Intel's 45nm Dual-Core E8500: The Best Just Got Better
by Kris Boughton on March 5, 2008 3:00 AM EST- Posted in
- CPUs
Determining a Processor Warranty Period
Like most electrical parts, a CPU's design lifetime is often measured in hours, or more specifically the product's mean time to failure (MTTF), which is simply the reciprocal of the failure rate. Failure rate can be defined as the frequency at which a system or component fails over time. A lower failure rate, or conversely a higher MTTF, suggests the product on average will continue to function for a longer time before experiencing a problem that either limits its useful application or altogether prevents further use. In the semiconductor industry, MTTF is often used in place of mean time between failures (MTBF), a common method of conveying product reliability with hard drive. MTBF suggests the item is capable of repair following failure, which is often not the case when it comes to discrete electrical components such as CPUs.
A particular processor product line's continuous failure rate, as modeled over time, is largely a function of operating temperature - that is, elevated operating temperatures lead to decreased product lifetimes. Which means, for a given target product lifetime, it is possible to derive with a certain degree of confidence - after accounting for all the worst-case end-of-life minimum reliability margins - a maximum rated operating temperature that produces no more than the acceptable number of product failures over a period of time. What's more, although none of Intel's processor lifetimes are expressly published, we can only assume the goal is somewhere near the three-year mark, which just so happens to correspond well with the three-year limited warranty provided to the original purchaser of any Intel boxed processor. (That last part was a joke; this is no accident.)
When it comes to semiconductors, there are three primary types of failures that can put an end to your CPU's life. The first, and probably the more well-known of the three, is called a hard failure, which can be said to have occurred whenever a single overstress incident can be identified as the primary root cause of the product's end of life. Examples of this type of failure would be the processor's exposure to an especially high core voltage, a recent period of operation at exceedingly elevated temperatures, or perhaps even a tragic ESD event. In any case, blame for the failure can be (or most often obviously should be) traced back and attributed to a known cause.
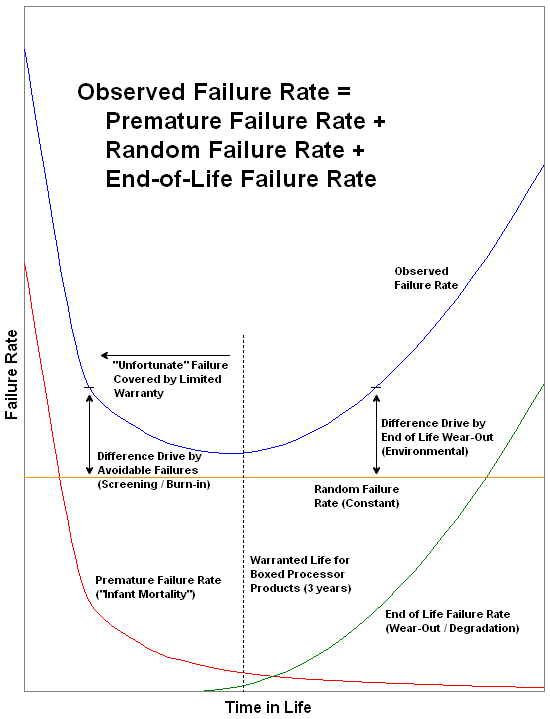
This is different from the second failure mode, known as a latent failure, in which a hidden defect or previously unnoted spot of damage from an earlier overstress event eventually brings about the component's untimely demise. These types of failure can lay dormant for many years, sometimes even for the life of the product, unless they are "coaxed" into existence. Several severity factors can be used to determine whether a latent failure will ultimately result in a complete system failure, one of those being the product's operating environment following the "injury." It is accepted that components subjected to a harsher operating environment will on average reach their end of life sooner than those not stressed nearly as hard. This particular failure mode is sometimes difficult to identify as without the proper post-mortem analysis it can be next to impossible to determine whether the product reached end-of-life due to a random failure or something more.
The third and final failure type, an early failure, is commonly referred to as "infant mortality". These failures occur soon after initial use, usually without any warning. What can be done about these seemingly unavoidable early failures? They are certainly not attributable to random failures, so by definition it should be possible to identify them and remove them via screening. One way to detect and remove these failures from the unit population is with a period of product testing known as "burn-in." Burn-in is the process by which the product is subjected to a battery of tests and periods of operation that sufficiently exercise the product to the point where these early failures can be caught prior to packaging for sale.
In the case of Intel CPUs, this process may even be conducted at elevated temperatures and voltages, known as "heat soaking." Once the product passes these initial inspections it is trustworthy enough to enter the market for continuous duty within rated specifications. Although this process can remove some of the weaker, more failure prone products from the retail pool - some of which might have very well gone on to lead a normal existence - the idea is that by identifying them earlier, fewer will come back as costly RMA requests. There's also the fact that large numbers of in-use failures can have a significant negative impact on the public perception of a company's ability to supply reliable products. Case in point: the mere mention of errata usually has most consumers up in arms before they are even aware of the applicability.
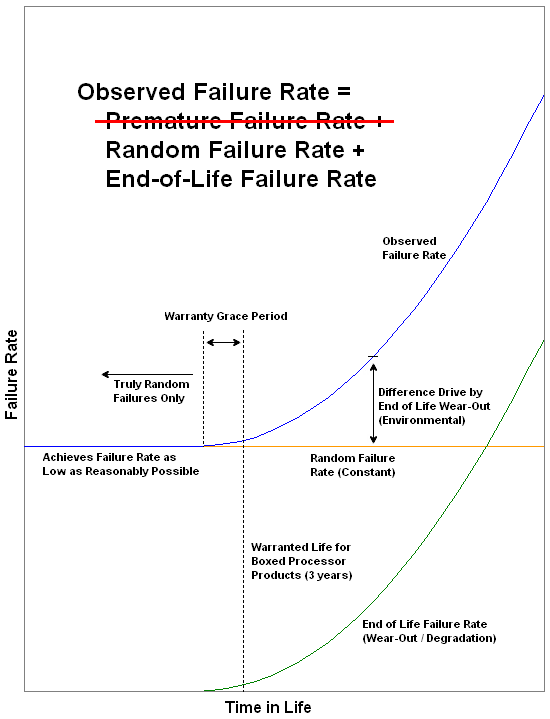
The graphic above illustrates how the observed failure rate is influenced by the removal of early failures. Because of this nearly every in-use failure can be credited as unavoidable and random in nature. By establishing environmental specifications and usage requirements that ensure near worry-free operation for the product's first three years of use, a "warranty grace period" can be offered. This removes all doubt as to whether the failure occurred because of a random event or the start of its eventual wear-out, where degradation starts to play a role in the observed failures.
Implementing process manufacturing, assembly, and testing advancements that lower the probability of random failures is a big part of improving any product's ultimate reliability rate. By carefully analyzing the operating characteristics of each new batch of processors, Intel is able to determine what works in achieving this goal and what doesn't. Changes that bring about significant improvements in product reliability - enough to offset the cost of a change to the manufacturing process - are sometimes implemented as a stepping change. The additional margin created by the change is often exploitable with respect to realizing greater overclocking potential. Let's discuss this further and see exactly what it means.








45 Comments
View All Comments
chizow - Wednesday, March 5, 2008 - link
Only had an issue with this statement:While this may be true for those building a new system around a new CPU, this might not hold true for those looking to overclock using an existing board. These 45nm CPUs with their higher stock 1333 FSB will by necessity use lower multipliers which essentially eats into potential FSB overclocks on FSB-limited chipsets. Considering many 6-series NV chipsets and boards will not support Penryn *at all* this is a very real consideration for those looking to upgrade to something faster.
Given my experiences with NV 6-series chipsets compared to reviews, I'm not overly optimistic about Penryn results on the 7-series either. Curious as to which board you tested these 45nm with? I haven't kept up with P35/X38 capabilities but the SS you showed had you dropping the multiplier which is a feature I thought was limited to NV chipsets? I might have missed it in the article, but clarification would be appreciated.
TheJian - Thursday, March 6, 2008 - link
I have a problem with this part of that statement "Intel has also worked hard to make all of this performance affordable." They forget it was AMD who forced Intel to cut margins on cpus from 62% (I think that was their high a few years back) to a meager 48% (if memory serves) and their profits to tank 60% in some quarters while driving AMD into the ground. Do they think they were doing it for our sakes? NOT. It was to kill AMD (and it worked). WE just got LUCKY.How much INTEL butt kissing can you do in one article? Notice that since AMD has sucked Intel is starting to make an ABOUT FACE on pricing. Server chips saw an increase of 20% about a month ago or so (it was written about everywhere). Now we see the E8400 which was $209 on newegg just a few weeks ago and IN STOCK, is said to go for $250 if you believe Anandtech. Even newegg has their future chips when they come back in stock now priced at $239. That's a $30 increase! What is that 14% or so? I missed the first E8400's and thought it would go down, instead Intel restricts volume and causes a price hike to soak us since AMD sucks now. I hope AMD puts out a decent chip shortly (phenom 3ghz would be a good start) so we can stop the price hikes.
What's funny to me is the reviewers let Intel get away with pricing in a review that comes nowhere near what it ACTUALLY debuts for. They've done the same for Nvidia also (not just anand, but others as well). The cards always end up being $50 more than MSRP. Which screws competitors because we all wait for said cheap cpu/gpu and end up not buying a very good alternative at the time (on the basis of false pricing from Intel/Nvidia). They should just start saying in reviews, "but expect $50 more upon debut than they say because they always LIE to get you to not buy the competitors product". That would at least be more accurate. For the record I just bought an 8800GT and will buy a wolfdate in a few weeks :) My problem here is the reviewers not calling them out on this crap. Why is that?
mindless1 - Wednesday, March 5, 2008 - link
Yes you are right that the higher default FSB works against them, it would be better if a Pentium or Celeron 45nm started with lower FSB so the chipsets had enough headroom for good overclock.NV is not the only one that can drop the multiplier, I've not tried it on X38 but have on P35 and see no reason why a motherboard manufacturer would drop such a desirable feature unless the board simply was barren of o'c features, something with OEM limited bios perhaps.
Psynaut - Wednesday, March 5, 2008 - link
It took me a minute to figure out that they were talking about the chips that were released 6-8 weeks ago.squito - Wednesday, March 5, 2008 - link
Same here ... maybe they need to be reintroduced?Johnbear007 - Wednesday, March 5, 2008 - link
Where in the U.S. do you see a Q6600 for under 200$???? I still see it at 245$ at newegg and your own anandtechshopping search doesn't come anywhere near the pricepoint you mention.XtAzY - Wednesday, March 5, 2008 - link
If you take a look at Hot Deals last month, you could have gotten a q6700 for $80http://hardforum.com/showpost.php?p=1032017513&...">http://hardforum.com/showpost.php?p=1032017513&...
but of course it's already over
smithkt - Wednesday, March 5, 2008 - link
That was for the e6700 not the q6700firewolfsm - Wednesday, March 5, 2008 - link
With core 2s, you can always do a minor frequency overclock while actually undervolting it. With a decent cooler, it could even last longer than stock.ap90033 - Wednesday, March 5, 2008 - link
Is it me or was this a little to negative on the OC stuff? I mean really, if you have good cooling, keep the voltage 1.44 or lower I bet the CPU would last 2-3 years or more...It almost sounds like they are marketing for Intel, "Great Overclokcer" but wait dont OC just get the highest model or it will only last 10 minutes!