NVIDIA's 1.4 Billion Transistor GPU: GT200 Arrives as the GeForce GTX 280 & 260
by Anand Lal Shimpi & Derek Wilson on June 16, 2008 9:00 AM EST- Posted in
- GPUs
Folding@home Now on NVIDIA
Folding@home, for those who don't know, is a distributed computing app designed to help researchers better understand the process of protien folding. Knowing more about how protiens assemble themselves can help us better understand many diseases such as alzheimers, but protien folding is very complex and takes a long time to simulate. the problem is made much easier by breaking it up into smaller parts and allowing many people to work on the problem.
Most of this work has been done on the CPU, but PS3 and AMD R5xx GPUs have been able to fold for a while now. Recently support for AMD's R6xx lineup was added as well. NVIDIA GPUs haven't been enabled to run folding@home until now (or very soon anyway). Stanford has finally implemented a version of folding@home with CUDA support that will allow all G80 and higher hardware to run the client.
We've had the chance for the past couple days to play around with a pre-beta version of the folding client, and running folding on NVIDIA hardwarwe is definitly very fast. Work units and protiens are different on CPUs and GPUs because the hardware is suited to different tasks, but to give some perspective a quadcore CPU could simulate tens of nanoseconds of a protien fold, while GPUs can simulate hundreds.
While we don't have the ability to bring you any useful comparative benchmarks right now, Stanford is working on implemeting some standard test cases that can be run on different hardware. This will help us actually compare the performance of different hardware in a meaningful way. Right now giving you numbers to compare CPUs, PS3s, AMD and NVIDIA GPUs would be like directly comparing framerates from different games on different hardware as if they were related.
What we will say is that NVIDIA predicts that the GTX 280 will be capable of simulating something between 5 and 6 hundred nanoseconds of folding per day while CPUs are going to be two orders of magnitude slower. They also show the GTX 280 handily ahead of any current AMD solutions by high margins, but until we can test it ourselves we really don't want to put a finer point on it.
In our tests, we've actually seen the GT200 folding client perform at between 600 and 850ns per day (using the timestamps in the log file to determine performance), so we are quite impressed. Work units complete about every 20 to 25 minutes depending on the protien and whether or not the viewer is running (which does have a significant impact since the calculations and the display are both running on the GPU).
Hardware H.264 Encoding
For years now both ATI and NVIDIA have been boasting about how much better their GPUs were for video encoding than Intel's CPUs. They promised multi-fold speedups in performance but never delivered, so we've been stuck encoding and transcoding videos on CPUs.
With the GT200, NVIDIA has taken one step closer to actually delivering on these promises. We got a copy of a severely limited beta of Elemental Technologies' BadaBOOM Media Converter:
The media converter currently only works on the GeForce GTX 280 and GTX 260, but when it ships there will be support for G80/G92 based GPUs as well. The arguably more frustrating issue with it today is its lack of support for CPU-based encoding, so we can't actually make an apples-to-apples comparison to CPUs or other GPUs. The demo will also only encode up to 2 minutes of video.
With that out of the way however, BadaBOOM will perform H.264 encoding on your GPU. There is still a significant amount of work being done on the CPU during the encode, our Core 2 Extreme QX9770 was at 20 - 30% CPU utilization during the entire encode process, but it's better than the 50 - 100% it would normally be at if we were encoding on the CPU alone.
Then there's the speedup. We can't perform a true apples-to-apples comparison since we can't use BadaBOOM's H.264 encoder on anything else, but compared to using the open source x264 encoder the performance speedup is pretty good. We used AutoMKV and played with its presets to vary quality:
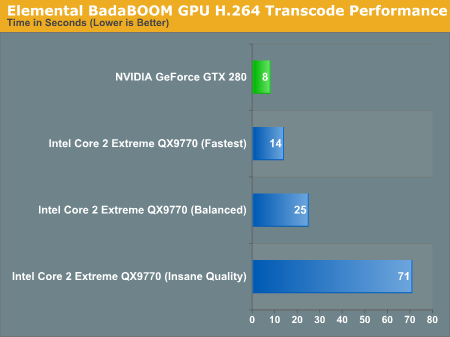
In the worst case scenario, the GTX 280 is around 40% faster than encoding on Intel's fastest CPU alone. In the best case scenario however, the GTX 280 can complete the encoding task in 1/10th the time.
We're not sure where a true apples-to-apples comparison would end up, but somewhere between those two extremes is probably a good guesstimate. Hopefully we'll see more examples of GPU based video encoder applications in the future as there seems to be a lot of potential here. Given how long it takes to encode a Blu-ray movie, we needn't even explain why it's necessary.








108 Comments
View All Comments
junkmonk - Monday, June 16, 2008 - link
I can has vertex data? LMFAO, hahha that was a good laugh.PrinceGaz - Monday, June 16, 2008 - link
When I looked at that, I assumed it must be a non-native English speaker who put that in the block. I'm still not entirely sure what it was trying to convey other than that the core will need to be fed with lots of vertices to keep it busy.Spoelie - Tuesday, June 17, 2008 - link
http://icanhascheezburger.com/">http://icanhascheezburger.com/http://icanhascheezburger.com/tag/cheezburger/">http://icanhascheezburger.com/tag/cheezburger/
chizow - Monday, June 16, 2008 - link
Its going to take some time to digest it all, but you two have done it again with a massive but highly readable write-up of a new complex microchip. You guys are still the best at what you do, but a few points I wanted to make:1) THANK YOU for the clock-for-clock comparo with G80. I haven't fully digested the results, but I disagree with your high-low increase thresholds being dependent on solely TMU and SP. You don't mention GT200 has 33% more ROP as well which I think was the most important addition to GT200.
2) The SP pipeline discussion was very interesting, I read through 3/4 of it and glanced over the last few paragraphs and it didn't seem like you really concluded the discussion by drawing on the relevance of NV's pipeline design. Is that why NV's SPs are so much better than ATI's, and why they perform so well compared to deep piped traditional CPUs? What I gathered was that NV's pipeline isn't nearly as rigid or static as traditional pipelines, meaning they're more efficient and less dependent on other data in the pipe.
3) I could've lived without the DX10.1 discussion and more hints at some DX10.1 AC/TWIMTBP conspiracy. You hinted at the main reason NV wouldn't include DX10.1 on this generation (ROI) then discount it in the same breath and make the leap to conspiracy theory. There's no doubt NV is throwing around market share/marketing muscle to make 10.1 irrelevant but does that come as any surprise if their best interest is maximizing ROI and their current gen parts already outperform the competition without DX10.1?
4) CPU bottlenecking seems to be a major issue in this high-end of GPUs with the X2/SLI solutions and now GT200 single-GPUs. I noticed this in a few of the other reviews where FPS results were flattening out at even 16x12 and 19x12 resolutions with 4GHz C2D/Qs. You'll even see it in a few of your benches at those higher (16/19x12) resolutions in QW:ET and even COD4 and those were with 4x AA. I'm sure the results would be very close to flat without AA.
That's all I can think of for now, but again another great job. I'll be reading/referencing it for the next few days I'm sure. Thanks again!
OccamsAftershave - Monday, June 16, 2008 - link
"If NVIDIA put the time in (or enlisted help) to make CUDA an ANSI or ISO standard extention to a programming language, we would could really start to get excited."Open standards are coming. For example, see Apple's OpenCL, coming in their next OS release.
http://news.yahoo.com/s/nf/20080612/bs_nf/60250">http://news.yahoo.com/s/nf/20080612/bs_nf/60250
ltcommanderdata - Monday, June 16, 2008 - link
At least AMD seems to be moving toward standardizing their GPGPU support.http://www.amd.com/us-en/Corporate/VirtualPressRoo...">http://www.amd.com/us-en/Corporate/VirtualPressRoo...
AMD has officially joined Apple's OpenCL initiative under the Khronos Compute Working Group.
Truthfully, with nVidia's statements about working with Apple on CUDA in the days leading up to WWDC, nVidia is probably on board with OpenCL too. It's just that their marketing people probably want to stick with their own CUDA branding for now, especially for the GT200 launch.
Oh, and with AMD's launch of the FireStream 9250, I don't suppose we could see benchmarks of it against the new Tesla?
paydirt - Monday, June 16, 2008 - link
tons of people reading this article and thinking "well, performance per cost, it's underwhelming (as a gaming graphics card)." What people are missing is that GPUs are quickly becoming the new supercomputers.ScythedBlade - Monday, June 16, 2008 - link
Lol ... anyone else catch that?Griswold - Monday, June 16, 2008 - link
Too expensive, too power hungry and according to other reviews, too loud for too little gain.The GT200 could become Nvidias R600.
Bring it on AMD, this is your big chance!
mczak - Monday, June 16, 2008 - link
G92 does not have 6 rop partitions - only 4 (this is also wrong in the diagram). Only G80 had 6.And please correct that history rewriting - that the FX failed against radeon 9700 had NOTHING to do with the "powerful compute core" vs. the high bandwidth (ok the high bandwidth did help), in fact quite the opposite - it was slow because the "powerful compute core" was wimpy compared to the r300 core. It definitely had a lot more flexibility but the compute throughput simply was more or less nonexistent, unless you used it with pre-ps20 shaders (where it could use its fx12 texture combiners).