AMD's Radeon HD 6970 & Radeon HD 6950: Paving The Future For AMD
by Ryan Smith on December 15, 2010 12:01 AM ESTCayman: The New Dawn of AMD GPU Computing
We’ve already covered how the shift from VLIW5 to VLIW4 is beneficial for AMD’s computing efforts: narrower SPUs are easier to fully utilize, FP64 performance improves to 1/4th FP32 performance, and the space savings give AMD room to lay down additional SIMDs to improve performance. But if Cayman is meant to be a serious effort by AMD to relaunch themselves in to the GPU computing market and to grab a piece of NVIDIA’s pie, it takes more than just new shaders to accomplish the task. Accordingly, AMD has been hard at work to round out the capabilities of their latest GPU to make it a threat for NVIDIA’s Fermi architecture.
AMD’s headline compute feature is called asynchronous dispatch, a long word that actually does a pretty good job of describing what it does. To touch back on Fermi for a moment, with Fermi NVIDIA introduced support for parallel kernels, giving Fermi the ability to execute multiple kernels at once. AMD in turn is following NVIDIA’s approach of executing multiple kernels at once, but is going to take it one step further.
The limit of NVIDIA’s design is that while Fermi can execute multiple kernels at once, each one must come from the same CPU thread. Independent threads/applications for example cannot issue their own kernels and have them execute in parallel, rather the GPU must context switch between them. With asynchronous dispatch AMD is going to allow independent threads/applications to issue kernels that execute in parallel. On paper at least, this would give AMD’s hardware a significant advantage in this scenario (context switching is expensive), one that would likely eclipse any overall performance advantages NVIDIA had.
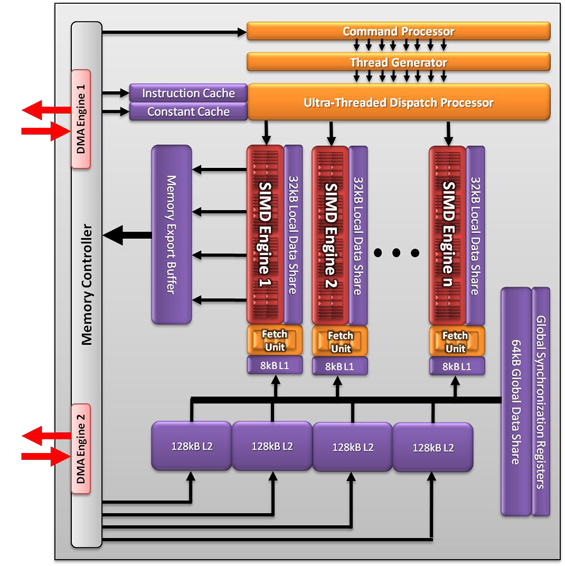
Fundamentally asynchronous dispatch is achieved by having the GPU hide some information about its real state from applications and kernels, in essence leading to virtualization of GPU resources. As far as each kernel is concerned it’s running in its own GPU, with its own command queue and own virtual address space. This places more work on the GPU and drivers to manage this shared execution, but the payoff is that it’s better than context switching.
For the time being the catch for asynchronous dispatch is that it requires API support. As DirectCompute is a fixed standard this just isn’t happening – at least not with DirectCompute 11. Asynchronous dispatch will be exposed under OpenCL in the form of an extension.
Meanwhile the rest of AMD’s improvements are focusing on memory and cache performance. While the fundamental architecture is not changing, there are several minor changes here to improve compute performance. The Local Data Store attached to each SIMD is now able to bypass the cache hierarchy and Global Data Store by having memory fetches read directly in to the LDS. Meanwhile Cayman is getting a 2nd DMA engine, improving memory reads & writes by allowing Cayman to execute two at once in each direction.
Finally, read ops from shaders are being sped up a bit. Compared to Cypress, Cayman can coalesce them in to fewer operations.
As today’s launch is primarily about the Radeon HD 6900 series AMD isn’t going too much in depth on the compute side of things, so everything here is a fairly high level overview of the architecture. Once AMD has Firestream cards ready to go with Cayman in them, there will likely be more to talk about.








168 Comments
View All Comments
B3an - Thursday, December 16, 2010 - link
Very stupid uninformed and narrow-minded comment. People like you never look to the future which anyone should do when buying a graphics card, and you completely lack any imagination. Theres already tons of uses for GPU computing, many of which the average computer user can make use of, even if it's simply encoding a video faster. And it will be use a LOT more in the future.Most people, especially ones that game, dont even have 17" monitors these days. The average size monitor for any new computer is at least 21" with 1680 res these days. Your whole comment is as if everyone has the exact same needs as YOU. You might be happy with your ridiculously small monitor, and playing games at low res on lower settings, and it might get the job done, but lots of people dont want this, they have standards and large monitors and needs to make use of these new GPU's. I cant exactly see many people buying these cards with a 17" monitor!
CeepieGeepie - Thursday, December 16, 2010 - link
Hi Ryan,First, thanks for the review. I really appreciate the detail and depth on the architecture and compute capabilities.
I wondered if you had considered using some of the GPU benchmarking suites from the academic community to give even more depth for compute capability comparisons. Both SHOC (http://ft.ornl.gov/doku/shoc/start) and Rodinia (https://www.cs.virginia.edu/~skadron/wiki/rodinia/... look like they might provide a very interesting set of benchmarks.
Ryan Smith - Thursday, December 16, 2010 - link
Hi Ceepie;I've looked in to SHOC before. Unfortunately it's *nix-only, which means we can't integrate it in to our Windows-based testing environment. NVIDIA and AMD both work first and foremost on Windows drivers for their gaming card launches, so we rarely (if ever) have Linux drivers available for the launch.
As for Rodinia, this is the first time I've seen it. But it looks like their OpenCL codepath isn't done, which means it isn't suitable for cross-vendor comparisons right now.
IdBuRnS - Thursday, December 16, 2010 - link
"So with that in mind a $370 launch price is neither aggressive nor overpriced. Launching at $20 over the GTX 570 isn’t going to start a price war, but it’s also not so expensive to rule the card out. "At NewEgg right now:
Cheapest GTX 570 - $509
Cheapest 6970 - $369
$30 difference? What are you smoking? Try $140 difference.
IdBuRnS - Thursday, December 16, 2010 - link
Oops, $20 difference. Even worse.IdBuRnS - Thursday, December 16, 2010 - link
570...not 580.../hangsheadinshame
epyon96 - Thursday, December 16, 2010 - link
This was a very interesting discussion to me in the article.I'm curious if Anandtech might expand on this further in a future dedicated article comparing what NVIDIA is using to AMD.
Are they also more similar to VLIW4 or VLIW5?
Can someone else shed some light on it?
Ryan Smith - Thursday, December 16, 2010 - link
We wrote something almost exactly like you're asking for for our Radeon HD 4870 review.http://www.anandtech.com/show/2556
AMD and NVIDIA's compute architectures are still fundamentally the same, so just about everything in that article still holds true. The biggest break is VLIW4 for the 6900 series, which we covered in our article this week.
But to quickly answer your question, GF100/GF110 do not immediately compare to VLIW4 or VLIW5. NVIDIA is using a pure scalar architecture, which has a number of fundamental differences from any VLIW architecture.
dustcrusher - Thursday, December 16, 2010 - link
The cheap insults are nothing but a detriment to what is otherwise an interesting argument, even if I don't agree with you.As far as the intellect of Anandtech readers goes, this is one of the few sites where almost all of the comments are worth reading; most sites are the opposite- one or two tiny bits of gold in a big pan of mud.
I'm not going to "vastly overestimate" OR underestimate your intellect though- instead I'm going to assume that you got caught up in the moment. This isn't Tom's or Dailytech, a little snark is plenty.
Arnulf - Thursday, December 16, 2010 - link
When you launch an application (say a game), it is likely to be the only active thread running on the system, or perhaps one of very few active threads. CPU with Turbo function will clock up as high as possible to run this main thread. When further threads are launched by the application, CPU will inevitably increase its power consumption and consequently clock down.While CPU manufacturers don't advertise this functionality in this manner, it is really no different from PowerTune.
Would PowerTune technology make you feel any better if it was marketed the other way around, the way CPUs are ? (mentioning lowest frequencies and clock boost provided that thermal cap isn't met yet)