Memory Bandwidth and Scaling
Everyone should already know that memory bandwidth improves with increases in memory speed and reductions in memory timings. To better understand the behavior of AM2 and Core 2 Duo memory bandwidth we used SiSoft Sandra 2007 Professional to provide a closer look at memory bandwidth scaling.
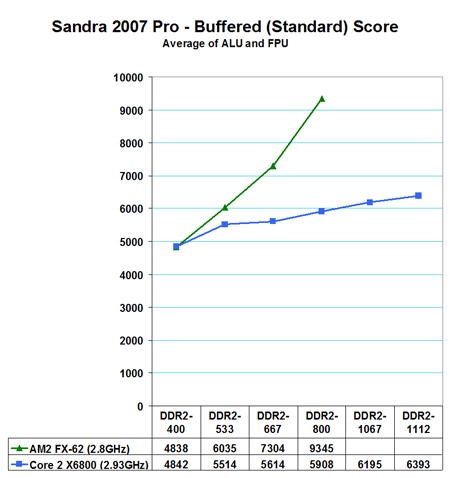
The most widely reported Sandra score is the Standard or Buffered memory score. This benchmark takes into account the buffering schemes like MMX, SSE, SSE2, SSE3, and other buffering tools that are used to improve memory performance. As you can clearly see in the Buffered result the AM2 on-chip memory controller holds a huge lead in bandwidth over Core 2 Duo. At DDR2-800 the AM2 lead in memory bandwidth is over 40%.
As we have been saying for years, however, the Buffered benchmark does not correlate well with real performance in games on the same computer. For that reason, our memory bandwidth tests have always included an UNBuffered Sandra memory score. The UNBuffered result turns off the buffering schemes, and we have found the results correlate well with real-world performance.
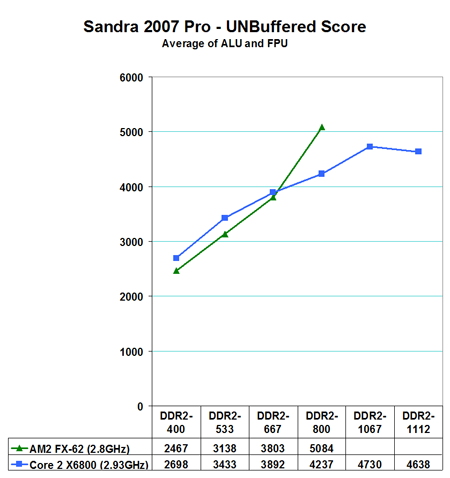
The Intel Core 2 Duo and AMD AM2 behave quite differently in UNBuferred tests. In these results AM2 and Core2 Duo are very close in memory bandwidth - much closer than in Standard tests. Core 2 Duo shows wider bandwidth below DDR2-800, but this will likely change when the AM2 controller matures and supports values below 3 in memory timings as the Core 2 Duo currently supports.
The Sandra memory score is really made up of both read and write operations. By taking a closer look at the Read and Write components we can get a clearer picture of how the two memory controllers operate. Everest from Lavalys provides benchmarking tools that can individually measure Read and Write operations.
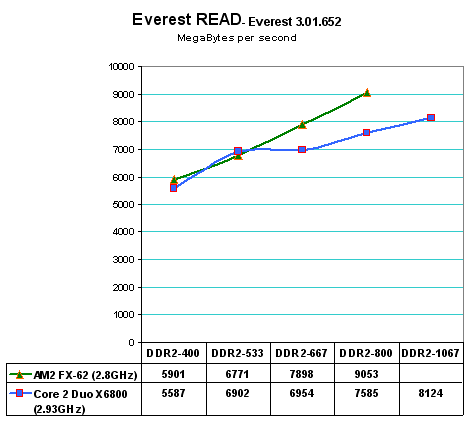
The READ results are particularly interesting, since you can see that the READ component of Core 2 Duo performance is much larger than the WRITE results on Core 2 Duo. This is the result of the intelligent read-aheads in memory which Intel has used to lower the apparent latency of memory on the Core 2 Duo platform. Actual READ performance on Core 2 Duo now looks almost the same as AM2 to DDR2-533. AM2 starts pulling away in READ at DDR2-677 and has a slightly steeper increase slope as memory speed increases. The increases in READ speed in Core 2 Duo are a result of the intelligent read-aheads in memory. Performance without this feature would show Core 2 Duo much slower in READ operations than AM2.
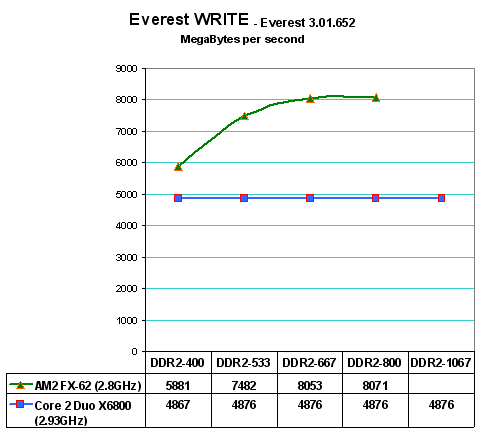
This is most clearly illustrated by looking at Everest Write scores. Memory read-ahead does not help when you are writing memory, so core 2 Duo exhibits much lower WRITE performance than AM2 as we would expect. This means if all else were equal (and it isn't) the AM2 would perform much better in Memory Write tasks. Surprisingly the WRITE component of Core 2 Duo appears a straight line just below 5000 MB/s. AM2 starts at 5900 at DDR2-400 and WRITE rises to around 8000MB/s at DDR2-667. Write then appears to level off, with higher memory speeds having little to no impact on AM2 WRITE performance.
Everyone should already know that memory bandwidth improves with increases in memory speed and reductions in memory timings. To better understand the behavior of AM2 and Core 2 Duo memory bandwidth we used SiSoft Sandra 2007 Professional to provide a closer look at memory bandwidth scaling.
The most widely reported Sandra score is the Standard or Buffered memory score. This benchmark takes into account the buffering schemes like MMX, SSE, SSE2, SSE3, and other buffering tools that are used to improve memory performance. As you can clearly see in the Buffered result the AM2 on-chip memory controller holds a huge lead in bandwidth over Core 2 Duo. At DDR2-800 the AM2 lead in memory bandwidth is over 40%.
As we have been saying for years, however, the Buffered benchmark does not correlate well with real performance in games on the same computer. For that reason, our memory bandwidth tests have always included an UNBuffered Sandra memory score. The UNBuffered result turns off the buffering schemes, and we have found the results correlate well with real-world performance.
The Intel Core 2 Duo and AMD AM2 behave quite differently in UNBuferred tests. In these results AM2 and Core2 Duo are very close in memory bandwidth - much closer than in Standard tests. Core 2 Duo shows wider bandwidth below DDR2-800, but this will likely change when the AM2 controller matures and supports values below 3 in memory timings as the Core 2 Duo currently supports.
The Sandra memory score is really made up of both read and write operations. By taking a closer look at the Read and Write components we can get a clearer picture of how the two memory controllers operate. Everest from Lavalys provides benchmarking tools that can individually measure Read and Write operations.
The READ results are particularly interesting, since you can see that the READ component of Core 2 Duo performance is much larger than the WRITE results on Core 2 Duo. This is the result of the intelligent read-aheads in memory which Intel has used to lower the apparent latency of memory on the Core 2 Duo platform. Actual READ performance on Core 2 Duo now looks almost the same as AM2 to DDR2-533. AM2 starts pulling away in READ at DDR2-677 and has a slightly steeper increase slope as memory speed increases. The increases in READ speed in Core 2 Duo are a result of the intelligent read-aheads in memory. Performance without this feature would show Core 2 Duo much slower in READ operations than AM2.
This is most clearly illustrated by looking at Everest Write scores. Memory read-ahead does not help when you are writing memory, so core 2 Duo exhibits much lower WRITE performance than AM2 as we would expect. This means if all else were equal (and it isn't) the AM2 would perform much better in Memory Write tasks. Surprisingly the WRITE component of Core 2 Duo appears a straight line just below 5000 MB/s. AM2 starts at 5900 at DDR2-400 and WRITE rises to around 8000MB/s at DDR2-667. Write then appears to level off, with higher memory speeds having little to no impact on AM2 WRITE performance.








118 Comments
View All Comments
Wesley Fink - Tuesday, July 25, 2006 - link
We purchased Everest and believed we were using the latest release version. The version we used for testing does support Core 2 Duo, but not with all the features supported in 3.01. We will update to version 3.01, rerun Everest tests, and post the new results in the review. This was an honest oversight, not a conspiracy.Wesley Fink - Tuesday, July 25, 2006 - link
Version 3.01 was just released July 16, 2006.saratoga - Tuesday, July 25, 2006 - link
Your instincts are right, those latency numbers are impossible. The prefeter is outsmarting your benchmark, and you're not measuring memory latency because a lot of the fetches are coming out of the L2. The reason latency numbers look so low is because L2 is quite a bit faster then memory ;)
I'm not sure that Intel actually developed prefetching. Its been used by the entire industry (Sun, Intel, AMD, IBM) for many, many years. What you have here is just a poor benchmark, not a breakthrough.
Which is the problem here. The page says "memory latency" which is flat out wrong. You simply are not getting 36 ns access time out of the combined FSB, memory controller and DRAM cells. It is not possible, and its a pretty big oversite IMO to claim otherwise.
If you want to test prefetcher, then go for it. Just don't call it memory latency, because the two are not the same thing.
sld - Tuesday, July 25, 2006 - link
So now ScienceMark is a turncoat too, after showing AMD superiority for the past year or so?Get a grip, people, as Everest has shown, memory latency on the Core 2 Duo is still higher than that on the K8.
What ScienceMark shows is that the prefetchers on the Core 2 Duo are brilliant, the results bear out and the Core 2 Duo beats the K8 in most (if not all) games convincingly (if I use superlatives, even if they are true, I'll contract rabies, you know) and does that clock-for-clock (not to mention $-for-$ until AMD generates a significant price crash).
All the while, I've been tolerating Intel fanboys crapping about non-existent benefits about their Netbust crap, and now you want me to tolerate the beginnings of AMD fanboyism too?
mino - Tuesday, July 25, 2006 - link
These numbers clearly show that siencemark developer does not tak into account 4M caches.It quite simple, at a the time of its creation 512k was considered a big cache.
As for SuprePI 1M - the same, 1M was chosen as standard no because it is a nice number, instead it was chosen because at the time there was no need for bigger datasets. Datasets for 1M _were_ simply big enough to show also memory perf., not just the size of the cache.
redpriest_ - Tuesday, July 25, 2006 - link
Actually, ScienceMark tests up to 16 MB of memory. See, I forsaw a day where this would be a problem and sized the test appropriately. What you're seeing is that the prefetcher is clever enough to pick up all the patterns we use to "fool" hardware prefetchers. This in itself is a great indicator of performance.Of course, our next revision will have a harder algorithm to fool, but I think we'll also keep the old one (because it still shows an important data point).
1 of 3 authors of SM2.0
mino - Tuesday, July 25, 2006 - link
Boys give us EDIT ..duploxxx - Tuesday, July 25, 2006 - link
Last months have given drastic changes in the cpu world for performance king and price.but the conclusion quality and review headers of anand are going further down day by day. (as a review site you should bring info to the world not fanboyism and sponser)come on such a statement to begin "Core 2 Duo (Conroe) launched about twelve days ago with a lot of fanfare. With the largest boost in real performance the industry has seen in almost a decade it is easy to understand the big splash Core 2 Duo has made in a very short time" do you really believe what you are saying or are you paid for each overmarketing comment you publish.
the article concept is nice looking at memory latency, but what cas level do you use at a rated speed, we al know that conroe is a better performer with any memory used but things change when the real cas latency is used, so a whole article without additional cas info is just a half article off no use. When things get realy interesting in page 7, you just stop performance comparisson on ddr2 1067 and 1112. i know its difficult because for now there is no devider to bring this memory to equal speed but you can clearly see that k8 is much more memory dependent that the conroe. conroe is saturated. in half life and quake bringing the memory to 1200 would give an equal performance.
looking at page 8 you convert the chart of page 7 to a nicer way to look :)
but for sure you changed the cas on the oc'ed fx down because looking at the linear performance gain from ddr-2 400 till ddr2-800, there is only gain due to the oc'ed fx and not due to the added memory bandwith. the gain is not linear to the performance gain on page 7.
I will hold my comments on for example the superpi... we all know wat its worth.
A review on 64bit or multithread performance would be nice to see how well the design is made for the future or are you as a review site restricted to some type of benchmarks?
same i asked on the server woodcrest. you bring benchmarks that are unable to compare. here you bring reviews where in the first line of the review you already have a conclusion and the benchmark contains not enough info to reflect in real life what to buy for memory and cas latency for example to get the desired performance.
OcHungry - Tuesday, July 25, 2006 - link
I concur with you. It is interesting that memory timings used was not mentioned in the review.Using 266x11 helps but it is not enough for AMD’s powerful IMC . If 330x9 was used instead it would have given AMD a considerable boost in performance. Anandtech is trying to show Core 2 duo is a better cpu, but fails to notice any improvement through utilization of IMC, memory latency and mem speed. What's funnier, is that the data provided, clearly shows a substantial increase in performance if memory speed is changed to 266mhz, 1:1 ratio. The increase in performance is at least by 5% across the benchmarks. My calculations show: for every 10% increase in memory speed, performance increases by 2%. Hence, running FX62 @ 330x9 amounts to 11% increase in performance. We know AMD is releasing an Improved IMC capable of utilizing memory speed in1T. 1T will increase performance by another 3-5%. The memory latency is another crucial factor for AMD. According to the author of this review: “ memory speed does not affect Conroe’s performance”. Great. But since latency tremendously affects AMD’s platforms it should have been considered to give us meaningful comparison. Most probably The timings used were: 4-4-4-12 (corsair DDR2 800). Tightening the timings to 3-3-3-8 would have given another 7% to 10% boost in FX62's performance.
If we add all the mentioned optimal settings for FX62: (11%+3%+7%) = 21% increase in performance should have resulted- which is fair, accurate, and represent the true comparison of FX62 against E6800.
Further more, 64bit OS and window vista is reported to give AMD about 16% improvement compared to 10% for conroe. This will give another 6% boost in performance for AMD’s platform that brings the total increase in performance to 27% washing clean all the superficial benchmarks(that were tilted ).
As far as gaming is concern, we know vid card is the deciding facto. So I believe AMD has position itself perfectly for every corner of the market.
To say Intel has captured the mid and high end of the market, is as erroneous as when Intel was pushing Netburst to capture gaming enthusiasts. We know that marchitecture and All that PR failed then, and will fail agin now.
IntelUser2000 - Tuesday, July 25, 2006 - link
My calculation says you are wrong. As much as my calculation is wrong, your logic/calculation is even moreso.
Have you looked at the performance gain that Athlon 64's gain with lower latencies?? Granted it was a single core Athlon 64, but people were still spreading bullshit that Athlon 64 will gain a lot from lower latencies. Yes it was in Anandtech forums!!
Tech-Report: http://techreport.com/etc/2005q4/mem-latency/index...">http://techreport.com/etc/2005q4/mem-latency/index...
Looking at Core 2 Duo, you can get BETTER performance with LOWER COST memory modules than A64. That means price/performance ratio goes FURTHER in Core 2's favor.
Not very many people think super ultra low latency is important, they are not stupid enough to spend extra $200 on memory that gives MAYBE 5% performance increase.
XS also telling you not to be stupid: http://www.xtremesystems.org/forums/showthread.php...">http://www.xtremesystems.org/forums/showthread.php...