AMD's Radeon HD 5870: Bringing About the Next Generation Of GPUs
by Ryan Smith on September 23, 2009 9:00 AM EST- Posted in
- GPUs
Cypress: What’s New
With our refresher out of the way, let’s discuss what’s new in Cypress.
Starting at the SPU level, AMD has added a number of new hardware instructions to the SPUs and sped up the execution of other instruction, both in order to improve performance and to meet the requirements of various APIs. Among these changes are that some dot products have been reduced to single-cycle computation when they were previously multi-cycle affairs. DirectX 11 required operations such as bit count, insert, and extract have also been added. Furthermore denormal numbers have received some much-needed attention, and can now be handled at full speed.
Perhaps the most interesting instruction added however is an instruction for Sum of Absolute Differences (SAD). SAD is an instruction of great importance in video encoding and computer vision due to its use in motion estimation, and on the RV770 the lack of a native instruction requires emulating it in no less than 12 instructions. By adding a native SAD instruction, the time to compute a SAD has been reduced to a single clock cycle, and AMD believes that it will result in a significant (>2x) speedup in video encoding.
The clincher however is that SAD not an instruction that’s part of either DirectX 11 or OpenCL, meaning DirectX programs can’t call for it, and from the perspective of OpenCL it’s an extension. However these APIs leave the hardware open to do what it wants to, so AMD’s compiler can still use the instruction, it just has to know where to use it. By identifying the aforementioned long version of a SAD in code it’s fed, the compiler can replace that code with the native SAD, offering the native SAD speedup to any program in spite of the fact that it can’t directly call the SAD. Cool, isn’t it?
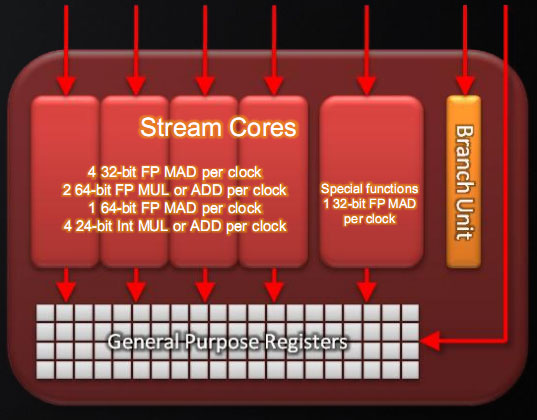
Last, here is a breakdown of what a single Cypress SP can do in a single clock cycle:
- 4 32-bit FP MAD per clock
- 2 64-bit FP MUL or ADD per clock
- 1 64-bit FP MAD per clock
- 4 24-bit Int MUL or ADD per clock
- SFU : 1 32-bit FP MAD per clock
Moving up the hierarchy, the next thing we have is the SIMD. Beyond the improvements in the SPs, the L1 texture cache located here has seen an improvement in speed. It’s now capable of fetching texture data at a blistering 1TB/sec. The actual size of the L1 texture cache has stayed at 16KB. Meanwhile a separate L1 cache has been added to the SIMDs for computational work, this one measuring 8KB. Also improving the computational performance of the SIMDs is the doubling of the local data share attached to each SIMD, which is now 32KB.

At a high level, the RV770 and Cypress SIMDs look very similar
The texture units located here have also been reworked. The first of these changes are that they can now read compressed AA color buffers, to better make use of the bandwidth they have. The second change to the texture units is to improve their interpolation speed by not doing interpolation. Interpolation has been moved to the SPs (this is part of DX11’s new Pull Model) which is much faster than having the texture unit do the job. The result is that a texture unit Cypress has a greater effective fillrate than one under RV770, and this will show up under synthetic tests in particular where the load-it and forget-it nature of the tests left RV770 interpolation bound. AMD’s specifications call for 68 billion bilinear filtered texels per second, a product of the improved texture units and the improved bandwidth to them.
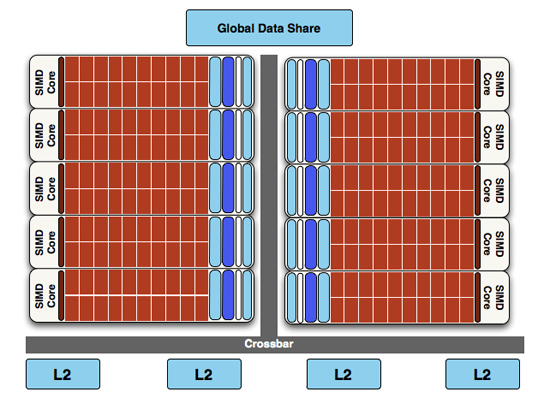
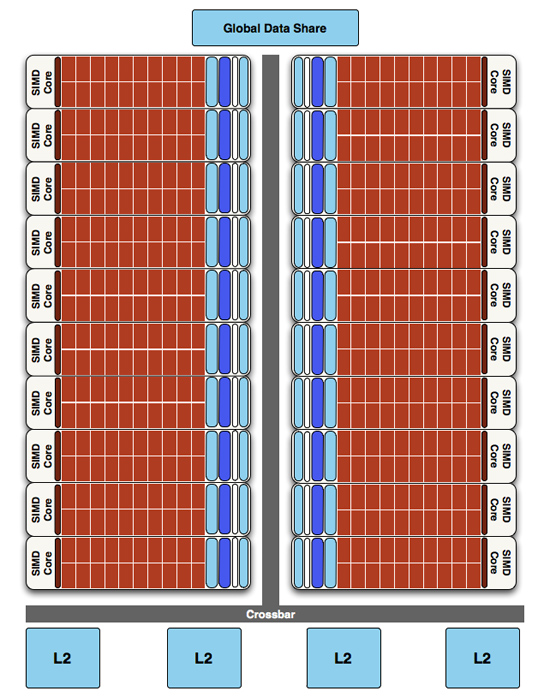
Finally, if we move up another level, here is where we see the cause of the majority of Cypress’s performance advantage over RV770. AMD has doubled the number of SIMDs, moving from 10 to 20. This means twice the number of SPs and twice the number of texture units; in fact just about every statistic that has doubled between RV770 and Cypress is a result of doubling the SIMDs. It’s simple in concept, but as the SIMDs contain the most important units, it’s quite effective in boosting performance.
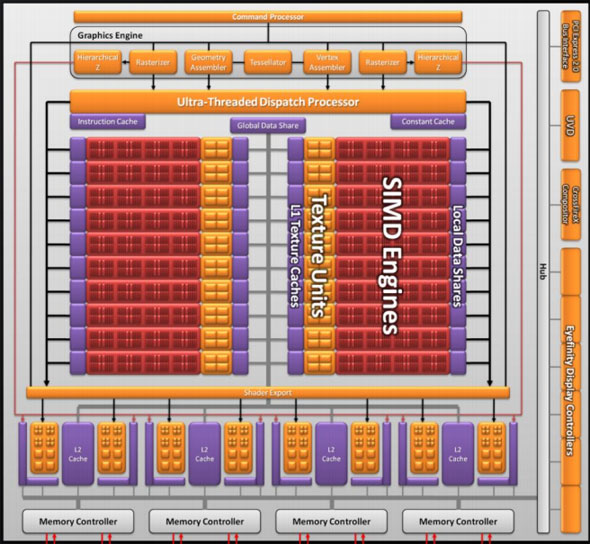
However with twice as many SIMDs, there comes a need to feed these additional SIMDs, and to do something with their products. To achieve this, the 4 L2 caches have been doubled from 64KB to 128KB. These large L2 caches can now feed data to L1 caches at 435GB/sec, up from 384GB/sec in RV770. Along with this the global data share has been quadrupled to 64KB.
RV770 vs...
Cypress
Next up, the ROPs have been doubled in order to meet the needs of processing data from all of those SIMDs. This brings Cypress to 32 ROPs. The ROPs themselves have also been slightly enhanced to improve their performance; they can now perform fast color clears, as it turns out some games were doing this hundreds of times between frames. They are also responsible for handling some aspects of AMD’s re-introduced Supersampling Anti-Aliasing mode, which we will get to later.
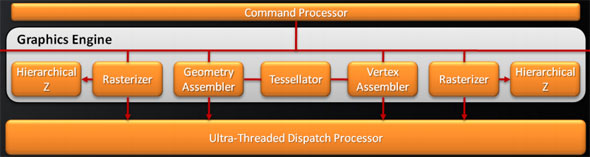
Last, but certainly not least, we have the changes to what AMD calls the “graphics engine”, primarily to bring it into compliance with DX11. RV770’s greatly underutilized tessellator has been upgraded to full DX11 compliance, giving it Hull Shader and Domain Shader capabilities, along with using a newer algorithm to reduce tessellation artifacts. A second rasterizer has also been added, ostensibly to feed the beast that is the 20 SIMDs.








327 Comments
View All Comments
silverblue - Saturday, September 26, 2009 - link
I think you may have been much happier with a 512-bit interface which would result in nearly 2.5x the bandwidth of the 4890, however it remains to be seen whether it'd be a waste or not. Having said that, it could mean for slower GDDR5 thus reducing costs, but wouldn't it be far more problematic to incorporate the wider bus anyway?If ATI throw out such a card with a single GPU on it, a direct comparison with the 5870 (and nVidia's top cards at the time) will be inevitable. The extra bandwidth may be rather under-utilised for anything less than Eyefinity gaming or Crysis at max details ;)
Now all we need is AMD to come back at Intel with a domestic release of its Thuban die (or hurry up with Bulldozer, sheesh) and it'll be a very, very exciting time for people to upgrade.
SiliconDoc - Sunday, September 27, 2009 - link
I want to know how the pinout compares on the 5870 gpu to the 4870/90.Have they doubled the data pins, or is the data jamming in and jamming out, even at 4800mhz ?
Maybe that's why 512bit would help.
Perhaps faster data rate ram, needs also a wider data path, more pins, more paths in and out of the gpu.
I will check the overclock sites that have already posted on this matter.
JarredWalton - Sunday, September 27, 2009 - link
I would assume that the pin count on 5870 isn't radically different from 4870. Granted, we know what assuming can get you, but with the same interface width there's not much reason for it to get substantially more pins. A few changes for power leads to deal with having more transistors, and other minor tweaks are likely, but my bet would be it's within 10% of the pin count of 4870.PorscheRacer - Monday, September 28, 2009 - link
For all those people clamoring on about why ATI didn't go with a 512-bit memory controller I'm going to chime in here with some ATI 512-bit experience. If you're a sharp one reading this, you have already guessed that means I'm going to talk about the R600. Now you can hate the card all you want, but I quite enjoyed this card. First of all, in the R600 it was the last ring-bus. It was a true 512-bit, and large memory controller. I'm not certain on the amount, but I believe it owned about a quarter of the realstate on the die. That's a lot. It also was some of the cause for the chip running hot and why UVD was scrapped from that chip to save room.Now, to keep that 512-bit ring-bus fed, you needed to push large amounts of data to it. The more you increased system bandwidth, the faster the card would be in any task. I've run hundreds of benchmarks over the years and I'm pretty sure Jared and Anand can attest to this. Same goes for overclocking the card. Raising the core didn't do much, but cranking up the VRAM to feed that hungry ring-bus sure did. Prices anyone? I believe $450 and up depending on where you were located. It was on heck of a pricey chip for ATI to make. Enter the die shrunk 3000 series with the 256-bit memory controller and voila. A cheaper chip to make. It never came close to the theoretical performance of the 2900XT, but the 3870 was about 90% of the performance for a lot cheaper. Yeas I know the cores were tweaked and so on in the 3000 series, but they are very similar.
If ATI ever went to a 512-bit bus, which means more PCB layers, higher cost in manufacturing and a larger die, I'd think they'd do it on something like Juniper or wait till 32nm. It's not feasible right now. They technically could go the MCM route with Juniper and get a mashed up version of a 512-bit bus, but I don't think the chips have been designed with that in mind.
Anyways, most computers out there are starved to feed something like the 5870 and higher cards with a 512-bit bus. I just replaced my R600 with an RV740 (hah, went from 80nm to 40nm) and now I don't need to OC the heck out of my bus to keep the card fed. I'm running an old FX-60 setup due to a glowing review on here back in early 2006. Am I the norm? NO, I'm waiting to upgrade. Is the Core i7 9xx the norm? No. You have to build a card to a certain set of people. I'm building my pal a new computer and he's happy with the 5850. The 5870 is overkill for him. It's 80% of the 5870 but a hundred bucks cheaper. Now, I'm sure ATI looked at the 512-bit bus in much the same way. "Wow, that 512-bit bus sure flies, look at those numbers! Oh, it's going to cost us this much die space and more manufacturing costs.... Well, those 256-bit bus numbers are still pretty imperssive and within 80% of the gaming benchmark scores, so we'll go that way"
Or something along those lines....I'm sure that's why nVIDIA's GTX300 is delayed. It's a massive chip, 512-bit bus and so on. Great, they'll take the performance crown again. Will they take my money? If they have something in the $200-$300 range, they have a fighting chance, just like ATI does, or soon to be Intel. Best price for performance will win me over there. I don't care what the bus size is, or how the card could have been better, just as long as I'm happy with the performance for my money. In which case, I'll be here looking forward to a GPU roundoup in the best bang for buck in that price range. Of course it will have DX11, or else there's no point in me upgrading again.
SiliconDoc - Wednesday, September 30, 2009 - link
The GT200 is a 512 bit bus.All the whining and complaining about difficulty means NOTHING.
ati goes the cheapskate sloppy lame route, cooks their cores, has 90C heat, few extra features, and a red raging fanbase filled with repeated tantric lies.
I even posted their own forum here with their 4850 90C+ whines, after some rooster told me his worst fan in the world on his 4850 kept it in the cool 60's like the several Nvidia cards, of course.
The 512bit HD2900 XTX was and is a great card, and even the 256 version still holds it's own. It was well over 500 bucks, was limited production, sold out quickly, and there was HD2900 512bit lesser version that could be flashed to full XTX with a bios upgrade, and it disappeared after it went well over $500.
That HD2900XTX has 115GB bandwidth.
It was REAL competition for the 8800GTX.
--
Of course ati cheaped out on producing any decent quantity, has been losing money, overcharged for it (and got it - but apparently like RUIZ, the "leadership" qualifies for "MORONS!"
---
Now, we'll hear endless crying about expense, about 512bit, and endless crying about core size (nvidia's giant monster), then we'll hear how ati just kicks butt because more dies to a wafer, and they can make a profit, and they can then wipe out nvidia and make them lose money....
BUT JUST THE OPPOSITE HAS BEEN GOING ON FOR SOME NUMBER OF YEARS IN A ROW.
If ati is so pathetic it can't handle making 512bit and selling 512bit, well then , they're PATHETIC.
And, yes, it seems they are PATHETIC.
Someone ought to let ati know there's "competition" and the "competition" pumps out 512bit buses all the time.
I guess when ati "finally catches up to the modern world" they can put out a 512bit again.
In the mean time, they can stick with their cheap pcb with less layers, their cooking hot crammed full electromigration core, and have a bunch of looners that for the very first time in their lives, actually believe that the ghetto is better than Beverly Hills, because they goin fps shootin', man.
Oh, it's so very nice so many gamers have as advice and worry ati's imbalanced sheet and how they can maintain it at a higher level. Such a concern on their minds, a great excuse for why ati cheaps out. I've never seen so many gaming enthusiasts with so much whoring for a company's bottom line. At the same time, nvidia is seen as an evil profit center that throws money around influencing the game production industry. LOL
Yes, it's evil for big green to make money, employ reps, toss millions into game channels, be extremely flexible and pump out 20 differing flavors of cards, so it's not so boring, work so games run well on their product - yes what evil , evil ****rds.
...
Perhaps the little red brokers could cheer some more when they feel ati "has improved it bottom line" by producing a cheap, knocked down, thinner, smaller, hotter, less featured, more negative driver issues, red card, because gamers are so concerned with economics, that they love the billions dollar losers plotted and carried out plans, and hate the company rolling in dollars and helping pump out games and a huge variety of gaming cards...
LOL
Yeah, the last red card that really was worth something, the HD2900512XTX.
That's the other thing that is so funny from these little broker economy whizzes. After they start yakkin about ati's dirt cheap product scheme, it really burns em up that the real cadillac of videocards commands a higher price.
Well, there's a reason a better made, more expensive process, more featured, wider supported in games videocard, is higher priced.
"the great economists" then suddenly turn into raging little angry reds, screeching scalping and unfair and greedy... LOL
Oh it's a hoot.
Zak - Monday, October 5, 2009 - link
I like Nvidia cards too, but if I was a moderator here you'd be banned by now. Relax. Take a pill. No one takes you seriously any more.Z.
SiliconDoc - Saturday, September 26, 2009 - link
The core clock is not doubled, still 850.The memory data rate is not doubled 3600 to 4800.
The bus width is not doubled still 256.
The frame buffer is not doubled, still 1GB
--- From Article Page 1 below ---
" So what’s Cypress in a nutshell? It’s a RV790 (Radeon HD 4890) with virtually everything doubled,.."
---
Ok, so pay attention to the word "virtually".
JarredWalton - Saturday, September 26, 2009 - link
There's no need to double the bus... either double the RAM data rate or double the bus width and you accomplish the same thing. But in a nutshell, everything is doubled relative to HD 4890 except for bandwidth, which only improves by 23%. Similarly, everything is more than double the 4870X2, you don't even need to deal with CrossFire stuff, but the 4870X2 has 50% more total bandwidth.ATI almost certainly isn't completely bandwidth limited with 4890/4870X2, but I think 5870 might just be fast enough that it's running into bandwidth limitations. On the other hand, bandwidth limitations are largely dependent on the game and algorithm. For instance, the Quake/Quake World/Doom games have been extremely bandwidth intensive in the past, and some of the titles Anand tested fall into that category. However, I know of other games that appear to be far less dependent on bandwidth, and the more programmable stuff going on, the more important shader performance becomes.
In the past, Oblivion was a great example of this. NVIDIA's 7800/7900 cards had a lot of bandwidth relative to shader performance, while ATI went the other route. Oblivion was really a strong ATI title (X1800/X1900 series) up until NVIDIA released 8800, which greatly improved NVIDIA's shader performance. Most modern titles tend to be a combination of things.
SiliconDoc - Sunday, September 27, 2009 - link
Note: Edited for ease of response.Well noone makes double the ram data rate, there is NO SUCH DDR5. (No one ever said there was.)
None of it runs at 7200 for videocards.
NVIDIA is using the 512bit bus and 448bit+ on it's top cards, so what is ATI's problem, when that's the only thing available ? (They don't need it enough to increase the cost of the cards to get it.)
Furthermore, the core is still 850, so have the data pins in and out of the core doubled ? I RATHER DOUBT IT. (Obviously it didn't - the specs say it's 256-bit. Did you not read the post?)
So, concievably, we have twice the data to move, on the same core speed, with less than double the DATA PINS in and out. (No, we don't have twice the data to move, unless the 4890 totally maxed out what the RAM could provide. ATI doesn't think this happened, so they only marginally increased bandwidth.)
If the bandwidth is NOT the problem, as you so claim, why then since everything ELSE you say has doubled, the conclusion we have is the ATI core is not up to the task. (If it truly had doubled in every area, and performance didn't double, we'd have a problem. The conclusion sane people will draw is that ATI looked at cost and benefit and decided a 256-bit bus was sufficient for the present. Otherwise they'd need a more complex circuit board, which would increase complexity and cost.)
That's it, it's core tech is so much the same....
LOL
Just love those ATI arguments. (There was no argument, but I'm a troll so I created one!)
When the CORE is overclocked, we will see a framerate increase.
SOOOOO.....
Tell me how the core handles TWICE THE DATA in and out - unless it's pinout count has doubled ? Is ther that much wasted time on the 4890 pins - on the current 5870 pins ? (No one said the core handles twice as much data; theoretically it can, but then deeper buffers would help.)
It may handle double data or nearly internally, but that has to communicate with the ram- etc onboard.
SORRY, once again, not agreeing. (Agreeing with what, that the bandwidth only increased by 23%? Wow, that's amazing. You'd disagree if someone said the sun rises in the east, wouldn't you? Try reading next time before responding instead of arguing for the sake of argument.)
Zool - Sunday, September 27, 2009 - link
The meaning of cache on the gpu is so it doesnt need to read and write to dram memmory too often. The speed of texture cache on 5870 is 1 TB/sec and its sram. And thats just the texture chache. It just shows how much speed is needed to utilize that raw comuting power on the chip. They surely tested the chip with higher speed memory and ended with this bandwith compromis.Also u cant compare the bare peak bandwith. The type of memmory controler and the speed of the GPU(and also cache) should change the real world bandwith like we see with wideferent CPU models and speeds.
When u read xxx GB/s bandwith it doesnt mean it always this fast (they name it peak bandwith always).