The Intel Core Ultra 7 155H Review: Meteor Lake Marks A Fresh Start To Mobile CPUs
by Gavin Bonshor on April 11, 2024 8:30 AM ESTASUS Zenbook 14 OLED UX3405MA: AI Performance
As technology progresses at a breakneck pace, so do the demands of modern applications and workloads. As artificial intelligence (AI) and machine learning (ML) become increasingly intertwined with our daily computational tasks, it's paramount that our reviews evolve in tandem. To this end, we have AI and inferencing benchmarks in our CPU test suite for 2024.
Traditionally, CPU benchmarks have focused on various tasks, from arithmetic calculations to multimedia processing. However, with AI algorithms now driving features within some applications, from voice recognition to real-time data analysis, it's crucial to understand how modern processors handle these specific workloads. This is where our newly incorporated benchmarks come into play.
Given makers such as AMD with Ryzen AI and Intel with their Meteor Lake mobile platform feature AI-driven hardware, aptly named Intel AI Boost within the silicon, AI, and inferencing benchmarks will be a mainstay in our test suite as we go further into 2024 and beyond.
The Intel Core Ultra 7 155H includes the dedicated Neural Processing Unit (NPU) embedded within the SoC tile, which is capable of providing up to 11 TeraOPS (TOPS) of matrix math computational throughput. You can find more architectural information on Intel's NPU in our Meteor Lake architectural deep dive. While both AMD and Intel's implementation of AI engines within their Phoenix and Meteor Lake architectures is much simpler than true AI inferencing hardware, these NPUs are more designed to provide a high efficiency processor for handling light-to-modest AI workloads, rather than a boost to overall inferencing performance. For all of these mobile chips, the GPU is typically the next step up for truly heavy AI workloads that need maximum performance.
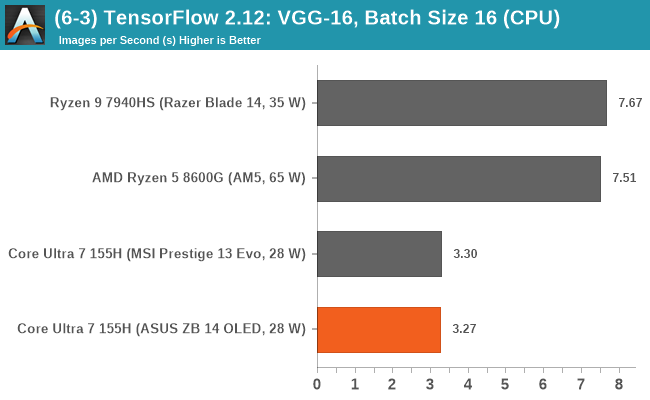
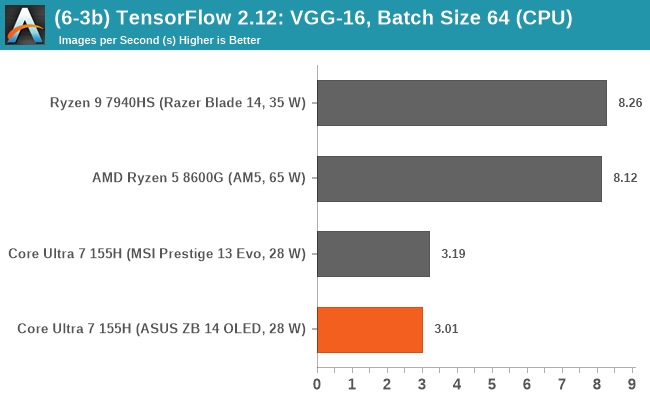
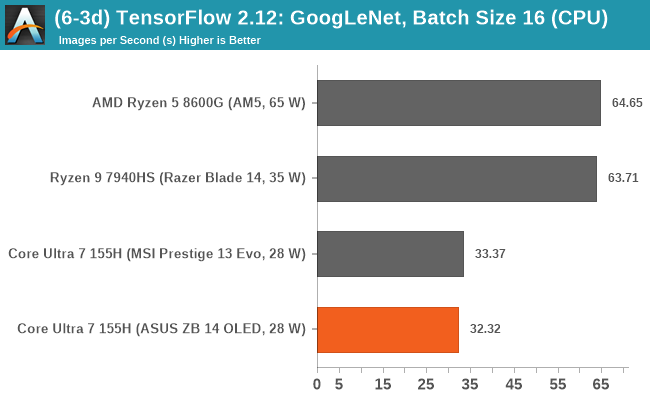
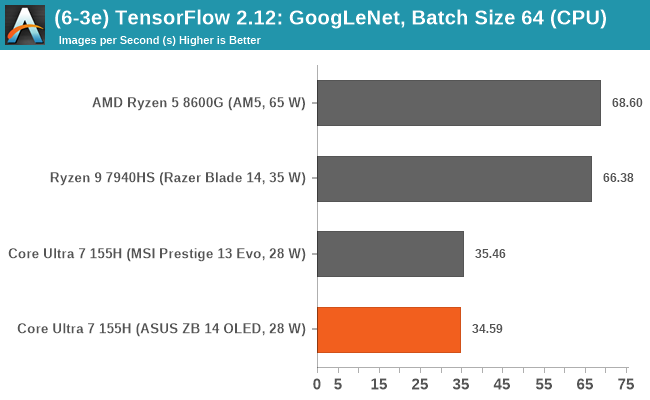
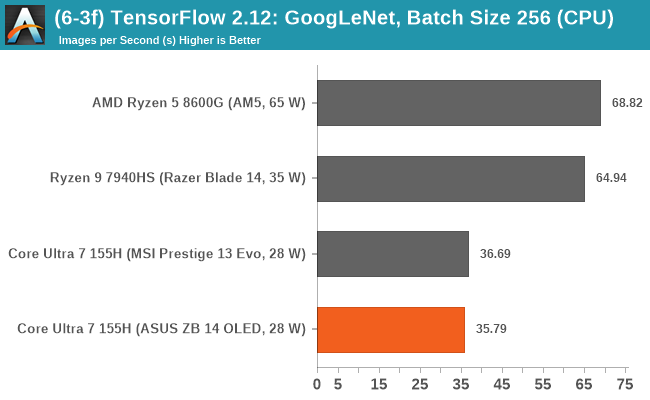
Looking at performance in our typical TensorFlow 2.12 inferencing benchmarks from our CPU suite, using both the VGG-16 and GoogLeNet models, we can see that the Intel Core Ultra 7 155H is no match for any of the AMD Phoenix-based chips.



Meanwhile, looking at inference performance on the hardware actually optimized for it – NPUs, and to a lesser extent, GPUs – UL's Procyon Computer Vision benchmark collection offers support for multiple execution backends, allowing it to be run on CPUs, GPUs, or NPUs. For Intel chips we're using the Intel OpenVINO backend, which enables access to Intel's NPU. Meanwhile AMD does not offer a custom execution backend for this test, so while Windows ML is available as a fallback option to access the CPU and the GPU, it does not have access to AMD's NPU.
With Meteor Lake's NPU active and running the INT8 version of the Procyon Computer Vision benchmarks, in Inception V4 and ResNet 50 we saw good gains in AI inferencing performance compared to using the CPU only. The Meteor Lake Arc Xe LPG graphics also did well, although the NPU is designed to be more power efficient with these workloads, and more often as not significantly outperforms the GPU at the same time.
This is just one test in a growing universe of NPU-accelerated appliations. But it helps to illustrate why hardware manufactuers are so interested in NPUs: they deliver a lot of performance for the power, at least as long as a workload is restricted enough that it can be run on an NPU.
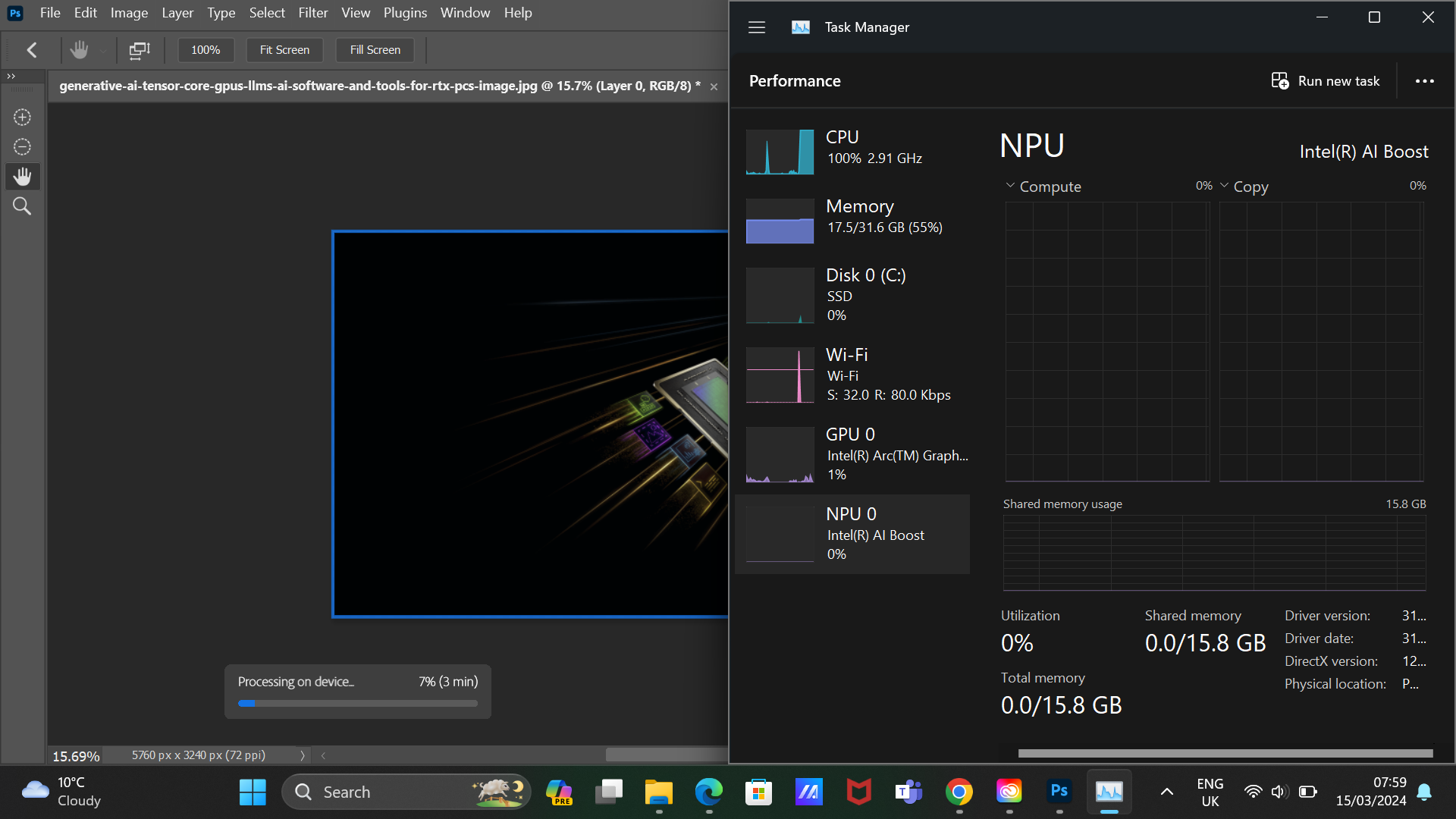
That all being said, even with the dedicated Intel AI Boost NPU within the SoC tile, the use case is very specific. Even trying generative AI within Adobe Photoshop using Neural fillers, Adobe was relying much more on the CPU than it was the GPU or the NPU, which shows that just because it's related to generative AI or inferencing, the NPU isn't always guaranteed to be used. This is still the very early days of NPUs, and even just benchmarking them for an active task remains an interesting challenge.








69 Comments
View All Comments
Gavin Bonshor - Friday, April 12, 2024 - link
I refer to it as a major gain; the other victories weren't huge. That was my point Replysjkpublic@gmail.com - Thursday, April 11, 2024 - link
Comparing the 155H to the 7940HS is apples to oranges. A better comparison would be the 185H. ReplyBigos - Thursday, April 11, 2024 - link
What happened to SPECint rate-N 502.gcc_r results? I do not believe desktop Raptor Lake is 16-40x faster than the mobile CPUs... ReplySarahKerrigan - Thursday, April 11, 2024 - link
No, something is clearly wrong there. I deal with SPEC a lot for work and that's an abnormally low result unless it was actually being run in rate-1 mode (ie, someone forgot to properly set the number of copies.) ReplyGavin Bonshor - Friday, April 12, 2024 - link
I am currently investigating this. Thank you for highlighting it. I have no idea how I missed this. I can only apologize Replymode_13h - Monday, April 15, 2024 - link
While we're talking about SPEC2017 scores, I'd like to add that I really miss the way your reviews used to feature the overall cumulative SPECfp and SPECint scores. It was useful in comparing overall performance, both of the systems included in your review and those from other reviews.To see what I mean, check out the bottom of this page: https://www.anandtech.com/show/17047/the-intel-12t... Reply
Ryan Smith - Monday, April 15, 2024 - link
That's helpful feedback. It's a bit late to add it to this article, but that's definitely something I'll keep in mind for the next one. Thanks! Replymode_13h - Wednesday, April 17, 2024 - link
You're quite welcome!BTW, I assume there's a "standard" way that SPEC computes those cumulative scores. Might want to look up how they do it, if the benchmark doesn't just compute them for you. If you come up with your own way of combining them, your cumulative scores probably won't be comparable to anyone else's. Reply
Ryan Smith - Wednesday, April 17, 2024 - link
"BTW, I assume there's a "standard" way that SPEC computes those cumulative scores."Yes, there is. We don't run all of the SPEC member tests for technical reasons, so there is some added complexity there. Reply
mczak - Thursday, April 11, 2024 - link
Obviously, the cluster topology description is wrong in the core to core latency measturements section, along with the hilarious conclusion the first two E-cores having only 5 ns latency to each other. (First two threads of course belong to a P-core, albeit I have no idea why the core enumeration is apparently 1P-8E-5P-2LPE.) Reply