AMD Zen 4 Ryzen 9 7950X and Ryzen 5 7600X Review: Retaking The High-End
by Ryan Smith & Gavin Bonshor on September 26, 2022 9:00 AM ESTSPEC2017 Single-Threaded Results
SPEC2017 is a series of standardized tests used to probe the overall performance between different systems, different architectures, different microarchitectures, and setups. The code has to be compiled, and then the results can be submitted to an online database for comparison. It covers a range of integer and floating point workloads, and can be very optimized for each CPU, so it is important to check how the benchmarks are being compiled and run.
We run the tests in a harness built through Windows Subsystem for Linux, developed by Andrei Frumusanu. WSL has some odd quirks, with one test not running due to a WSL fixed stack size, but for like-for-like testing it is good enough. Because our scores aren’t official submissions, as per SPEC guidelines we have to declare them as internal estimates on our part.
For compilers, we use LLVM both for C/C++ and Fortan tests, and for Fortran we’re using the Flang compiler. The rationale of using LLVM over GCC is better cross-platform comparisons to platforms that have only have LLVM support and future articles where we’ll investigate this aspect more. We’re not considering closed-sourced compilers such as MSVC or ICC.
clang version 10.0.0
clang version 7.0.1 (ssh://git@github.com/flang-compiler/flang-driver.git
24bd54da5c41af04838bbe7b68f830840d47fc03)
-Ofast -fomit-frame-pointer
-march=x86-64
-mtune=core-avx2
-mfma -mavx -mavx2
Our compiler flags are straightforward, with basic –Ofast and relevant ISA switches to allow for AVX2 instructions.
To note, the requirements for the SPEC licence state that any benchmark results from SPEC have to be labelled ‘estimated’ until they are verified on the SPEC website as a meaningful representation of the expected performance. This is most often done by the big companies and OEMs to showcase performance to customers, however is quite over the top for what we do as reviewers.
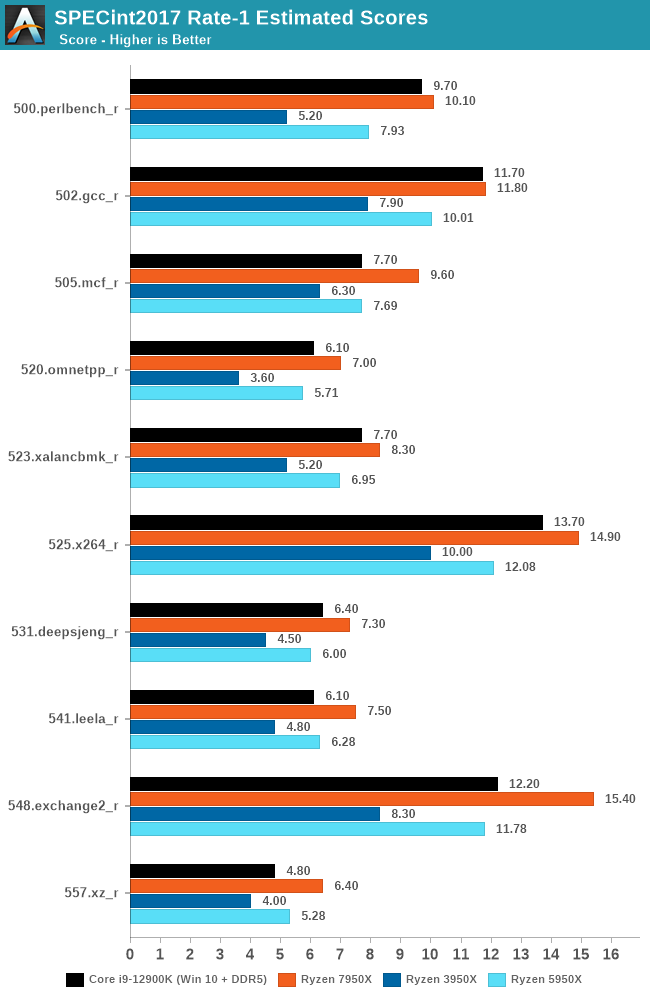
Starting off with single-threaded performance in SPECint2017, we can see that AMD's new Zen 4 core performs when compared directly with its previous Zen 3 and even more so, its Zen 2 microarchitecture. In 500.perlbench_r, the Ryzen 9 7950X has a 27% uplift over the previous Zen 3 based Ryzen 9 5950X, with a massive 94% uplift in single-threaded performance over the Zen 2 based Ryzen 9 3950X. This in itself is impressive, with similar levels of performance increase in other SPECint2017 tests such as a 23% increase over the previous generation in 525.x264_r and 30% in the 548.exchange2_r test.
The performance increase can be explained by a number of variables, including the switch from DDR4 to DDR5 memory, as well as a large increase in clock speed.
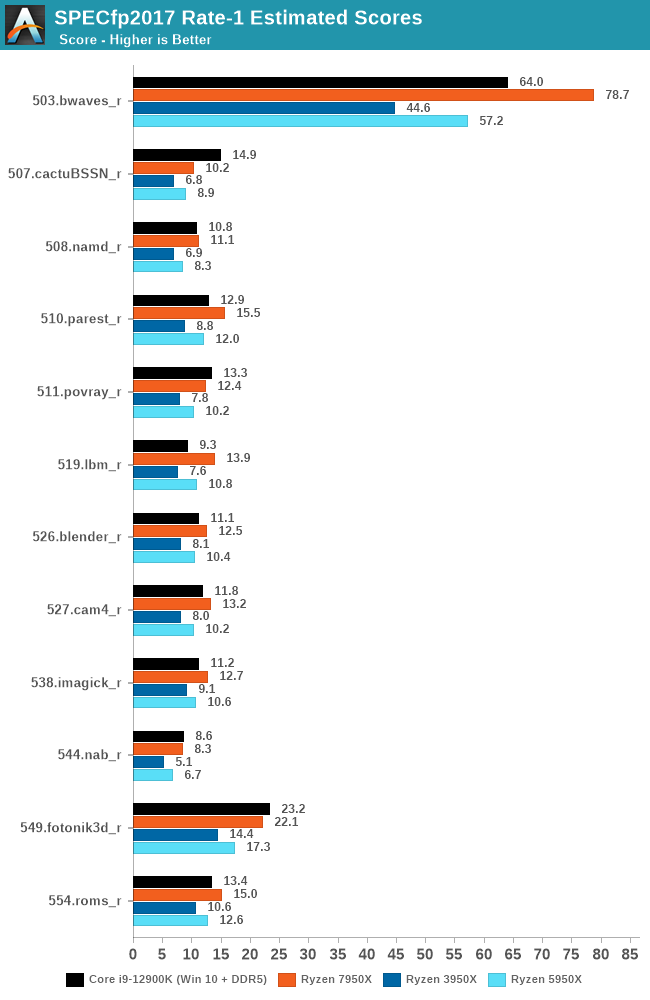
Moving onto our SPECfp2017 1T results, we see a similar increase in performance as in the previous set of 1T-tests. Focusing on the 503.bwaves_r, we are seeing an uplift of 37% over Zen 3. Interestingly, the performance in 549.fotonik3d, we see an increase of around 27% over the Ryzen 9 3950X, although Intel's Alder Lake architecture which is also on DDR5 is outperforming the Ryzen 9 7950X.
Perhaps the biggest increase in Zen 4's improvement in IPC over Zen 3 is through doubling the L2 cache on the 7950X (16MB) versus the 5950X (8MB). Similarly, both the Ryzen 9 7950X and 5950X have a large pool of L3 cache (64MB), but the 7950X boosts up to 5.7 GHz on a single core providing the core temperature is below 50°C, or 5.6 GHz if above 50°C.
As it stands at the time of writing, AMD's Ryzen 9 7950X is the clear leader in single-core IPC performance, with a pretty comprehensive increase in IPC performance over Zen 3. Although Intel's Alder Lake (12th Gen) provided gains over AMD's Ryzen 5000 series in a multitude of ways including frequency, optimizations, and its complex hybrid architecture. There is no doubt that the latest Zen 4 microarchitecture using TSMC's 5 nm node gives AMD the single-thread performance crown, and in terms of single-threaded applications, it's the most powerful x86 desktop processor right now.








205 Comments
View All Comments
linuxgeex - Monday, September 26, 2022 - link
All Microsoft customers are QA testers, lol. That's always how it's been. ReplyKangal - Tuesday, September 27, 2022 - link
Isn't that what goes for Linux?The only difference is that you don't pay money, you just pay in time, effort, frustration, and your soul.
Reply
Hifihedgehog - Tuesday, September 27, 2022 - link
Exactly. And you compile your own kernel for 24 hours hoping it will finish successfully. Replyat_clucks - Wednesday, October 19, 2022 - link
Not if you use the latest Ryzen 9 7950X. You may still pray it's successful at the end but God will answer a lot faster :). Replyelforeign - Monday, September 26, 2022 - link
Ah yes, the capitalistic adage of less is more. I'm sorry you guys have to deal with this, as with anyone in the workforce, where the powers that be sit on their ass with their cushy millions and say workers can do less with more and pile on with disregard.On a further note, I have been coming to Anandtech since the mid 00's. While I can understand the expectation surrounding good grammar and flawless articles, some issues are bound to come up now and then. The vitriol you guys receive for some simple grammar or syntax mistake is crazy. Reply
rarson - Wednesday, September 28, 2022 - link
"Ah yes, the capitalistic adage of less is more."This is not a thing. Reply
herozeros - Monday, September 26, 2022 - link
Kind reply, thanks. Hope your week lets you catch up.No more copy editors?! I guess my blonde is all now truly grey . . . sigh Reply
Threska - Monday, September 26, 2022 - link
Outsourced to AI. Replyemn13 - Monday, September 26, 2022 - link
I for one thoroughly enjoyed your article, and appreciate the technical content - a few editing nits don't detract from that.And hey, if I were to whine about embarrassing editing mistakes, rather than focusing on a long article written in limited time due to AMD's schedule, I'd poke fun at the 100 000 000 000 $ company's press slides touting their EXPO tech's openness in the form of public "doucments". 😀 Reply
linuxgeex - Monday, September 26, 2022 - link
So long as you're open to community feedback to correct hasty errors, there's no need for copy editors, and you can push your articles faster, which we'll all appreciate. Saying thanks is much more productive than making excuses. It shows that you appreciate your community. Reply