Barcelona Architecture: AMD on the Counterattack
by Anand Lal Shimpi on March 1, 2007 12:05 AM EST- Posted in
- CPUs
Getting Spendy with Transistors - L3 cache
AMD lost the cache race to Intel long ago, but that's more of a result of manufacturing capacity than anything else. AMD knew it could not compete with Intel's ability to churn out more transistors on smaller processes faster, so it did the next best thing and integrated a memory controller. With the K8's on-die memory controller, AMD reduced the need for larger caches, which is why even current Athlon 64 X2s only have a 512KB L2 cache per core - a figure that Intel introduced back in 2002 with its Northwood core.
These days two Core 2 cores share up to 4MB of L2 cache, while the fastest offerings from AMD weigh in at half that. The gap will continue to widen with Barcelona, as each of its four cores will only have a 512KB L2 cache. While a quad-core Barcelona chip will have 2MB of total L2 cache for all four cores, a quad-core Kentsfield currently has 8MB of L2 cache for all four cores. By the end of this year, Intel's Penryn is expected to have 12MB of L2 cache for all of its cores.
In order to keep die sizes manageable, AMD constructed its quad-core Barcelona out of four cores each with a 128KB L1 and 512KB L2, much like most mainstream K8 based products today. However, the era of multithreaded applications demands that multi-core CPUs should have some common pool of high speed memory to keep them running at peak efficiency.
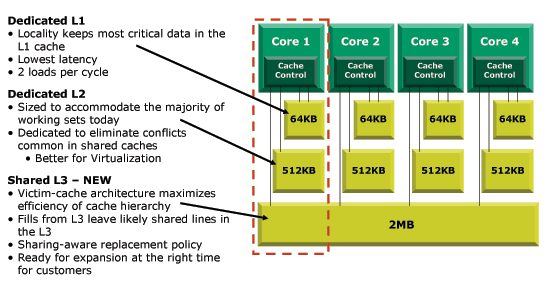
With four cores sharing a single die, AMD didn't want to complicate its design by introducing a large unified L2 cache. Instead, it took the K8 cache hierarchy and added a third level of cache to the mix - shared among all four cores. At 65nm, a quad-core Barcelona will have a 2MB L3 cache that is shared by all four cores.
The hierarchy in Barcelona works like this: the L2 caches are filled with victims from the L1 cache. When a cache gets full, data that was not recently used is evicted to make room for new data that the cache controller determines is good to keep in the cache. In a victim cache structure, the evicted data is placed in a storage area known as a victim cache instead of being removed from cache all together. If the data should become useful again, the cache controller simply has to fetch it from the victim cache rather than much slower main memory; victims from Barcelona's L1 are kicked out to the L2 cache.
The new L3 cache, acts as a victim for the L2 cache. So when the small L2 cache fills up, evicted data is sent to the larger L3 cache where it is kept until space is needed. The algorithms that govern the L3 cache's operation are designed to accommodate data that is likely to be needed by multiple cores. If the CPU fetches a bit of code, a copy is left in the L3 cache since the code is likely to be shared among the four cores. Pure data load requests however go through a separate process. The cache controller looks at history and if the data has been shared before, a copy will be left in the L3 cache; otherwise it will be invalidated.
Associativity hasn't been changed for the L1 and L2 caches; they are still 2-way and 16-way set associative, respectively. However, the new L3 cache is 32-way set associative. It has been designed to increase the hit rate of a relatively small cache compared to its competition.
AMD lost the cache race to Intel long ago, but that's more of a result of manufacturing capacity than anything else. AMD knew it could not compete with Intel's ability to churn out more transistors on smaller processes faster, so it did the next best thing and integrated a memory controller. With the K8's on-die memory controller, AMD reduced the need for larger caches, which is why even current Athlon 64 X2s only have a 512KB L2 cache per core - a figure that Intel introduced back in 2002 with its Northwood core.
These days two Core 2 cores share up to 4MB of L2 cache, while the fastest offerings from AMD weigh in at half that. The gap will continue to widen with Barcelona, as each of its four cores will only have a 512KB L2 cache. While a quad-core Barcelona chip will have 2MB of total L2 cache for all four cores, a quad-core Kentsfield currently has 8MB of L2 cache for all four cores. By the end of this year, Intel's Penryn is expected to have 12MB of L2 cache for all of its cores.
In order to keep die sizes manageable, AMD constructed its quad-core Barcelona out of four cores each with a 128KB L1 and 512KB L2, much like most mainstream K8 based products today. However, the era of multithreaded applications demands that multi-core CPUs should have some common pool of high speed memory to keep them running at peak efficiency.
With four cores sharing a single die, AMD didn't want to complicate its design by introducing a large unified L2 cache. Instead, it took the K8 cache hierarchy and added a third level of cache to the mix - shared among all four cores. At 65nm, a quad-core Barcelona will have a 2MB L3 cache that is shared by all four cores.
The hierarchy in Barcelona works like this: the L2 caches are filled with victims from the L1 cache. When a cache gets full, data that was not recently used is evicted to make room for new data that the cache controller determines is good to keep in the cache. In a victim cache structure, the evicted data is placed in a storage area known as a victim cache instead of being removed from cache all together. If the data should become useful again, the cache controller simply has to fetch it from the victim cache rather than much slower main memory; victims from Barcelona's L1 are kicked out to the L2 cache.
The new L3 cache, acts as a victim for the L2 cache. So when the small L2 cache fills up, evicted data is sent to the larger L3 cache where it is kept until space is needed. The algorithms that govern the L3 cache's operation are designed to accommodate data that is likely to be needed by multiple cores. If the CPU fetches a bit of code, a copy is left in the L3 cache since the code is likely to be shared among the four cores. Pure data load requests however go through a separate process. The cache controller looks at history and if the data has been shared before, a copy will be left in the L3 cache; otherwise it will be invalidated.
Associativity hasn't been changed for the L1 and L2 caches; they are still 2-way and 16-way set associative, respectively. However, the new L3 cache is 32-way set associative. It has been designed to increase the hit rate of a relatively small cache compared to its competition.








83 Comments
View All Comments
chucky2 - Friday, March 2, 2007 - link
Can you post the link that originates at AMD's own website then that says specifically that AM2+ CPU's are guaranteed to work - understandably maybe not supporting every new feature - in current AM2 boards?Not a news post from DailyTech, The Inquirer, Toms, whatever...one that's on AMD's site itself.
And No, AMD could make AM2+ completely incompatible with current AM2 boards and they probably wouldn't see much drop if at all from the large OEM's. The large OEM's would just ensure that when the AM2+ CPU's came in, AM2+ motherboards would likewise come in.
Believe me, I want to see the link...because I'm desperately awaiting 690G or MCP68, whichever comes first (which is probably MCP68 at the pace AMD is moving on 690G).
Chuck
yacoub - Thursday, March 1, 2007 - link
You say 128kb L1 per core but the diagram image just beneath that text shows a 64bit L1 cache. Please confirm which it is.
Thanks.
Awesome article, btw. Seems like quite a significant group of changes to the CPU. Looking forward to seeing how it stacks up against the best Quad Core2 Intel can offer. =)
yacoub - Thursday, March 1, 2007 - link
also, please forgive my hasty typing - I wrote "128kb" and "64bit" - I meant "128KB" and "64KB"JarredWalton - Thursday, March 1, 2007 - link
L1 is 128K total - 64K data and 64K instruction.Beenthere - Thursday, March 1, 2007 - link
AMD doesn't do knee-jerk reactions like Intel because AMD has superior products. AMD continues to take market share from Intel in every segment and Barcelona will continue that trend. Barcelona looks to be every bit as superior to Intel's hacked/patched/glued together chips as Opteron was when introduced. Intel's chips depend on huge cache size for their performance and that crutch won't work after the intro of Barcelona.For those without a clue, AMD didn't start design of Barcelona last week or last year. It's been in the development pipeline for many years and thr performance will demonstrate exactly why AMD's long term platform stability is the right choice for most enterprise buyers. Intel is gonna feel the pain again.
Roy2001 - Thursday, March 1, 2007 - link
Facts please, no BS.zsdersw - Thursday, March 1, 2007 - link
Idiocy incarnate.Regs - Thursday, March 1, 2007 - link
AMD, like Intel, start numerious projects. Just not all of them get to this finish line. Actually a lot of them don't even reach the end of the planning phase before being scratched.As for Intel and their large caches...well I'd say it's amazing how half their die (if not more) is used for cache and still had enough space for all the core logic that's kicking the crap out of the K8 now.
Common sense!
erwos - Thursday, March 1, 2007 - link
Looks like some good improvements coming down the pipe. The cache size issue makes me nervous, though - 512kb per core is starting to look a little antiquated, and there's no information about the bandwidth to the L3 cache (which, presumably, is slower than L2).SmokeRngs - Thursday, March 1, 2007 - link
In the past, AMD did not need the large cache sizes that Intel did for their processors. This was very obvious in regards to the Netburst architecture. However, while Core2 is much better than Netburst there are still disadvantages for Intel.I'll explain a little background as far as I understand it. In the K7 and Netburst days, Intel had to have the cache to make up for their long pipeline. Branch mispredictions are going to happen and the penalty on the long pipeline of the Netburst processors hurt their IPC badly. The shorter pipeline on the K7 did not have the same performance penalty due to the shorter pipeline. With K8, the on die memory controller also negated the need for large L2 caches due to the reduced latency when accessing main memory. This has been one of the major performance aspects for the K8 architecture.
The Core2 architecture obviously does not have the on die memory controller so the need for larger caches is still present and Intel sees improvement due to the larger caches. Barcelona still has the on die memory controller and the previous efficiency is still there and still negates the need for large caches. This is just the difference between architectures. While having a larger cache on the K8 did improve performance some in some usage scenarios, it wasn't on the same scale as the improvements Intel received with a larger cache.
AMD can't compete with Intel in regards to cache size. However, other architecture differences make up for the lack of large amounts of cache. Barcelona having a smaller cache does not seem to be a big problem. If it was a big problem, AMD probably would have gone with a larger cache to get the extra performance. Bigger does not always mean better or at least enough better to warrant the extra.
Smaller cache will mean fewer transistors which should mean better yields, lower power consumption and cheaper to produce.