AMD Zen 4 Ryzen 9 7950X and Ryzen 5 7600X Review: Retaking The High-End
by Ryan Smith & Gavin Bonshor on September 26, 2022 9:00 AM ESTSPEC2017 Single-Threaded Results
SPEC2017 is a series of standardized tests used to probe the overall performance between different systems, different architectures, different microarchitectures, and setups. The code has to be compiled, and then the results can be submitted to an online database for comparison. It covers a range of integer and floating point workloads, and can be very optimized for each CPU, so it is important to check how the benchmarks are being compiled and run.
We run the tests in a harness built through Windows Subsystem for Linux, developed by Andrei Frumusanu. WSL has some odd quirks, with one test not running due to a WSL fixed stack size, but for like-for-like testing it is good enough. Because our scores aren’t official submissions, as per SPEC guidelines we have to declare them as internal estimates on our part.
For compilers, we use LLVM both for C/C++ and Fortan tests, and for Fortran we’re using the Flang compiler. The rationale of using LLVM over GCC is better cross-platform comparisons to platforms that have only have LLVM support and future articles where we’ll investigate this aspect more. We’re not considering closed-sourced compilers such as MSVC or ICC.
clang version 10.0.0
clang version 7.0.1 (ssh://git@github.com/flang-compiler/flang-driver.git
24bd54da5c41af04838bbe7b68f830840d47fc03)
-Ofast -fomit-frame-pointer
-march=x86-64
-mtune=core-avx2
-mfma -mavx -mavx2
Our compiler flags are straightforward, with basic –Ofast and relevant ISA switches to allow for AVX2 instructions.
To note, the requirements for the SPEC licence state that any benchmark results from SPEC have to be labelled ‘estimated’ until they are verified on the SPEC website as a meaningful representation of the expected performance. This is most often done by the big companies and OEMs to showcase performance to customers, however is quite over the top for what we do as reviewers.
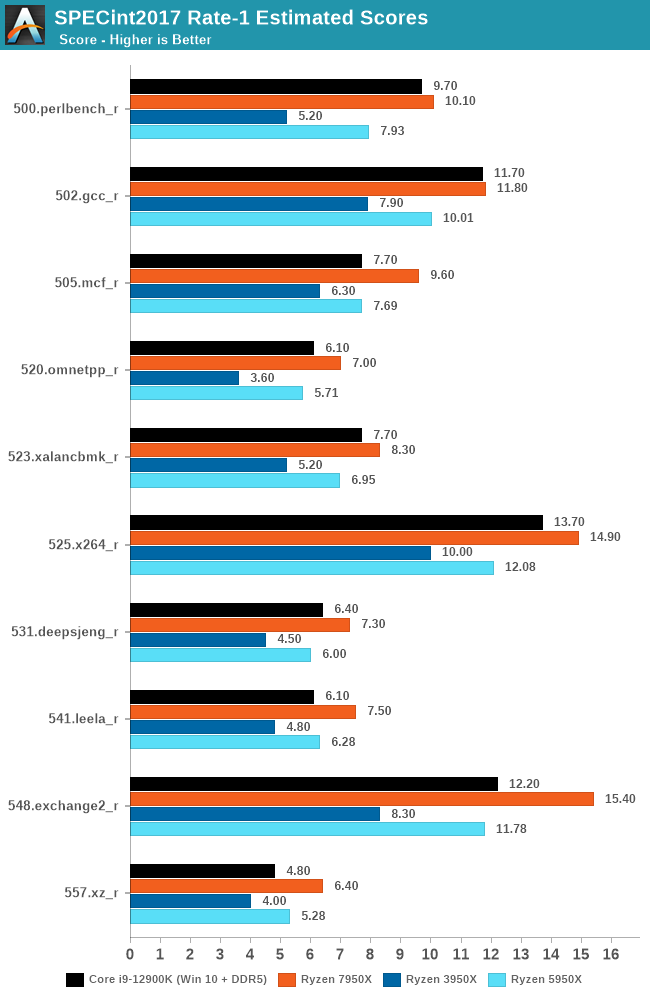
Starting off with single-threaded performance in SPECint2017, we can see that AMD's new Zen 4 core performs when compared directly with its previous Zen 3 and even more so, its Zen 2 microarchitecture. In 500.perlbench_r, the Ryzen 9 7950X has a 27% uplift over the previous Zen 3 based Ryzen 9 5950X, with a massive 94% uplift in single-threaded performance over the Zen 2 based Ryzen 9 3950X. This in itself is impressive, with similar levels of performance increase in other SPECint2017 tests such as a 23% increase over the previous generation in 525.x264_r and 30% in the 548.exchange2_r test.
The performance increase can be explained by a number of variables, including the switch from DDR4 to DDR5 memory, as well as a large increase in clock speed.
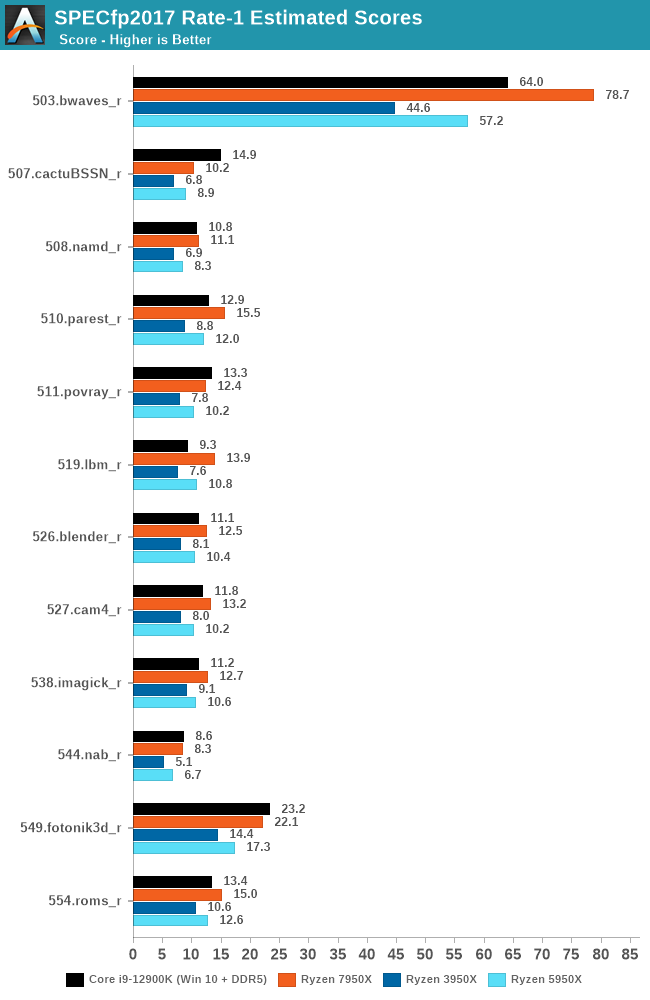
Moving onto our SPECfp2017 1T results, we see a similar increase in performance as in the previous set of 1T-tests. Focusing on the 503.bwaves_r, we are seeing an uplift of 37% over Zen 3. Interestingly, the performance in 549.fotonik3d, we see an increase of around 27% over the Ryzen 9 3950X, although Intel's Alder Lake architecture which is also on DDR5 is outperforming the Ryzen 9 7950X.
Perhaps the biggest increase in Zen 4's improvement in IPC over Zen 3 is through doubling the L2 cache on the 7950X (16MB) versus the 5950X (8MB). Similarly, both the Ryzen 9 7950X and 5950X have a large pool of L3 cache (64MB), but the 7950X boosts up to 5.7 GHz on a single core providing the core temperature is below 50°C, or 5.6 GHz if above 50°C.
As it stands at the time of writing, AMD's Ryzen 9 7950X is the clear leader in single-core IPC performance, with a pretty comprehensive increase in IPC performance over Zen 3. Although Intel's Alder Lake (12th Gen) provided gains over AMD's Ryzen 5000 series in a multitude of ways including frequency, optimizations, and its complex hybrid architecture. There is no doubt that the latest Zen 4 microarchitecture using TSMC's 5 nm node gives AMD the single-thread performance crown, and in terms of single-threaded applications, it's the most powerful x86 desktop processor right now.








205 Comments
View All Comments
Tomatotech - Friday, September 30, 2022 - link
Nice idea but you’re swimming against the flow of history. The trend is always to more tightly integrate various components into smaller and smaller packages. Apple have moved to onboard RAM in the same package as the CPU which has bought significant bandwidth advantages and seems to have boosted iGPU to the level of low-end dGPUs.The main takeaway from your metaphor of the 650w dGPU with a 55w mainboard and 100-200w CPU is that high-end dGPUs are now effectively separate computers in their own right - especially as a decent one can be well over 50% of the cost of the whole PC - and are being constrained by having to fit into the PC in terms of physical space, power supply capacity, and cooling capacity.
It’s a shrinking market on both the low end and high end for home use of dGPU, given these innovations and constraints and I don’t know where it’s going to go from here.
Since I got optic fibre, I’ve started renting cloud based high-end dGPU and it has been amazing albeit the software interface has been frustrating at times. With symmetric gigabit service and 1-3ms ping, it’s like having it under my desk. I worked out that for unlimited hours and given the cost of electricity, it would take 10 years for my cloud rental costs to match the cost of buying and running a home high end dGPU.
Not everyone has optic fibre of course but globally it’s rolling out year by year so the trend is clear again. Reply
Castillan - Wednesday, September 28, 2022 - link
"clang version 10.0.0
clang version 7.0.1 (ssh://git@github.com/flang-compiler/flang-driver.git
24bd54da5c41af04838bbe7b68f830840d47fc03)
-Ofast -fomit-frame-pointer
-march=x86-64
-mtune=core-avx2
-mfma -mavx -mavx2
"
...and then later the article says:
"The performance increase can be explained by a number of variables, including the switch from DDR4 to DDR5 memory, a large increase in clock speed, as well as the inclusion of the AVX-512 instruction set, albeit using two 256-bit pumps."
The problem here being that those arguments to Clang will NOT enable AVX-512. Only AVX2 will be enabled. I verified this on an AVX512 system.
To enable AVX512, at least at the most basic level, you'll want to use "-mavx512f ". There's also a whole stack of other AVX512 capabilities, which are enabled with "-mavx512dq -mavx512bw -mavx512vbmi -mavx512vbmi2 -mavx512vl" but some may not be supported. It won't hurt to include those on the command line though, until you try to compile something that makes use of those specific features, and then you'll see a failure if the platform doesn't support those extensions. Reply
Ryan Smith - Friday, September 30, 2022 - link
Correct. AVX-512 is not in play here. That is an error in analysis on our part. Thanks! Replypman6 - Thursday, September 29, 2022 - link
intel supports 8k60 AV1 decode.Does ryzen 7000 support 8k60 ?? Reply
GeoffreyA - Monday, October 3, 2022 - link
The Radeon Technology Group is getting 16K ready. Replyyhselp - Thursday, September 29, 2022 - link
I'd love to see you investigate memory scaling on the Zen 4 core. ReplyMyrandex - Thursday, September 29, 2022 - link
The table on page four mentions "Quad Channel (128-bit bus)" for memory support. Does that mean we could have a 4 memory slot solution, with one memory module per channel, with four channel support? This way to drastically increase memory bandwidth all while maintaining those fast DDR5 frequencies? ReplyRyan Smith - Friday, September 30, 2022 - link
No. That configuration would be no different than a 2 DIMM setup in terms of bandwidth or capacity. Slotted memory is all configured DIMMs; as in Dual Inline Memory Module. ReplyGeoffreyA - Friday, September 30, 2022 - link
All in all, excellent work, AMD, on the 7950X. Undoubtedly shocking performance. Even that dubious AVX-512 benchmark where Intel used to win, Zen 4 has taken command of it. However, lower your prices, AMD, and don't be so greedy. Little by little, you are becoming Intel. Don't be evil.Thanks, Ryan and Gavin, for the review and all the hard work. Much appreciated. Have a great week. Reply
Footman36 - Friday, September 30, 2022 - link
Yawn. I really don't see what the big fuss is about. I currently run 5600X and was interested to see how the 7600X compared and while it does look like a true uplift in performance over the 5600X, I would have to factor in cost of new motherboard and DDR5 ram! On top of that, the comparison is not exactly apples to apples in the testing. 7600X has a turbo speed of 5.3, 5600X 4.6. 7600X runs with 5200 DDR5 and 5600X 3200 DDR4, 7600X has TDP 105W, 5600X 65W. If you take a look at the final page where the 7950X is tested in ECO mode which effectively supplies 65W instead of 105W you lose 18% performance. If we try to do apples to apples and use eco mode with 7600X, to get apples to apples with 65W of 5600W, then lower boost to 4.6ghz then the performance of the 2 cpu's looks very similar. Perhaps not the way I should be analyzing the results, but just my observation.... Reply