Everything You Always Wanted to Know About SDRAM (Memory): But Were Afraid to Ask
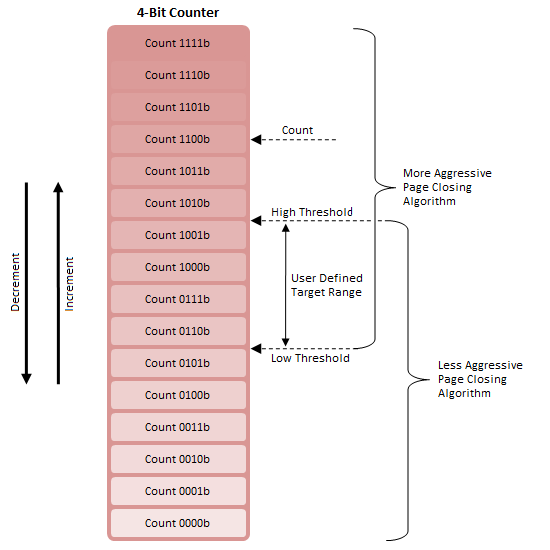
by Rajinder Gill on August 15, 2010 10:59 PM ESTFirst, consider a 4-bit counter with two adjustable thresholds (Figure 12). When Count is greater than High Threshold, Algorithm A is deemed appropriate; the same is true concerning Algorithm B and Count less than Low Threshold.
For the range between High Threshold and Low Threshold, either algorithm may be in effect. This is because a switch from Algorithm B to Algorithm A will occur only with Count greater than High Threshold and increasing and a switch from Algorithm A to Algorithm B will occur only with Count less than Low Threshold and decreasing.
The overlap range is also the Target Range as the system will naturally attempt to maintain Counter between these two points. This is true since Algorithm A tends to lower Count while Algorithm B tends to raise Count. This system acts to reduce or eliminate rapid thrashing between algorithms.
Next, define a truth table (Figure 13) defining how Count will vary. By doing so we can encode a feedback mechanism into our system. Successful predictions by the Adaptive Page Close Logic - a prevented page-miss access (good) in response to a decision to close a page or a facilitated page-hit access (good) in response to a decision to leave a page open - suggest no change to policy is required and so never modify Count.
For a facilitated page-miss access (bad) due to a poor decision to leave a page open, increment Count. If Count were to trend upward we could conceivably conclude that the current policy was most often wrong and not only that, tended to leave pages open far too long while "fishing" for page-hit operations. The current algorithm must not be closing pages aggressively enough.
For a prevented page-hit access (bad) due to a poor decision to close a page early, decrement Count. If Count were to trend downward we would suspect the opposite: the algorithm is too aggressively closing pages and leaving potential page-hits on the cutting room floor.

As best we can tell, this construct represent reality for APM Technology. Although we would like to believe the system has more than two gears (algorithms), our model perfectly explains the existing control register both in type and number.
Looking ahead you will see Max Page Close Limit and Min Page Close Limit are the specified High and Low Threshold values, respectively. Setting a larger difference increases the size of the feedback dead band, slowing the rate at which system responds to its own evaluative efforts. Mistake Counter is represented by the starting Count and should be set somewhere near the middle of the dead band.
Adaptive Timeout Counter sets the assertion time of any decision to keep a page open (i.e. how long before the decision to keep a page open stands before we give up hope of a page-hit access). Repeated access to the same page will reset this counter each time as long as the remaining lifetime is non-zero. Lower values result in a more aggressive page close policy and vice versa for higher values.
Request Rate, we believe, controls how often Count (Mistake Counter) is updated, and therefore how smoothly the system adapts to quickly changing workloads. There must be a good reason not to flippantly set this interrupt rate as low as possible. Perhaps this depletes hardware resources needed for other operations or maybe higher duty cycles disproportionally raises power consumption. Whatever the reason, there's more than a fair chance you can hurt performance if you're just spit-balling with this setting.








46 Comments
View All Comments
JarredWalton - Monday, August 16, 2010 - link
Oh, it's missing a lot more than just voltage information. :-) There are rebates on most memory kits right now, for instance. Still, I felt it was useful to highlight where the current "best deals" tend to fall.I personally wouldn't touch the ultra-expensive $150+ stuff, but up to $115 has potential at least. For a lower voltage kit, G.Skill has an ECO line rated at DDR3-1600 7-8-7-24-2N and 1.35V for $103. Worth a look at least....
JarredWalton - Monday, August 16, 2010 - link
Note: I screwed up my table above. DDR3 is two bits per clock, so the base clocks are all twice what I listed, which means latency for CAS is half what I listed. Sorry. Got things confused with GDDR5. :-) The relative latency is still the same, of course, which is the main point.JarredWalton - Monday, August 16, 2010 - link
Side note number two: And of course, CAS Latency isn't the be-all, end-all. According to benchmarks by Raja, DDR3-2000 at 6-9-6 timings often trails RAM at 7-8-7, as the tRCD difference becomes more pronounced in some cases.Rajinder Gill - Monday, August 16, 2010 - link
Sorry I should have said 7-7-8 vs 6-9-8. This happens when the number of random access requests are high (fewer back to back reads). Benchmarks like WinRar and Super Pi (synthetic) are mainly the ones that show this.-Raja
Drag0nFire - Friday, August 20, 2010 - link
I've had great experience with the ECO line. Put the 2x2 kit you mentioned in two computers so far, and it's been great. Feels like a steal to get such high speed and low voltage at such a great price.kalniel - Monday, August 16, 2010 - link
Thanks for taking the time to write the article - the cycle time-line figures are very helpful, but I'm struggling to understand it correctly.Take fig. 5. There doesn't seem to be a Read to Precharge Delay. If we follow the recommendation of CL+tBurst = tRCP + tRP then won't there be a delay of 4T after the Data Read Burst before the RAS Precharge starts, giving a Row Cycle Time of 26 rather than 24?
kjboughton - Monday, August 16, 2010 - link
tRTP may very well be 4T but the minimum RAS Active Time (tRAS) is 18T. The precharge is precluded from occuring until this period has expired making the clock at T + 18 the first opportunity to precharge the bank. Add to this the RAS Precharge (tRP) and you have the Row Cycle Time (tRC = tRAS + tRP) - the minimum time any single row MUST remain open before it can be closed (and before another page in the same bank can be accessed).Does this help?
kalniel - Monday, August 16, 2010 - link
I thought the Read to Precharge Delay was there precisely to ensure you waited the minimum RAS active time before precharging the bank. Are you saying that the tRTP doesn't apply if you've already finished tRCD+CL+tBurst within tRAS so can start precharging as soon as minimum RAS active time is achieved?In other words, tRTP doesn't have a bearing on a single burst per page, but is there to help synchronise auto-precharge reads within the same page?
My ignorance may be beyond redemption!
kjboughton - Monday, August 16, 2010 - link
Read to Precharge Delay (tRTP) is the minimum wait time from a READ (column access) to bank PRECHARGE.RAS Active Time (tRAS) is the minimum wait time from an ACTIVATE (row access) to bank PRECHARGE.
Both times must be satisfied before the bank can be precharged. Perhaps I wasn't quite clear enough on this point. I hope this clears things up.
kalniel - Monday, August 16, 2010 - link
I think I've got it now, thanks. My brain saw the relevant diagram and screamed 'Cthulu' instead.