NVIDIA's 1.4 Billion Transistor GPU: GT200 Arrives as the GeForce GTX 280 & 260
by Anand Lal Shimpi & Derek Wilson on June 16, 2008 9:00 AM EST- Posted in
- GPUs
Overclocked and 4GB of GDDR3 per Card: Tesla 10P
Now let's say that you want to get some real work done with NVIDIA's GT200 GPU but that 1.4 billion transistor chip just isn't enough. NVIDIA does have an answer for you, in the form of an overclocked GT200 with the 240 SPs running at 1.5GHz (up from 1.3GHz in the GTX 280) and with a full 4GB of GDDR3 memory on-board.

Today NVIDIA is also announcing their next generation Tesla product based on GT200 (called a T10P when used on Tesla for some reason). The workstation graphics guys will have to wait a while for a GT200 Quadro unfortunately. This new Tesla is similar to the older model in that it has much more RAM and no IO ports. The server version is also clocked higher than the desktop part because fan noise isn't an issue and data centers have lower ambient temperatures than some corner of an office under a desk.

The Tesla C1060 has an entire 4GB of RAM on board. This is obviously very large and will do well to accomodate the large scale scientific computing apps it is targeted at. This card is designed for use in workstations and is the little brother to the new monster server that is also being announced today.

The Tesla S1070 is a 1U server containing essentially 4 C1060 cards for a total of 16GBs of RAM on 960 SPs. This server, like the older version, connects to a server via a PCIe cable and is designed to run code written for CUDA at incredible speeds. With 120 double precision IEEE 754r floating point units in combination with the 960 single precision IEEE 754 units, this server is a viable option for many more projects than the previous Tesla hardware which was only capable of single precision floating point.
Though we don't have an application to benchmark the double precision floating point hardware on GT200 yet, NVIDIA states that a GT200 can roughly match an 8 core Xeon system in DP performance. This would put the S1070 on par with a 32 way Xeon setup at less than 700W. Needless to say, single precision code runs much much faster and can outpace hundreds of traditional CPUs in parallel.
While these servers are expensive (though we don't have pricing), they are cheap compared to the alternatives currently out there. The fact that CUDA code can be implemented and tested on any of the 70 million NVIDIA G80+ GPUs currently in people's hands means that developer already have a platform to test and debug code on before committing to the Tesla solution. On top of that, schools are beginning to adopt CUDA as a teaching tool for parallel computing. As CUDA gains acceptance and the benefits of GPU computing are realized, more and more major markets will take interest.
The graphics card is no longer a toy. The combination of CUDA's academic acceptance as a teaching tool and the availability of 64-bit floating point in GT200 make GPUs a mission critical computing tool that will act as a truly disruptive technology. Not only will many major markets that depend on high performance floating-point processing realize this, but every consumer with an NVIDIA graphics card will be able to take advantage of hundreds of gigaflops of performance from CUDA based consumer applications.
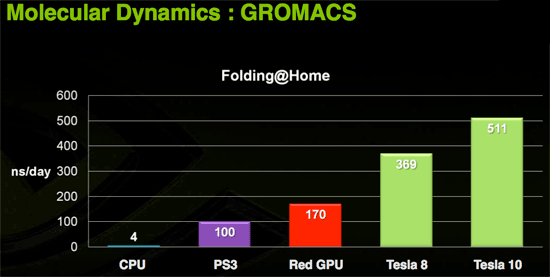
Today we have folding@home and soon we'll have Elemental's transcoder. Imagine the audio and video processing capabilities of a PC if the GPU were actively used in software like ProTools and Premier. Open source programs could easily best the processing capabilities of many solutions with dedicated hardware for these types of applications.
Of course, the major limiter to the adoption of this technology is that it is vendor specific. If NVIDIA put the time in (or enlisted help) to make CUDA an ANSI or ISO standard extention to a programming language, we would could really start to get excited. Beyond that, the holy grail would be a unification of virtualized instruction sets creating a standard low level "assembly" interface for GPU computing allowing CUDA to compile to one target and run on any graphics card. Sort of an x86 for massively parallel work.
Right now CUDA compiles to PTX, NVIDIA's virtual instruction set, and there is no reason someone couldn't write a CUDA compiler to target AMD's equivalent CAL (or even to develop a PTX to CAL wrapper that allowed AMD GPUs to run compiled CUDA code). Unfortunately, NVIDIA doesn't want to invest money and resources in extending functionality to AMD and AMD doesn't want to invest money and resources into bolstering an NVIDIA owned technology (that could theoretically radically change to cripple AMD's hardware support in future versions). While standards and cooperation are a great idea, the competition in this market is such that neither NVIDIA nor AMD are looking to take a chance on benefiting the consumer if there is any risk of strenthening the competition (even in spite of weakening the industry).








108 Comments
View All Comments
woofermazing - Tuesday, June 17, 2008 - link
Isn't the R700 high-end model going to have a direct link between the two cores. Could be a false rumor, but i would think that would solve a lot of problems with having two GPU's on a single board, since games would see it as 1 chip instead of a Crossfire/SLI setup. And besides, why the heck does it matter what the card looks like under the cooler. If it delivers better performance than Nvidia's offering without driver headaches, I don't think most gamers are going to care.VooDooAddict - Tuesday, June 17, 2008 - link
Why am I the only one happy about this product?Since the release of the 8800GTX top end single GPU performance has been a little stagnant... then came the refresh (8800GT/8800GTS-512) better prices came into effect.
Now we've got the new generation, and like in years prior, the new gen single GPU card has near performance of the previous gen in SLI. Price is also similar with when NVIDIA launched the first 8800GTX.
Sure, I wish they came in at a lower price point and at less power draw. (Same complaints that we had with the original 8800GTX). Lower power and lower price will come with a refresh.
Will I be getting one? ... nahh these cheap 9600GTs, overclocked 8800GT's and 8800GTSs will be the cards I recomend till i see the refresh. But I'm still happy there's progress.
I'm hoping the refresh hits around the same time as Intel's updated quad core.
DerekWilson - Tuesday, June 17, 2008 - link
i think its neat and has very interesting technology under the hood.but i'm not gonna spend that much money for something that doesn't deliver enough value (or even performance) compared to other solutions that are available. you pretty much reflect my own sentiment there: it's another step forward but not one that you're gonna buy.
i think people "don't like it" because of that though. it just isn't worth it right now and that's certainly valid.
greenx - Tuesday, June 17, 2008 - link
There are two ways I can look at this article.1)First an foremost at the heart of a real gamer ticks the need for good story lines fed by characters you will never forget, held by a gameplay you will fall in love with and finally covered by graphics that will transport you to another world (kinda like when I first played FF VII on my PC).
Within the context of the world we live in today I wonder what is really going through the minds of these people selling $600+ video cards. Kinda like those $10 000+ PCs. Madness. Sure they have their market up there but I shudder to think of how much money has been poured into appeasing a select few. Furthermore for what reason? Glory? I don't know but seeing as how the average gamer is what has made the PC/Gaming scene what it is, where does a $600+ video card fit into the grand scheme of things?
2) The possibilities that these new cards open up certainly seem exciting. The comparison with intel has been justified, but considering the other alternatives out there are much further ahead in development, who is going to bypass intel/amd/etc for a GPU technology based supercomputer?
DerekWilson - Tuesday, June 17, 2008 - link
two address point 2):developers will bypass Intel, AMD, SUN, whoever owns Cray these days, and all other HPC developers when a technology comes along that can speed up their applications by two orders of magnitude immediately on hardware that costs thousands (and in large cases millions) less to build, run and develop for.
evolucion8 - Tuesday, June 17, 2008 - link
LOL that was quite funny but incorrect as well, there's more than 4 Billion of people in China, in the future probably nVidia will launch a 4 Billion Transistors GPU hehe. It will require a Nuclear Reactor to turn it on, a and two of them to play games :D7Enigma - Wednesday, June 18, 2008 - link
4 Billion? Did you just make that out of thin air. Latest tabs show approximately 1.4 billion (give or take a couple hundred million). The world population is only estimated at 6.6 billion, so unless 60% of the people in the world are living in China, you're clueless.http://geography.about.com/od/populationgeography/...">http://geography.about.com/od/populationgeography/...
Bahadir - Tuesday, June 17, 2008 - link
Firstly I must say I enjoyed reading the whole article written by Anand Lal Shimpi & Derek Wilson. However, what does not make sense to me is the fact that "At most, 105 NVIDIA GT200 die can be produced on a single 300mm 65nm wafer from TSMC", but by looking at the wafer, only 95 full dies can be seen. Is this the wrong die?Also, it is not fair to compare the die of the Penryn against the GTX 280die because Penryn's die was made in 45nm process and GTX280 was made in 65nm die. Maybe it would be fair to compare it with the Conroe (65nm) die. But well done folks for putting an excellent article together!
Anand Lal Shimpi - Tuesday, June 17, 2008 - link
Thanks for your kind words btw :) Both of us really appreciate it - same to everyone else in this thread, thanks for making a ridiculously long couple of weeks (and a VERY long night) worth it :)-A
Anand Lal Shimpi - Tuesday, June 17, 2008 - link
You're right, there's actually a maximum of 94 usable die per wafer :)Take care,
Anand