AMD's 12-core "Magny-Cours" Opteron 6174 vs. Intel's 6-core Xeon
by Johan De Gelas on March 29, 2010 12:00 AM EST- Posted in
- IT Computing
Rendering: Blender 2.5 Alpha 2
| Blender 2.5 Alpha 2 | |
| Operating System | Windows 2008 Enterprise R2 (64-bit) |
| Software | Blender 2.5 Alpha 2 |
| Benchmark software | Built-in render engine |
3dsmax 2010 crashed on almost all our servers. Granted, it is not meant to be run on a server but on a workstation. We’ll try some tests with Backburner later when the 2011 version is available. In the meantime, it is time for something less bloated and especially less expensive: Blender.
Blender has been getting a lot of positive attention and judging by its very fast growing community it is on its way to become one of the most popular 3D animation packages out there. The current stable version 2.49 can only render up to 8 threads. Blender 2.5 alpha 2 can go up to 64. To our surprise, the software was pretty stable, so we went ahead and started testing.
If you like, you can perform this benchmark very easily too. We used the “metallic robot”, a scene with rather complex lighting (reflections!) and raytracing. To make the benchmark more repetitive, we changed the following parameters:
- The resolution was set to 2560 x 1600
- Anti-alias was set to 16
- We disabled compositing in post processing
- Tiles were set to 8x8 (X=8, Y=8)
- Threads was set to auto (one thread per CPU is set).

Let us first check out the results on Windows 2008 R2:

At first the Opteron 6174 results were simply horrible: 44.6 seconds, slower than the dual Opteron six-core!
Ivan Paulos Tomé, the official maintainer of the Brazilian Blender 3D Wiki, gave us some interesting advice. The default number of tiles is apparently set of 5x5. This result in a short period of 100% CPU load on the Opteron 6174 and a long period where the CPU load drops below 30%. We first assumed that 8x6, two times as many tiles as the number of CPUs would be best. After some experimenting, we found that 8x8 is the best for all machines. The Xeons and six-core Opterons gained 10%, while the 12-core Opteron became 40% (!) faster. This underlines that the more cores you have, the harder they are to make good use of.
Blender can be run on several operating systems, so let us see what happens under 64 bit Linux (Suse SLES 11).
Rendering: Blender 2.5 Alpha 2 on SLES 11
| Blender 2.5 Alpha 2 | |
| Operating System | SUSE SLES 11, Linux Kernel 2.6.27.19-5-default SMP |
| Software | Blender 2.5 Alpha 2 |
| Benchmark software | Built-in render engine |
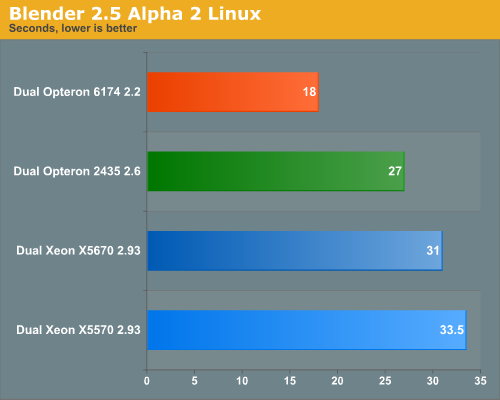
What happened here? Not only is Blender 50 to 70% faster on Linux, the tables have turned. As the software is still in Alpha 2 phase, it is good to take the results with a grain of salt, but still. For some reason, the Linux version is capable of keeping the cores fed much longer. On Windows, the first half of the benchmark is spent at 100% CPU load, and then it quickly goes down to 75, 50 and even 25% CPU load. In Linux, the CPU load, especially on the Opteron 6174 stays at 99-100% for much longer.
So is the Opteron 6174 the one to get? We are not sure. If these benchmarks are still accurate when we test with the final 2.5 version, there is a good chance that the octal-core 6136 2.4 GHz will be the Blender champion. It has a much lower price and slightly higher performance per core for less complex rendering work. We hope to follow up with new benchmarks. It is pretty amazing what Blender does with a massive number of cores. At the same time, we imagine Intel's engineers will quickly find out why the blender engine fails to make good use of the the dual Xeon X5670's 24 logical cores. This is far from over yet…








58 Comments
View All Comments
zarjad - Friday, April 2, 2010 - link
I understand that HT can be disabled in BIOS and that some benchmarks don't like HT.elnexus - Wednesday, April 21, 2010 - link
I can report that one of my customers, performing intensive image processing, found that DISABLING hyper-threading on a Nehalem-based workstation, actually IMPROVED performance considerably.It seems that certain applications don't like hyper-threading, while others do. I always recommend that my customers perform sensitivity analyses on their computing tasks with HT on and off, and then use whichever is best.
tracerburnout - Wednesday, March 31, 2010 - link
How is it possible that Intel's Xeon X5670 rig returns 19k+ for a score while AMD's magny-cours returns only 2k+?? I only question the results of this benchmark chart because Intel's Xeon X5570 rig returns only around 1k. How can a X5670 be 19x faster than a X5570?? And I doubt the same is true for the magny-cours by being just 10.5% of what the X5670 can do.(is there an extra '0' by accident in there?)
tracerburnout
proud supporter of AMD, with a few Intel rigs for Linux only
JohanAnandtech - Thursday, April 1, 2010 - link
No, it is just that Sisoft uses the new AES instructions of West-mere. It is a forward looking benchmark which tests only a small part of a larger website code base. So that 19x faster will probably result in 10 to 20% of the complete website being 19x faster. So the real performance impact will be a lot slower. It is interesting though to see how much faster these dedicated SIMD instructions are on these kinds of workloads.alpha754293 - Thursday, April 1, 2010 - link
If you guys need help with setting up or running the Fluent/LS-DYNA benchmarks let me know.I see that you don't really spend as much time writing or tweaking it as you do with some of the other programs, and that to me is a little concerning only because I don't think that it is showing the true potential of these processors if you run it straight out-of-the-box (especially with Fluent).
Fluent tends to have a LOT of iterations, but it also tends to short-stroke the CPU (i.e. the time required to complete all of the calculations necessary is less than 1 second and therefore; doesn't make full use of the computational ability.)
Also, the parallelization method (MPICH2 vs. HP MPI) makes a difference in the results.
You want to make sure that the CPUs are fully loaded for a period of time such that at each iteration, there should be a noticable dwell time AT 100% CPU load. Otherwise, it won't really demonstrate the computational ability.
With LS-DYNA, it also makes a difference whether it's SMP parallelization or MPP parallelization as well.
k_sarnath - Friday, April 2, 2010 - link
The most baffling part is how linux could engage 12-CPUs much better than windows. I am obviously curious about the OS platform for other tests.. Similary MS SQL was able to scale well on multi-cores... In this context, I am not sure how we can look at the performance numbers... A badly scaling app or OS could show the 12-core one in bad light.OneEng - Saturday, April 3, 2010 - link
Hi Johan,I have followed your articles from the early day's at Ace's and have a good respect for the technical accuracy of your articles.
It appears that the X5570 scaling between 4 and 8 cores has very little gain in the Oracle Calling Circle benchmark. Furthermore, the 24 cores of MC at 2.2Ghz are way behind. Westmere appears to do quite well, but really should not be able to best 8 cores in the X5570 with all else being equal.
I have heard some state that the benchmark is thread bound to a low number of threads (don't know if I am buying this), but surely something fishy is going on here.
It appears that there is either a real world application limit to core scaling on certain types of Oracle database applications (if there are, could you please explain what features an app has when these limits appear), or that the benchmark is flawed in some way.
I have a good amount of experience in Oracle applications and have usually found that more cores and more memory make Oracle happy. My experience seems at odds with your latest benchmarks.
Any feedback would be appreciated .... Thanks!
JohanAnandtech - Tuesday, April 6, 2010 - link
I am starting to suspect the same. I am going to dissect the benchmark soon to see what is up. It is not disk related, or at least that surely it is not our biggest problem. Our benchmark might not be far from the truth though, I think Oracle really likes the big L3-cache of the Westmere CPU.If you have other ideas, mail at johanATthiswebsiteP
heliosblitz2 - Wednesday, April 7, 2010 - link
You wroteTest-Setup:
Xeon Server 1: ASUS RS700-E6/RS4 barebone
Dual Intel Xeon "Gainestown" X5570 2.93GHz, Dual Intel Xeon “Westmere” X5670 2.93 GHz
6x4GB (24GB) ECC Registered DDR3-1333
"Also notice that the new Xeon 5600 handles DDR3-1333 a lot more efficiently. We measured 15% higher bandwidth from exactly the same DDR3-1333 DIMMs compared to the older Xeon 5570."
That is not exactly the reason, I think.
The reason ist you populated the second memory-bank in both setups.
Intel specification:
Westmere-1333MHZ-CPUs run with 1333 MHZ with second bank populated while
Nehalem-1333MHZ-CPUs run with 1066 MHZ with second bank populated
That could be updated.
Compare tech docs on Intel site: datasheet Xeon 5500 Part 2 and datasheet Xeon 5600 Part 2
Arnold.
gonerogue - Saturday, April 10, 2010 - link
The Viper is a V10 and most certainly not a traditional muscle car ;)