ATI's Late Response to G70 - Radeon X1800, X1600 and X1300
by Derek Wilson on October 5, 2005 11:05 AM EST- Posted in
- GPUs
Pipeline Layout and Details
The general layout of the pipeline is very familiar. We have some number of vertex pipelines feeding through a setup engine into a number of pixel pipelines. After fragment processing, data is sent to the back end for things like fog, alpha blending and Z compares. The hardware can easily be scaled down at multiple points; vertex pipes, pixel pipes, Z compare units, texture units, and the like can all be scaled independently. Here's an overview of the high end case.
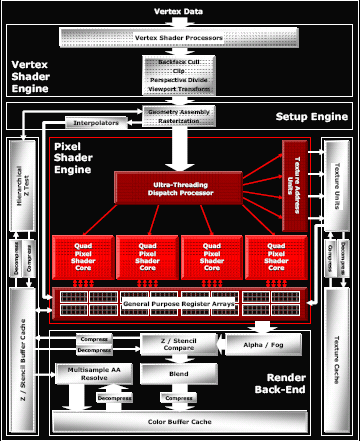
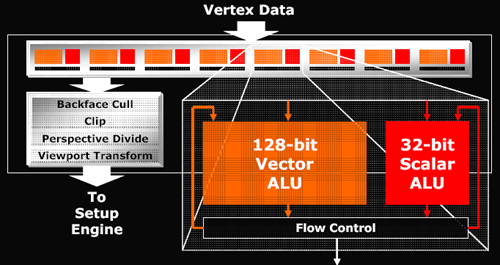
The maximum number of vertex pipelines in the X1000 series that it can handle is 8. Mid-range and budget parts incorporate 5 and 2 vertex units respectively. Each vertex pipeline is capable of one scalar and one vector operation per clock cycle. The hardware can support 1024 instruction shader programs, but much more can be done in those instructions with flow control for looping and branching.
After leaving the vertex pipelines and geometry setup hardware, the data makes its way to the "ultra threading" dispatch processor. This block of hardware is responsible for keeping the pixel pipelines fed and managing which threads are active and running at any given time. Since graphics architectures are inherently very parallel, quite a bit of scheduling work within a single thread can easily be done by the compiler. But as shader code is actually running, some instruction may need to wait on data from a texture fetch that hasn't completed or a branch whose outcome is yet to be determined. In these cases, rather than spin the clocks without doing any work, ATI can run the next set of instructions from another "thread" of data.
Threads are made up of 16 pixels each and up to 512 can be managed at one time (128 in mid-range and budget hardware). These threads aren't exactly like traditional CPU threads, as programmers do not have to create each one specifically. With graphics data, even with only one shader program running, a screen is automatically divided into many "threads" running the same program. When managing multiple threads, rather than requiring a context switch to process a different set of instructions running on different pixels, the GPU can keep multiple contexts open at the same time. In order to manage having any viable number of registers available to any of 512 threads, the hardware needs to manage a huge internal register file. But keeping as many threads, pixels, and instructions in flight at a time is key in managing and effectively hiding latency.
NVIDIA doesn't explicitly talk about hardware analogous to ATI's "ultra threading dispatch processor", but they must certainly have something to manage active pixels as well. We know from our previous NVIDIA coverage that they are able to keep hundreds of pixels in flight at a time in order to hide latency. It would not be possible or practical to give the driver complete control of scheduling and dispatching pixels as too much time would be wasted deciding what to do next.
We won't be able to answer specifically the question of which hardware is better at hiding latency. The hardware is so different and instructions will end up running through alternate paths on NVIDIA and ATI hardware. Scheduling quads, pixels, and instructions is one of the most important tasks that a GPU can do. Latency can be very high for some data and there is no excuse to let the vast parallelism of the hardware and dataset to go to waste without using it for hiding that latency. Unfortunately, there is just no test that we have currently to determine which hardware's method of scheduling is more efficient. All we can really do for now is look at the final performance offered in games to see which design appears "better".
One thing that we do know is that ATI is able to keep loop granularity smaller with their 16 pixel threads. Dynamic branching is dependant on the ability to do different things on different pixels. The efficiency of an algorithm breaks down if hardware requires that too many pixels follow the same path through a program. At the same time, the hardware gets more complicated (or performance breaks down) if every pixel were to be treated completely independently.
On NVIDIA hardware, programmers need to be careful to make sure that shader programs are designed to allow for about a thousand pixels at a time to take the same path through a shader. Performance is reduced if different directions through a branch need to be taken in small blocks of pixels. With ATI, every block of 16 pixels can take a different path through a shader. On G70 based hardware, blocks of a few hundred pixels should optimally take the same path. NV4x hardware requires larger blocks still - nearer to 900 in size. This tighter granularity possible on ATI hardware gives developers more freedom in how they design their shaders and take advantage of dynamic branching and flow control. Designing shaders to handle 32x32 blocks of pixels is more difficult than only needing to worry about 4x4 blocks of pixels.
After the code is finally scheduled and dispatched, we come to the pixel shader pipeline. ATI tightly groups pixel shaders in quads and is calling each block of pixel pipes a quad pixel shader core. This language indicates the tight grouping of quads that we already assumed existed on previous hardware.
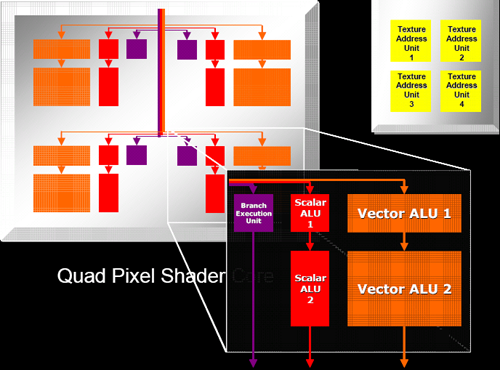
Each pixel pipe in a quad is able to handle 6 instructions per clock. This is basically the same as R4xx hardware except that ATI is now able to accommodate dynamic branching on their dedicated branch hardware. The 2 scalar, 2 vector, 1 texture per clock arrangement seems to have worked with ATI in the past enough for them to stick with it again, only adding 1 branch operation that can be issued in parallel with these 5 other instructions.
Of course, branches won't happen nearly as often as math and texture operations, so this hardware will likely be idle most of the time. In any case, having separate hardware for branching that can work in parallel with the rest of the pipeline does make relatively tight loops more efficient than what they could be if no other work could be done while a branch was being handled.
All in all, one of the more interesting things about the hardware is its modularity. ATI has been very careful to make each block of the chip independent of the rest. With high end hardware, as much of everything is packed in as possible, but with their mid-range solution, they are much more frugal. The X1600 line will incorporate 3 quads with 12 pixel pipes alongside only 4 texture units and 8 Z compare units. Contrast this to the X1300 and its 4 pixel pipes, 4 texture units and 4 Z compare units and the "16 of everything" X1800 and we can see that the architecture is quite flexible on every level.
The general layout of the pipeline is very familiar. We have some number of vertex pipelines feeding through a setup engine into a number of pixel pipelines. After fragment processing, data is sent to the back end for things like fog, alpha blending and Z compares. The hardware can easily be scaled down at multiple points; vertex pipes, pixel pipes, Z compare units, texture units, and the like can all be scaled independently. Here's an overview of the high end case.
The maximum number of vertex pipelines in the X1000 series that it can handle is 8. Mid-range and budget parts incorporate 5 and 2 vertex units respectively. Each vertex pipeline is capable of one scalar and one vector operation per clock cycle. The hardware can support 1024 instruction shader programs, but much more can be done in those instructions with flow control for looping and branching.
After leaving the vertex pipelines and geometry setup hardware, the data makes its way to the "ultra threading" dispatch processor. This block of hardware is responsible for keeping the pixel pipelines fed and managing which threads are active and running at any given time. Since graphics architectures are inherently very parallel, quite a bit of scheduling work within a single thread can easily be done by the compiler. But as shader code is actually running, some instruction may need to wait on data from a texture fetch that hasn't completed or a branch whose outcome is yet to be determined. In these cases, rather than spin the clocks without doing any work, ATI can run the next set of instructions from another "thread" of data.
Threads are made up of 16 pixels each and up to 512 can be managed at one time (128 in mid-range and budget hardware). These threads aren't exactly like traditional CPU threads, as programmers do not have to create each one specifically. With graphics data, even with only one shader program running, a screen is automatically divided into many "threads" running the same program. When managing multiple threads, rather than requiring a context switch to process a different set of instructions running on different pixels, the GPU can keep multiple contexts open at the same time. In order to manage having any viable number of registers available to any of 512 threads, the hardware needs to manage a huge internal register file. But keeping as many threads, pixels, and instructions in flight at a time is key in managing and effectively hiding latency.
NVIDIA doesn't explicitly talk about hardware analogous to ATI's "ultra threading dispatch processor", but they must certainly have something to manage active pixels as well. We know from our previous NVIDIA coverage that they are able to keep hundreds of pixels in flight at a time in order to hide latency. It would not be possible or practical to give the driver complete control of scheduling and dispatching pixels as too much time would be wasted deciding what to do next.
We won't be able to answer specifically the question of which hardware is better at hiding latency. The hardware is so different and instructions will end up running through alternate paths on NVIDIA and ATI hardware. Scheduling quads, pixels, and instructions is one of the most important tasks that a GPU can do. Latency can be very high for some data and there is no excuse to let the vast parallelism of the hardware and dataset to go to waste without using it for hiding that latency. Unfortunately, there is just no test that we have currently to determine which hardware's method of scheduling is more efficient. All we can really do for now is look at the final performance offered in games to see which design appears "better".
One thing that we do know is that ATI is able to keep loop granularity smaller with their 16 pixel threads. Dynamic branching is dependant on the ability to do different things on different pixels. The efficiency of an algorithm breaks down if hardware requires that too many pixels follow the same path through a program. At the same time, the hardware gets more complicated (or performance breaks down) if every pixel were to be treated completely independently.
On NVIDIA hardware, programmers need to be careful to make sure that shader programs are designed to allow for about a thousand pixels at a time to take the same path through a shader. Performance is reduced if different directions through a branch need to be taken in small blocks of pixels. With ATI, every block of 16 pixels can take a different path through a shader. On G70 based hardware, blocks of a few hundred pixels should optimally take the same path. NV4x hardware requires larger blocks still - nearer to 900 in size. This tighter granularity possible on ATI hardware gives developers more freedom in how they design their shaders and take advantage of dynamic branching and flow control. Designing shaders to handle 32x32 blocks of pixels is more difficult than only needing to worry about 4x4 blocks of pixels.
After the code is finally scheduled and dispatched, we come to the pixel shader pipeline. ATI tightly groups pixel shaders in quads and is calling each block of pixel pipes a quad pixel shader core. This language indicates the tight grouping of quads that we already assumed existed on previous hardware.
Each pixel pipe in a quad is able to handle 6 instructions per clock. This is basically the same as R4xx hardware except that ATI is now able to accommodate dynamic branching on their dedicated branch hardware. The 2 scalar, 2 vector, 1 texture per clock arrangement seems to have worked with ATI in the past enough for them to stick with it again, only adding 1 branch operation that can be issued in parallel with these 5 other instructions.
Of course, branches won't happen nearly as often as math and texture operations, so this hardware will likely be idle most of the time. In any case, having separate hardware for branching that can work in parallel with the rest of the pipeline does make relatively tight loops more efficient than what they could be if no other work could be done while a branch was being handled.
All in all, one of the more interesting things about the hardware is its modularity. ATI has been very careful to make each block of the chip independent of the rest. With high end hardware, as much of everything is packed in as possible, but with their mid-range solution, they are much more frugal. The X1600 line will incorporate 3 quads with 12 pixel pipes alongside only 4 texture units and 8 Z compare units. Contrast this to the X1300 and its 4 pixel pipes, 4 texture units and 4 Z compare units and the "16 of everything" X1800 and we can see that the architecture is quite flexible on every level.








103 Comments
View All Comments
Wellsoul2 - Wednesday, October 5, 2005 - link
I really prefer ATI so this is a disappointment.The 1300 and 1600 are pretty weak.
Might as well keep my 9600XT versus the 1300 - Can still play HL2 with noAA/AF.
The only good thing is maybe the price will drop on the x800/850 line.
The X1800 seems like a good card but why pay that money.
Why bother with the shared memory cards? It's dumb.
Cookie Crusher - Wednesday, October 5, 2005 - link
grammar is actually spelled with an "a" ;)OvErHeAtInG - Wednesday, October 5, 2005 - link
Yes, I have a feeling it'll be one of those cases where they make some editions and fixes to the article. Not that horrible, come on - I do agree the graphs are confusing. More important than graphs of benches, though, for me is the examination of the new AA, the architecture, features etc. Which they did a fair job ofOne remark: the bulleted lists are missing the bullets ... e.g. on page 2 the list of new features.
bldckstark - Wednesday, October 5, 2005 - link
Yes, this is the worst article I have ever seen posted on Anandtech. Will Anandtech continue to be my first stop on my daily hardware fix? Yes. Will I ever make Toms Hardware my first stop again? No. JEEEEZ toms sucks now. If you want to complain about a site as a whole take a look at them. They actually posted articles about how to pick up chicks while gaming! Multiple articles! Good Lord.Houdani - Wednesday, October 5, 2005 - link
Agreed! They did do a nice analysis of the new architecture.Agreed! Where are the bullets? (page 2 feature list, page 7 games list).
tfranzese - Wednesday, October 5, 2005 - link
Everyone's always surpised by this. Why? They've done this countless times now as if it's acceptable. Seriously, don't post an article until it's done and have it proofread carefully before posting it. I honestly doubt your (Anandtech) editors are doing more than just skimming articles sometimes with the number of typos and gramatical errors I come across.I hope the quality goes back up, because it will eventually hurt your reputation.
tfranzese - Wednesday, October 5, 2005 - link
I'll add, Anandtech is almost always my first stop to read a breaking review. Unfortunately, truths such as that below could someday change that. Today, Tech Report had the better article.Not their worst article, but things should be improving - not getting worse.
AnandThenMan - Wednesday, October 5, 2005 - link
I agree. VERY WEAK REVIEW! Terrible. Honestly, what happened? Anandtech is usually much, much more with it. Disappointed.As for the R520, I think I'm like most people and just feel, meh.
misterspoot - Wednesday, October 5, 2005 - link
Since the X1800 SKUs will not have the AGP bridge available (PCI-E) only, that leaves the X1600XT to attempt to give us AGP users a performance boost.Sadly, the X1600XT performs barely on par with a GeForce 6600GT -- which can be had for $150. Then, looking at the performance of the X1600XT, and comparing it to the X850 XT-PE -- surprise surprise, the year-plus old X850 XT is considerably superior.
So if you're like me and built your box nearly 2 years ago, and have no choice but to buy an AGP part, it looks like the X850 XT-PE is going to be the highest performance part you can buy. Looks like I'll be grabbing one this weekend, so my performance in raids on Molten Core is drastically improved (runs a 6600GT at 1600x900 with minimum detail settings -- suffers from mid 20fps all the time while trying to tank).
DRavisher - Wednesday, October 5, 2005 - link
The review states: "With its 512MB of onboard RAM, the X1800 XT scales especially well at high resolutions,". From what I see it scales very poorly at high resolutions compared to the 7800GTX 256MB card. Just look at what happens in SC:CT and FarCry. The XT goes from having a substantial lead in 1600x1200 to being about equal with the 7800GTX at 2048x1536.