Intel's Sandy Bridge Architecture Exposed
by Anand Lal Shimpi on September 14, 2010 4:10 AM EST- Posted in
- CPUs
- Intel
- Sandy Bridge
The Ring Bus
With Nehalem/Westmere all cores, whether dual, quad or six of them, had their own private path to the last level (L3) cache. That’s roughly 1000 wires per core. The problem with this approach is that it doesn’t work well as you scale up in things that need access to the L3 cache.
Sandy Bridge adds a GPU and video transcoding engine on-die that share the L3 cache. Rather than laying out another 2000 wires to the L3 cache Intel introduced a ring bus.
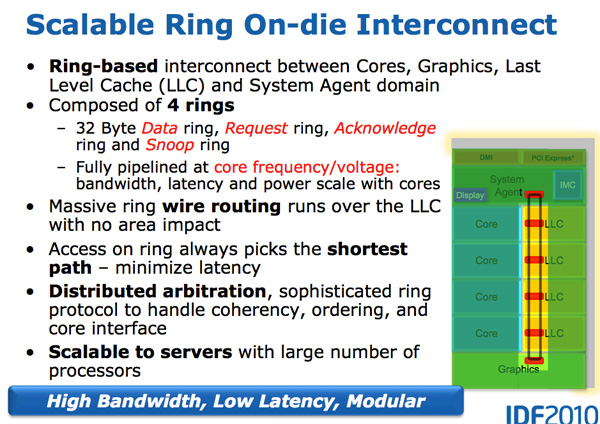
Architecturally, this is the same ring bus used in Nehalem EX and Westmere EX. Each core, each slice of L3 (LLC) cache, the on-die GPU, media engine and the system agent (fancy word for North Bridge) all have a stop on the ring bus.
The bus is made up of four independent rings: a data ring, request ring, acknowledge ring and snoop ring. Each stop for each ring can accept 32-bytes of data per clock. As you increase core count and cache size, your cache bandwidth increases accordingly.
Per core you get the same amount of L3 cache bandwidth as in high end Westmere parts - 96GB/s. Aggregate bandwidth is 4x that in a quad-core system since you get a ring stop per core (384GB/s).
L3 latency is significantly reduced from around 36 cycles in Westmere to 26 - 31 cycles in Sandy Bridge. We saw this in our Sandy Bridge preview and now have absolute numbers in hand. The variable cache latency has to do with what core is accessing what slice of cache.
Also unlike Westmere, the L3 cache now runs at the core clock speed - the concept of the un-core still exists but Intel calls it the “system agent” instead and it no longer includes the L3 cache.
With the L3 cache running at the core clock you get the benefit of a much faster cache. The downside is the L3 underclocks itself in tandem with the processor cores. If the GPU needs the L3 while the CPUs are downclocked, the L3 cache won’t be running as fast as it could had it been independent.
The L3 cache is divided into slices, one associated with each core although each core can address the entire cache. Each slice gets its own stop and each slice has a full cache pipeline. In Westmere there was a single cache pipeline and queue that all cores forwarded requests to, in Sandy Bridge it’s distributed per cache slice.
The ring wire routing runs entirely over the L3 cache with no die area impact. This is particularly important as you effectively get more cache bandwidth without any increase in die area. It also allows Intel to scale the core count and cache size without incurring additional ring-related die area.
Each of the consumers/producers on the ring get their own stop. The ring always takes the shortest path. Bus arbitration is distributed on the ring, each stop knows if there’s an empty slot on the ring one clock before.
The System Agent
For some reason Intel stopped using the term un-core, instead in Sandy Bridge it’s called the System Agent.
The System Agent houses the traditional North Bridge. You get a 16 PCIe 2.0 lanes that can be split into two x8s. There’s a redesigned dual-channel DDR3 memory controller that finally restores memory latency to around Lynnfield levels (Clarkdale moved the memory controller off the CPU die and onto the GPU).
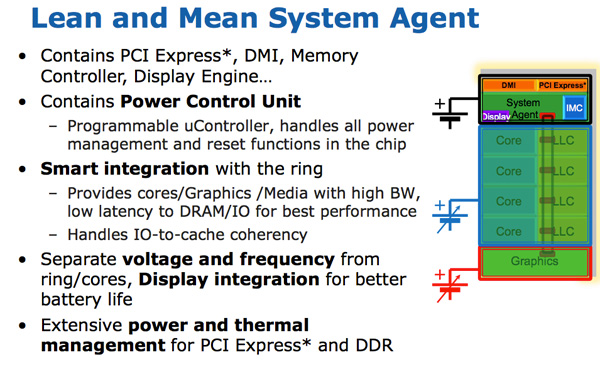
The SA also has the DMI interface, display engine and the PCU (Power Control Unit). The SA clock speed is lower than the rest of the core and it is on its own power plane.








62 Comments
View All Comments
markhennry - Monday, November 29, 2010 - link
wow awesome site about the computer parts i thinking buy a cpu and now i got a good help from this sites..katleo123 - Tuesday, February 1, 2011 - link
It is not expected to compete Core i7 processors to take its place
visit http://www.techreign.com/2010/12/intels-sandy-brid...