AMD's Radeon HD 5870: Bringing About the Next Generation Of GPUs
by Ryan Smith on September 23, 2009 9:00 AM EST- Posted in
- GPUs
Cypress: What’s New
With our refresher out of the way, let’s discuss what’s new in Cypress.
Starting at the SPU level, AMD has added a number of new hardware instructions to the SPUs and sped up the execution of other instruction, both in order to improve performance and to meet the requirements of various APIs. Among these changes are that some dot products have been reduced to single-cycle computation when they were previously multi-cycle affairs. DirectX 11 required operations such as bit count, insert, and extract have also been added. Furthermore denormal numbers have received some much-needed attention, and can now be handled at full speed.
Perhaps the most interesting instruction added however is an instruction for Sum of Absolute Differences (SAD). SAD is an instruction of great importance in video encoding and computer vision due to its use in motion estimation, and on the RV770 the lack of a native instruction requires emulating it in no less than 12 instructions. By adding a native SAD instruction, the time to compute a SAD has been reduced to a single clock cycle, and AMD believes that it will result in a significant (>2x) speedup in video encoding.
The clincher however is that SAD not an instruction that’s part of either DirectX 11 or OpenCL, meaning DirectX programs can’t call for it, and from the perspective of OpenCL it’s an extension. However these APIs leave the hardware open to do what it wants to, so AMD’s compiler can still use the instruction, it just has to know where to use it. By identifying the aforementioned long version of a SAD in code it’s fed, the compiler can replace that code with the native SAD, offering the native SAD speedup to any program in spite of the fact that it can’t directly call the SAD. Cool, isn’t it?
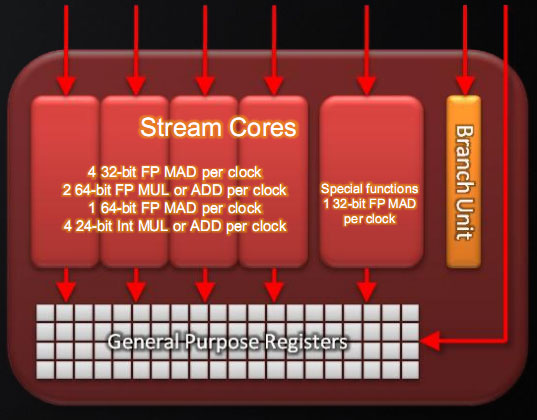
Last, here is a breakdown of what a single Cypress SP can do in a single clock cycle:
- 4 32-bit FP MAD per clock
- 2 64-bit FP MUL or ADD per clock
- 1 64-bit FP MAD per clock
- 4 24-bit Int MUL or ADD per clock
- SFU : 1 32-bit FP MAD per clock
Moving up the hierarchy, the next thing we have is the SIMD. Beyond the improvements in the SPs, the L1 texture cache located here has seen an improvement in speed. It’s now capable of fetching texture data at a blistering 1TB/sec. The actual size of the L1 texture cache has stayed at 16KB. Meanwhile a separate L1 cache has been added to the SIMDs for computational work, this one measuring 8KB. Also improving the computational performance of the SIMDs is the doubling of the local data share attached to each SIMD, which is now 32KB.

At a high level, the RV770 and Cypress SIMDs look very similar
The texture units located here have also been reworked. The first of these changes are that they can now read compressed AA color buffers, to better make use of the bandwidth they have. The second change to the texture units is to improve their interpolation speed by not doing interpolation. Interpolation has been moved to the SPs (this is part of DX11’s new Pull Model) which is much faster than having the texture unit do the job. The result is that a texture unit Cypress has a greater effective fillrate than one under RV770, and this will show up under synthetic tests in particular where the load-it and forget-it nature of the tests left RV770 interpolation bound. AMD’s specifications call for 68 billion bilinear filtered texels per second, a product of the improved texture units and the improved bandwidth to them.
Finally, if we move up another level, here is where we see the cause of the majority of Cypress’s performance advantage over RV770. AMD has doubled the number of SIMDs, moving from 10 to 20. This means twice the number of SPs and twice the number of texture units; in fact just about every statistic that has doubled between RV770 and Cypress is a result of doubling the SIMDs. It’s simple in concept, but as the SIMDs contain the most important units, it’s quite effective in boosting performance.
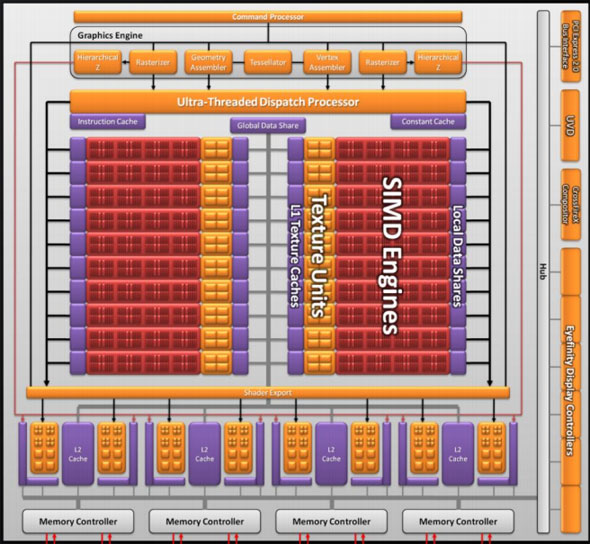
However with twice as many SIMDs, there comes a need to feed these additional SIMDs, and to do something with their products. To achieve this, the 4 L2 caches have been doubled from 64KB to 128KB. These large L2 caches can now feed data to L1 caches at 435GB/sec, up from 384GB/sec in RV770. Along with this the global data share has been quadrupled to 64KB.
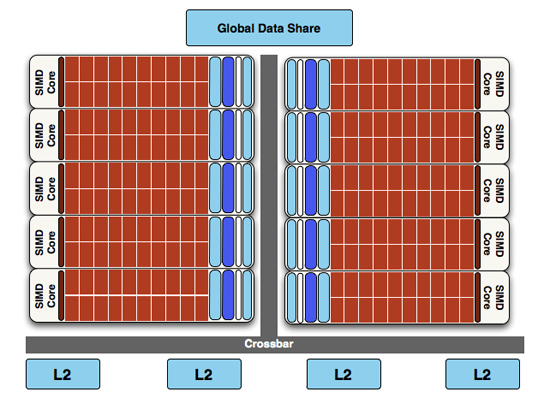
RV770 vs...
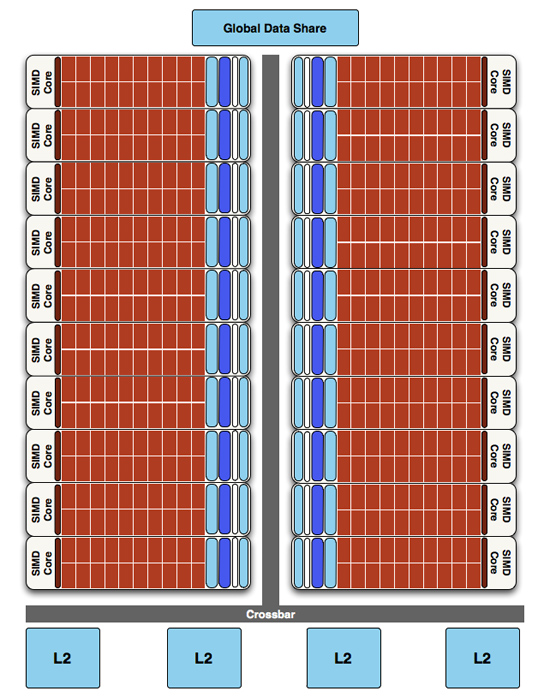
Cypress
Next up, the ROPs have been doubled in order to meet the needs of processing data from all of those SIMDs. This brings Cypress to 32 ROPs. The ROPs themselves have also been slightly enhanced to improve their performance; they can now perform fast color clears, as it turns out some games were doing this hundreds of times between frames. They are also responsible for handling some aspects of AMD’s re-introduced Supersampling Anti-Aliasing mode, which we will get to later.
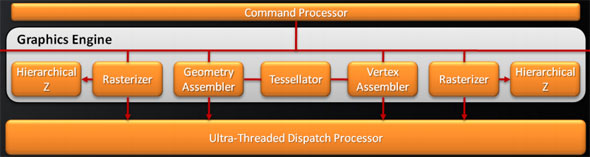
Last, but certainly not least, we have the changes to what AMD calls the “graphics engine”, primarily to bring it into compliance with DX11. RV770’s greatly underutilized tessellator has been upgraded to full DX11 compliance, giving it Hull Shader and Domain Shader capabilities, along with using a newer algorithm to reduce tessellation artifacts. A second rasterizer has also been added, ostensibly to feed the beast that is the 20 SIMDs.








327 Comments
View All Comments
dieselcat18 - Saturday, October 3, 2009 - link
It truly amazes me that AnandTech allows a Troll like you to keep posting...but there is always one moron that comes to a forum like this and shows his a** to the world...So we all know it to be you...nice work not bringing anything resembling an intelligent discussion to the table..Oh and please don't tell me what it is that I bring to the conversation...my thoughts about this topic have nothing to do with my reply to you about your vulgar manner and lack of respect for anyone that has a difference of opinion.Oh and as for you paper launch...well sites like Newegg were sold out immediately because of the overwhelming demand for this card and I'll bet you anything there are cards available and in good supply at this very moment...Why don't you take a look and give us all another update.....I guess having that big "L" stamped on your forehead sums it up.....
SiliconDoc - Wednesday, September 23, 2009 - link
No, they didn't, because the 5870's just showed up last night, 4 of them, and just a bit ago the ONE of them actually became "available", the Powercolor brand.The other three 5870's are NOT AVAILABLE but are listed....
So "ATI paper launch" is the key idea here (for non red roosters).
1:43 PM CST, Wed. Sept. 23rd, 2009.
---
Yes, I watched them appear on the egg last night(I'm such a red fanboy I even love paper launches)... LOL
crimson117 - Wednesday, September 23, 2009 - link
Current cheapest GTX 295 at Newegg is $469.99.http://www.newegg.com/Product/Product.aspx?Item=N8...">http://www.newegg.com/Product/Product.a...p;cm_re=...
B3an - Wednesday, September 23, 2009 - link
Ryan, on your AA page, you have an example of the unofficial Nvidia SSAA where the tree branches have gone missing in HL2. And say because of this it's not suitable for general use.But for both the ATI pics, on either MSAA or SSAA, the tree branches are missing as well. Did you not notice this? because you do not comment on it.
Either way it looks like ATI AA is still worse, or there is a bug.
Ryan Smith - Wednesday, September 23, 2009 - link
We used the same save game, but not the same computer. These were separate issues we were chasing down at the same time, so they're not meant to be comparable. In this case I believe some of the shots were at 1600x1200, and others were at 1680x1050. The result of which is that the widescreen shots are effectively back a bit farther due to the use of the same FOV at all times in HL2.As you'll see in our Crysis shots, there's no difference. I can look in to this issue later however, if you'd like.
chizow - Wednesday, September 23, 2009 - link
Really enjoyed the discussion of the architecture, new features, DX11, Compute Shaders, the new AF algorithm and the reintroduction of SSAA an ATI parts.As for the card itself, its definitely impressive for a single-GPU but the muted enthusiasm in your conclusion seems justified. Its not the definite leader for single-card performance as the 295 is still consistently faster and the 5870 even fails to consistently outperform its own predecessor, the 4870X2.
Its scaling problems are really odd given its internals and overall specs seem to indicate its just RV790 CF on a single die, yet it scales worst than the previous generation in CF. I'd say you're probably onto something thinking AMD underestimated the 5870's bandwidth requirements.
Anyways, nice card and nice effort from AMD, even if its stay at the top is short-lived. AMD did a better job pricing this time around and will undoubtedly enjoy high sales volume with little competition in the coming months with Win 7's launch, up until Nvidia is able to counter with GT300.
chizow - Wednesday, September 23, 2009 - link
Holy....lolI didn't even realize til I read another comment that Ryan Smith wrote this and not Anand/Derek collaboration. That's a compliment btw, it read very Anand-esque the entire time! ;-) Really enjoyed it similar to some of your earlier efforts like the 3-part Vista memory investigation.
formulav8 - Wednesday, September 23, 2009 - link
I wouldn't be surprised if most of us already knew what was going to take place with performance and what-not. But its still a nice card whether I knew the specs before its official release or not. (And viewed many purposely leak benches). :)Jason
PJABBER - Wednesday, September 23, 2009 - link
Another fine review and nice to see it hit today. Your reviews are one reason I keep coming back to AT!Unfortunately, at MSRP the 5870 doesn't offer enough for me to move past the 4890 I am currently using, and bought for $130 during one of the sales streaks a month or so ago. Will re-evaluate when we actually start seeing price drops and/or DX11 games hit the shelves.
wicko - Wednesday, September 23, 2009 - link
It would have been nice to see 4890 in CF against 5870 in CF. 500$ spent vs 800$ spent :p