Intel Unveils Meteor Lake Architecture: Intel 4 Heralds the Disaggregated Future of Mobile CPUs
by Gavin Bonshor on September 19, 2023 11:35 AM ESTIntel Meteor Lake: Changing The Strategy, Laying the Foundation for Intel 3
The strategy for both the Intel 4 process and the first architecture built on it, Meteor Lake, looks to change the dynamic for the mobile market and the foreseeable future of Intel's client processors. With the Foveros 3D packaging, opting for a power-conscious mobile platform seemed the best way to showcase their gains in terms of power efficiency.
One of the main product assembly advantages of Foveros packaging is that Intel can chop and change tiles depending on the processor, which includes current technologies, I/O, graphics, and compute cores. This approach to 3D tiled packaging also means that it is theoretically easier to introduce new tiles with faster cores with higher IPC performance, new graphics processors, and newer I/O, such as Wi-Fi 7. With Foveros not limiting Intel to use a single, monolithic die, it allows Intel to use different manufacturing processes for each of the tiles and integrate them onto the silicon. This is prevalent with the compute tile being built on Intel 4, while the graphics tile in Meteor Lake is made using TSMC's N5 node. This flexibility is key to advancing innovation, customizability, and, of course, wafer yield.
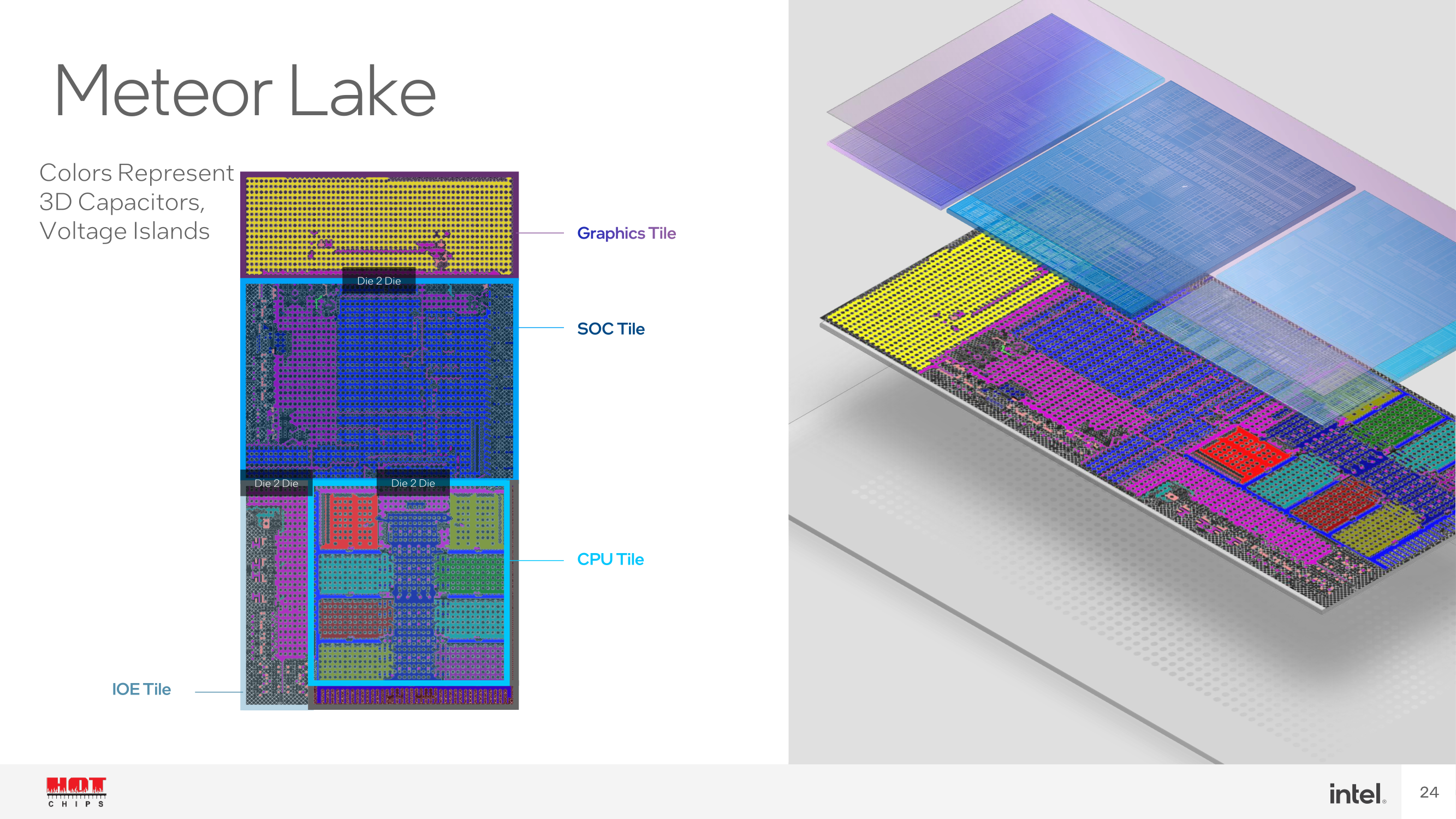
Intel Meteor Lake from Hot Chips Slide Deck
Intel also introduced a dedicated in-silicon AI engine through the NPU within the SoC tile. Similar to AMD with their Ryzen AI technology, Intel is looking to capitalize on the AI rush within its client-focused processors, but with support for OpenVINO and also including MCDM driver-compliance, users can do some pretty cool things with AI inferencing on the chip. Although these implementations aren't akin to the types of AI inferencing done in the cloud via ChatGPT with dedicated AI hardware, it's a step in the right direction in a world that looks to be slowly taken over by AI.

Wrapping things up, while Intel is confirming that Meteor Lake is coming to mobile-first, any details beyond that are slim pickings. At this point in time, Intel hasn't revealed anything in regard to SKUs or possible configurations. Everything disclosed is based on the 'full; Meteor Lake processors, but Intel hasn't spoken about different configurations or what the lower-end segment might look like regarding tiles and implementations. From their Hot Chips disclosures, offering a tiled architecture allows them to scale upwards and down depending on the SKU. The high-end SKU, which hasn't been disclosed yet, will feature the full configuration and implementation of all the features. Otherwise, the scalable nature of Meteor Lake and disaggregation allows for different levels of compute and graphics tiles and the ability to scale the input and output (I/O) depending on the device.
Meteor Lake will also be the first mobile platform from Intel to use their new Core naming scheme for products, which drops the 'i' from the Core branding. This includes the Core 3, 5, and 7, as well as higher spec Ultra 5, 7, and 9 Ultra tiers. Pat Gelsinger, Intel's Chief Executive Officer (CEO), during his opening keynote at Intel Innovation 2023, states that Intel is launching the first Meteor Lake Ultra (high-end) SKU with AI capabilities (NPU) on December 14th.

A tray of Meteor Lake Core Ultra processors (Credit, Intel)
We expect Intel to disclose more about specific SKUs and other specifications, such as clock speeds and core configurations, as we get closer to Meteor Lake's launch. Although we're expecting Ultra-focused Meteor Lake SKUs to launch on December 14th, no details on when we can expect other SKUs are set to hit retail channels. Meteor Lake is likely to launch with the top Ultra SKU or at least one that is close to the top of the stack.
Reading the tea leaves ahead of Innovation 2023, one gets the impression that Intel was hoping to be just a bit closer to launch by now than they actually are. But all things will eventually come in due time...








{kind=link}
107 Comments
View All Comments
GeoffreyA - Saturday, September 23, 2023 - link
I agree with most of what you're saying. What I was trying to get at is that there seems to be a belief that Apple has superior engineering ingenuity than Intel and AMD, when really, it is the difference between fixed- and variable-length instruction sets and all that entails. What I'd like to see is all of them on the same playing field and where each then stands, from a CPU point of view. Quite likely, there won't be much of a difference because good design principles are always the same. It's trying to be out of the ordinary that leads to Pentium 4s and Bulldozers.GeoffreyA - Saturday, September 23, 2023 - link
And yes, I'd like to see RISC-V winning in the end, rather than ARM.GeoffreyA - Saturday, September 23, 2023 - link
The thing is, ARM is almost fully ready on the Windows side of the coin. Windows on ARM appears to be working well, x64 emulation is up and running, increasingly more programs are getting ARM compiles, and Microsoft's VS and compilers now have ARM on an equal footing with x64. So, if Intel or AMD decided to make an ARM CPU, people could go over quite easily, similar to the early days of x64.FWhitTrampoline - Thursday, September 21, 2023 - link
Edit: royalist/encumberments to royalty/encumberments!And Firefox's Spell Checker is so bad that The Mozilla Foundation should be stripped of their Tax Exempt status until they fully comply and fix that.
Bluetooth - Saturday, September 23, 2023 - link
Intel has proposed X86-S ISA, to get rid of all the legacy code and boot directly into 64 bit, (the proposal is available on their website). But I don't know, if this is enough to allow them to build wider decoders to improve the single thread performance.GeoffreyA - Saturday, September 23, 2023 - link
I took a look at x86-S and it certainly would be welcome, getting rid of unnecessary legacy features. From my understanding, I don't think it would help to build wider decoders. The problem in x86 is that the length of each instruction varies and is not known beforehand. At execution time, length has got to be worked out in predecode, and I imagine this constrains how much can be sent through the decoders, as well as taking up a great deal of power. In the fixed-width ISA, it is trivial to know where each instruction starts and send them off to the decoders in mass. A bit like comparing a linked list with an array.FWhitTrampoline - Tuesday, September 19, 2023 - link
up to clocked 2Ghz+ should read: Clocked up to.Bluetooth - Saturday, September 23, 2023 - link
He may overstate the power, but don't diss his remark by only focusing on that error, as the mobile processor is running at much lower frequencies.tipoo - Tuesday, September 19, 2023 - link
It sounds like you carried forward 3W from 2008. The A17 Pro draws more power than ever.https://www.youtube.com/watch?v=TX_RQpMUNx0
StevoLincolnite - Tuesday, September 19, 2023 - link
He is nothing but a liar.