Intel Penryn Performance Preview: The Fastest gets Faster
by Anand Lal Shimpi on April 18, 2007 8:00 AM EST- Posted in
- CPUs
The Test
First off we'll start with the results we ran ourselves under Intel's supervision. Intel set up three identical systems, one based on a Core 2 Extreme X6800 (dual core, 2.93GHz/1066MHz FSB), one based on a Wolfdale processor (Penryn, dual core, 3.20GHz/1066MHz FSB) and one based on Yorkfield (Penryn, quad core, 3.33GHz/1333MHz FSB).

The modified BadAxe 2 board; can you spot the mod?

Can't find it? It's under that blue heatsink
The processors were plugged into a modified Intel BadAxe2 motherboard, with the modification being necessary to support Penryn. Each system had 2GB of DDR2-800 memory and a GeForce 8800 GTX. All of our tests were run under Windows XP.
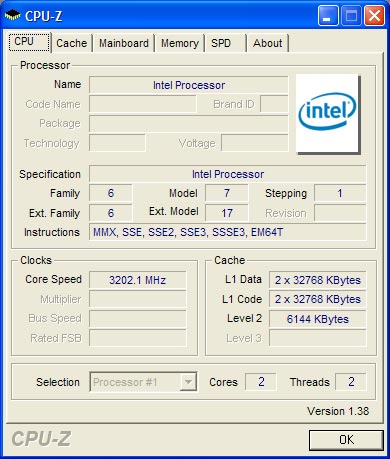
Wolfdale - 2 cores
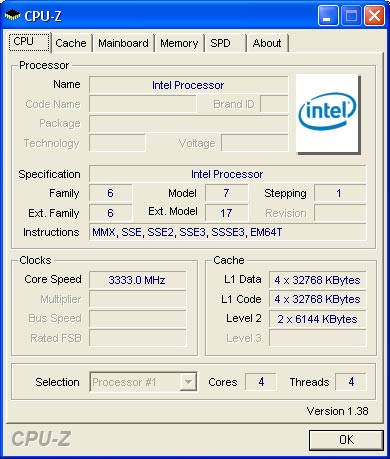
Yorkfield - 4 cores
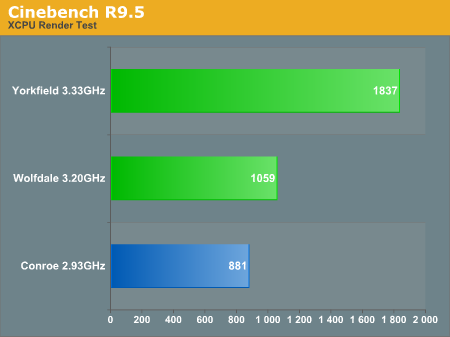
The Cinebench 9.5 test is the same one we run in our normal CPU reviews, with the dual core Penryn (Wolfdale) scoring about 20% faster than the dual core Conroe. Keep in mind that the Wolfdale core is running at a 9.2% higher clock speed, but even if Cinebench scaled perfectly with clock speed there's still at least a 10% increase in performance due to the micro-architectural improvements found in Penryn.
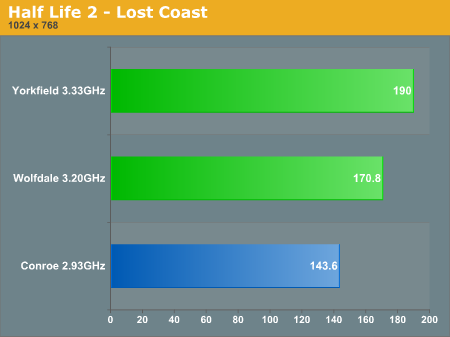
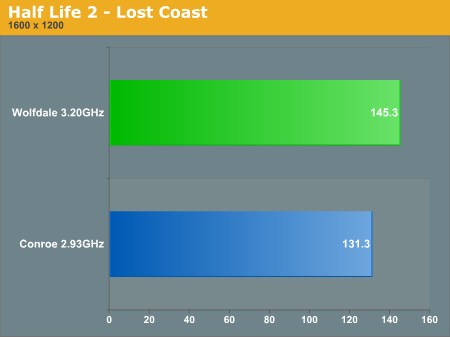
Next up was Intel's Half Life 2 Lost Coast benchmark which was run with the following settings:
| Setting | |
| Model Detail | High |
| Texture Detail | High |
| Shader Detail | High |
| Water Detail | Reflect World |
| Shadow Detail | High |
| Texture Filtering | Trilinear |
| HDR | Full |
Half Life 2 performance at a very CPU bound 1024 x 768 has Wolfdale just under 19% faster than Conroe. Once again, clock speed does play a part here but we'd expect at least a 10% increase in performance just due to the advancements in Penryn.
At 1600 x 1200 the performance difference shrinks to 10.6%, still quite respectable:








66 Comments
View All Comments
TA152H - Thursday, April 19, 2007 - link
OK, you clearly don't know what you're talking about.Pentium Pro didn't have an external cache, it was on the processor package itself, and ran at full CPU speed. The Pentium II was not faster than the Pentium Pro clock normalized, unless you ran 16-bit code or used MMX. The Pentium II and Katmai both were got progressively lower IPC as they got to higher clock speeds, except for the Katmai 600 MHz. The reason is simple, the cache wasn't any faster, except again in the 600 MHz version, and the memory ran at the same speed. So, each cycle you'd do worse. A Pentium Pro at 200 MHz had a higher IPC than a Katmai at 550 MHz, unless you were running instruction sets it didn't have. Also keep in mind there were Pentium Pros with 1 Meg cache (they sold for over 2k each!).
The Tualatin was not significantly faster than the Coppermine, it was the same processor except for a prefetch in the L2 cache. The Pentium III-S came with 512K cache, and considering the horrible memory bandwidth these processors had at multipliers of 10.5, it helped. But again, that's a problem the Pentium Pro didn't have since it ran at 4x multiplier.
The Pentium Pro, didn't even run 50% faster clock normalized than the Pentium. The Pentium Pro was the first processor Intel gave up on in terms of gaining huge IPC, and instead superpipelined it so they could get more clock cycles. Every prior generation ran at essentially the same speed on the same manufacturing process, and the main focus was on IPC. With the Pentium Pro it was a mixed focus, clock speed and some IPC. It wasn't 50% though, more like 30% IPC.
Floating point has always been much easier to improve than integer, and with Intel upping the ante with Core 2, AMD was also compelled to. Up until the 486, they didn't even include a floating point processor on the chip, and they were expensive add ons. Even with the 486, they later created a 486SX that had a disabled floating point unit. For most people, floating point doesn't matter at all. VIA chips have particularly poor floating point still, a few years ago they were running it at half speed. Some people clearly use it, mostly game players but also other apps. But most don't. Everyone uses integer. Everyone.
Your remarks about Yonah, et al, are off. Pentium M wasn't significantly faster than the Tualatin, nor was Yonah significantly faster than the Dothan. Actually, it was slower in some respects with the slow L2 cache. Again, I'm talking about integer, floating point is easy but it just doesn't matter as much. If you want floating point, why even bother with a crappy x86? Just get a Itanium and leave the dweebs with their x86 processors. I'm exaggerating, of course, some people need compatibility and decent floating point, but it's not not a huge space. Anyone doing serious floating point for engineering would be better off with a serious platform like the Itanium, and most people using computers don't use floating point. Unless you think alien blasters constitute 50% of the population. They don't. Most people grow up eventually and spend their time trying to capture Moscow :P.
defter - Wednesday, April 18, 2007 - link
No, but reducing latency of certain instructions (super shuffle, etc..) increases IPC.
Usually when people talk about IPC they refer to the REAL IPC, who cares about theoretical numbers? And for example, cache makes an impact on real IPC. You will not be executing many instructions if you are waiting data to arrive from the main memory....
fitten - Wednesday, April 18, 2007 - link
You can't hold IPC in a vacuum. Theoretically, every execution unit can execute in parallel. That's the maximum IPC that an architecture can have (modulo some things like retire rate, etc. but for simplicity that's good enough for an example) "Real" IPC comes from instruction streams from real programs. All sorts of things can interrupt IPC, good examples of this are branches and data hazards (instruction 2 depends on a result from instruction 1 to do its work so it obviously can't be executed completely in parallel).An instruction stream can have a maximum IPC as well and that is most often less than what the architecture it is running on is able to support. You can also recompile that program with better compilers that *may* (it is not guaranteed) extract more parallelism out of the instruction stream by deeper reordering of instructions, unrolling loops, etc. Some numbers thrown about are things like the average IPC of a typical x86 program is around 2.3. Certain applications may have higher average IPC.
Penryn running an existing application faster than Core2Duo can be attributed to many things. Assuming IPC is the only way this could happen is probably not completely accurate (due to the IPC allowed by the program itself). Optimizing a few commonly used instruction execution pathways and dropping them by a single clock (out of 5 to 10 total for the instruction) could also show improvement.
Anyway, without analysis of the applications, I guess we just have to take their word on what made it run faster.
DavenJ - Wednesday, April 18, 2007 - link
In my original posting above, I stated that IPC should increase by 5-10% depending on the application if you normalize for cache, clock frequency and FSB. SSE4 and other minor architectural improvements are going into this die shrink. So we have a little more than just a move from 65 nm to 45 nm. The point of my original comments were to point out that the hype regarding Penryn is way over-rated. Intel is trying to make it seem like they have some great new killer product here that should be equated to the original Core 2 launch. I do admit that there is some great tech going into the 45 nm shrink regarding transistor materials and the like, but this chip is going to be pretty much the same product you get today at a faster speed bin.Overclock your Core 2 Extreme QX6800 to 3.33 GHz and 1333 MHz FSB (the awesome Core 2 architecture will easily allow this on air) and run some benchmarks. You won't be far off the mark from the Penryn results displayed here. Those applications that use the extra L2 cache will be slightly higher and the rest will be about the same (no SSE4 applications out yet).
What Intel should be shouting at the rooftops and releasing the results to Anandtech and others is power draw of the chip. This chip is supposed to increase performance/watt way up but not a single data point was released towards this fact.
Either yields are bad or the PR spin is daft.
defter - Wednesday, April 18, 2007 - link
I don't that hype is overrated. 10% clock-to-clock improvement with higher clockspeed is nothing to sneeze at. When was the last time we got similar improvement in desktop space? Let's see
130nm K8 -> 90nm K8: no clock-to-clock improvement and initially lower clockspeed
90nm K8 -> 65nm K8: no clock-to-clock improvement and initially lower clockspeed
Northwood -> Prescott: no clock-to-clock improvement and higher power consumption
Prescott -> Presler: no clock-to-clock improvement
We need to go as far as to Willamette->Northwood transition that happened over 5 years ago to see similar results from a die shrink.
They have released it already. Check the last Penryn article, dual core Penryn based CPUs will have 65W TDP and quad core CPUs will have 130W TDP. I don't see any reasons why those demo system would have exceeded those values. Now, how many Kentsfield CPUs can work at 3.33GHz while mantaining 130W TDP?
Based on what facts are you making claims about yields???
Spoelie - Wednesday, April 18, 2007 - link
I do remember venice being faster than newcastle clock for clock... And I'm not talking about taking advantage of the extra SSE3 instructions.Wasn't much, up to a max of 5% or so, but yes it was there :p
defter - Thursday, April 19, 2007 - link
Venice wasn't AMD's first 90nm CPU, Winchester was. And there weren't any clock-to-clock improvement between Winchester and Newcastle.TA152H - Wednesday, April 18, 2007 - link
Not necessarily, it is much more probable that they are not on final silicon and the power use will drop when the release it. Actually, that's almost a certainty to be true, but speculation as to why.Put another way, why would you release numbers now when you know they will be much better when the product is introduced? You'd downgrade your processor for no apparent reason, and lose sales. Keep in mind purchasing decisions for big companies are planned and budgeted, and if you release bad numbers based on pre-release silicon, you are going to lose sales. Having spoken to Intel reps in the past, they are telling their customers, unofficially, what to expect from the chips in terms of power when it is released. They aren't telling them the current power use, of course, and they can't officially give the power use until they have chips that use it. That could be a disaster if things don't go exactly as planned.
coldpower27 - Wednesday, April 18, 2007 - link
And those are performance enhancing features, what is impressive is that these features are brought to you at the same power envelopes that existing Conroe's have now.No one is expecting a completely architectural overhaul here this is the cost cutting generation, the fact that is more then that this time around, is awesome.
DavenJ - Wednesday, April 18, 2007 - link
Why doesn't Anand overclock a quad-core QX6800 to 3.33 GHz and 1333 MHz FSB and compare the number then? That way, the chips are more identical except for cache.Take the new numbers, take off 5-10% of the performance because of the increased cache and then you would have a good clock for clock comparison to see what performance if any the new chip features have. I bet Penryn has negligible IPC increase over Core 2. This is a bunch of PR spin and nothing more.