost a year.
Excepting apps that actually can benefit from going 64bit I expect most to stay 32bit for at least the next 5 years.
swaaye - Saturday, June 18, 2011 - link
Indeed. In the non-gamer realm, I know of people happy with 2003 Pentium 4s and Athlon XPs yet. I have no doubt that there are many people with even older hardware. This stuff tends to stick around until the PCs die and the owner is told it's not worth the money to upgrade. Fear of change and the simple lack of a true need to upgrade is the reason.swaaye - Saturday, June 18, 2011 - link
Oops. I meant that the owner is told it's not worth the money to fix the dead old hardware. But they do also tend to ask about upgrading their ancient box too.Randomblame - Saturday, June 18, 2011 - link
I was at office max the other day and a guy was screaming at a sales rep because they didn't carry any serial mice that supported his rig. I don't mean ps2 either. He was carrying around a busted up brown serial mouse. He said his rig came with windows 95 but last year he upgraded it to windows 98. Seriously. This is the world we live in.EJ257 - Saturday, June 18, 2011 - link
I still have my Compaq (that came with Win95 which I upgraded to win98) running on a Pentium 133 with 32MB of EDO RAM and a 2.1GB HDD. Its sitting ilde in my basement collecting dust at the moment. :DOperandi - Sunday, June 19, 2011 - link
But Steam is good representation of those who could benefit from and will ultimately will be using these future technologies, professionals and enthusiasts. Such is always the way of high-end computing.softdrinkviking - Monday, June 20, 2011 - link
exactly. people still running XP are probably not the target market for developers because if they are so slow on the uptake of new technology, it would follow that they are also relatively uninterested in other new programs.Targon - Sunday, June 19, 2011 - link
Nope, I am going on what my customers have and are upgrading to. If you BUY a machine with Windows 7 on it, 9 out of 10 have Windows 7 64 bit on them. Those that have 32 bit are either the very low-end machines with only 1GB of RAM(yes, they still sell those), or they are the result of doing an upgrade from Windows Vista 32 bit.That is the thing about 64 bit, people don't "go to 64 bit" at this point, they get a new computer that comes with 64 bit Windows on it. The number of people who do an upgrade on an older machine has dropped, since those who would have done the upgrade did that back in 2009 and early 2010 when Windows 7 first came out.
Now, the real benefit to 64 bit isn't as much about the software as it is about how much RAM the machine comes with. If you get a machine with 4GB of RAM, you want 64 bit, just so you don't lose memory due to the 4GB limit on 32 bit Windows, and hardware mapping below the 4GB mark.
A part of this is also about the area you live in, and how much money there is going around. I live in an area where it is the norm to pay over $8 per person for lunch at a deli, and as a result, the value of the dollar isn't as high. Spending $20/day just on lunch and minor expenses is the norm, so with that in mind, replacing a computer every 4-5 years, even for the non-technical is NORMAL. The last time I encountered Windows 95 or 98 was around 6 years ago.
UrQuan3 - Thursday, June 23, 2011 - link
There is a little more benefit. A few of us were doing an internal benchmark of our software using VStudio 2010 and all the random hardware we have around. 32bit, 32bit + SSE2, and 64bit + SSE2. We found across the board, 64bit is about 5-10% than 32bit + SSE2 and 5-20% faster than basic x86.However, a 64bit OS gave no benefit (or penalty) for a 32bit program. The same 32bit software ran the same speed on XP32, XP64, Vista32, Vista64, and 7-64.