AMD Zen 4 Ryzen 9 7950X and Ryzen 5 7600X Review: Retaking The High-End
by Ryan Smith & Gavin Bonshor on September 26, 2022 9:00 AM ESTSPEC2017 Single-Threaded Results
SPEC2017 is a series of standardized tests used to probe the overall performance between different systems, different architectures, different microarchitectures, and setups. The code has to be compiled, and then the results can be submitted to an online database for comparison. It covers a range of integer and floating point workloads, and can be very optimized for each CPU, so it is important to check how the benchmarks are being compiled and run.
We run the tests in a harness built through Windows Subsystem for Linux, developed by Andrei Frumusanu. WSL has some odd quirks, with one test not running due to a WSL fixed stack size, but for like-for-like testing it is good enough. Because our scores aren’t official submissions, as per SPEC guidelines we have to declare them as internal estimates on our part.
For compilers, we use LLVM both for C/C++ and Fortan tests, and for Fortran we’re using the Flang compiler. The rationale of using LLVM over GCC is better cross-platform comparisons to platforms that have only have LLVM support and future articles where we’ll investigate this aspect more. We’re not considering closed-sourced compilers such as MSVC or ICC.
clang version 10.0.0
clang version 7.0.1 (ssh://git@github.com/flang-compiler/flang-driver.git
24bd54da5c41af04838bbe7b68f830840d47fc03)
-Ofast -fomit-frame-pointer
-march=x86-64
-mtune=core-avx2
-mfma -mavx -mavx2
Our compiler flags are straightforward, with basic –Ofast and relevant ISA switches to allow for AVX2 instructions.
To note, the requirements for the SPEC licence state that any benchmark results from SPEC have to be labelled ‘estimated’ until they are verified on the SPEC website as a meaningful representation of the expected performance. This is most often done by the big companies and OEMs to showcase performance to customers, however is quite over the top for what we do as reviewers.
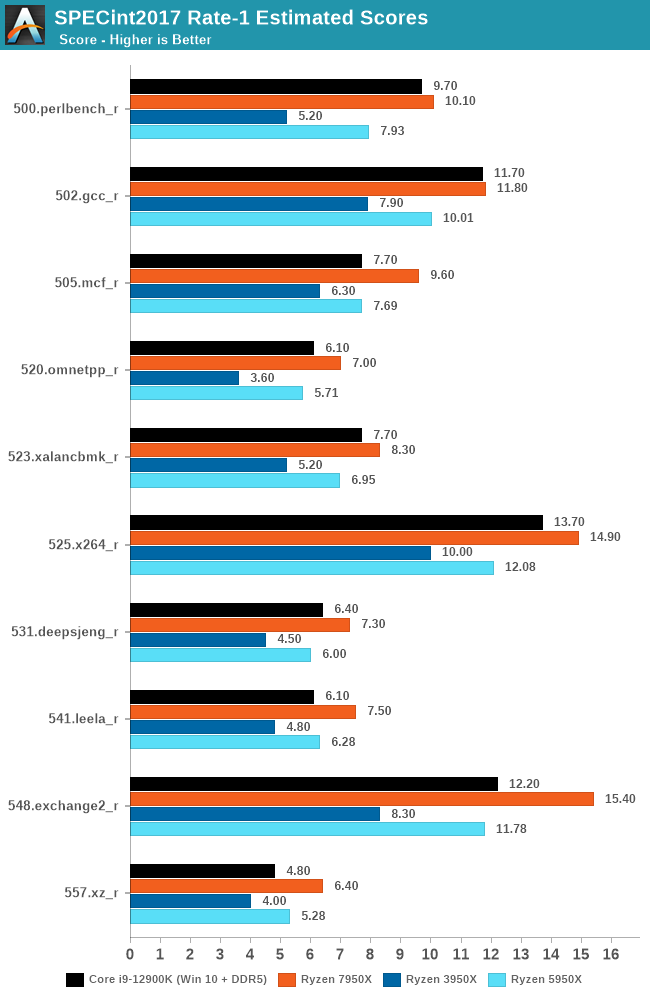
Starting off with single-threaded performance in SPECint2017, we can see that AMD's new Zen 4 core performs when compared directly with its previous Zen 3 and even more so, its Zen 2 microarchitecture. In 500.perlbench_r, the Ryzen 9 7950X has a 27% uplift over the previous Zen 3 based Ryzen 9 5950X, with a massive 94% uplift in single-threaded performance over the Zen 2 based Ryzen 9 3950X. This in itself is impressive, with similar levels of performance increase in other SPECint2017 tests such as a 23% increase over the previous generation in 525.x264_r and 30% in the 548.exchange2_r test.
The performance increase can be explained by a number of variables, including the switch from DDR4 to DDR5 memory, as well as a large increase in clock speed.
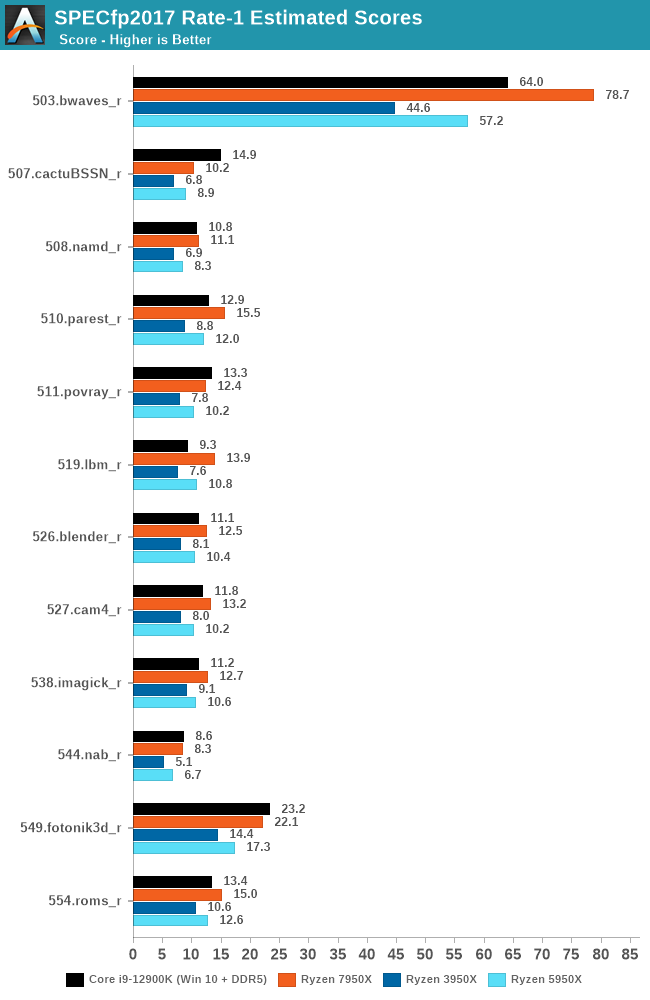
Moving onto our SPECfp2017 1T results, we see a similar increase in performance as in the previous set of 1T-tests. Focusing on the 503.bwaves_r, we are seeing an uplift of 37% over Zen 3. Interestingly, the performance in 549.fotonik3d, we see an increase of around 27% over the Ryzen 9 3950X, although Intel's Alder Lake architecture which is also on DDR5 is outperforming the Ryzen 9 7950X.
Perhaps the biggest increase in Zen 4's improvement in IPC over Zen 3 is through doubling the L2 cache on the 7950X (16MB) versus the 5950X (8MB). Similarly, both the Ryzen 9 7950X and 5950X have a large pool of L3 cache (64MB), but the 7950X boosts up to 5.7 GHz on a single core providing the core temperature is below 50°C, or 5.6 GHz if above 50°C.
As it stands at the time of writing, AMD's Ryzen 9 7950X is the clear leader in single-core IPC performance, with a pretty comprehensive increase in IPC performance over Zen 3. Although Intel's Alder Lake (12th Gen) provided gains over AMD's Ryzen 5000 series in a multitude of ways including frequency, optimizations, and its complex hybrid architecture. There is no doubt that the latest Zen 4 microarchitecture using TSMC's 5 nm node gives AMD the single-thread performance crown, and in terms of single-threaded applications, it's the most powerful x86 desktop processor right now.








205 Comments
View All Comments
Oxford Guy - Tuesday, September 27, 2022 - link
This has been posted for years. ReplyBoredInPDX - Tuesday, September 27, 2022 - link
I’m confused. I they 720p tests you write:“All gaming tests here were run using integrated graphics, with a variation of 720p resolutions and at minimum settings.”
Yet all the prior-gen AMD CPUs tested are lacking an IGP. Am I missing something? Reply
Ryan Smith - Friday, September 30, 2022 - link
You are not missing anything; we did not run any iGPU tests. That's a bit of boilerplate text that did not get scrubbed from this article. Thanks for bringing it up! ReplyGigaplex - Wednesday, September 28, 2022 - link
There's some odd results here and the article commentary doesn't seem to touch on it. Why is the 7600X absolutely trounced in Geekbench 4.0 MT? The second slowest CPU (3600XT) more than doubles it. And yet the 7950X wins by a mile in that same test, so it shouldn't be architectural. And in some of the gaming tests, the 7600X wins, and in some it comes dead last. ReplyDribble - Wednesday, September 28, 2022 - link
The processors are particularly cache bound - i.e. it fits in cache it runs very fast, if it doesn't it falls off rapidly. That is often visible in games where it'll run amazingly in some (mostly older) games, but tend to fall off, particularly in the lows, in more complex (mostly newer) games. Replyricebunny - Wednesday, September 28, 2022 - link
The SPEC multithreaded tests are N separate instantiations of the single thread tests. That’s a perfect scenario where there is no dependency or serialization in the workload and tells us very little how the CPUs would perform in a parallel workload application. There are SPEC tests specifically designed to test parallel performance, but I do not see them included in this report. Anandtech, can you comment on this? Replyabufrejoval - Wednesday, September 28, 2022 - link
Emerging dGPUs not supporting PCIe 5.0 is just crippleware!While I can easily see that 16 lanes of PCIe 5.0 won't do much for any game, I can very much see what I'd do with the 8 lanes left over when all dGPU bandwidth requirements can be met with just 8 lanes of PCIe 5.0.
Why can't they just be good PCIe citizens and negotiate to use 16 lanes of PCIe 4.0 on lesser or previous generation boards and optimize lane allocation on higher end PCIe 5.0 systems that can then use bifurcation to add say a 100Gbit NIC, plenty of Thunderbolt 4 or better yet, something CXL?
Actually I'd be really astonished if this wasn't even an artifical cap and that the Nvidia chips may actually be able to do PCIe 5.0.
It's just that they'd much rather have people use NVlink. Reply
TheinsanegamerN - Tuesday, October 4, 2022 - link
Um....dude, 4.0x16 and 5.0x8 have the same bandwidth, and no GPU today can saturate 4.0, not even close. The 300ti OCed manages to saturate.....2.0. 3.0 is a whopping 7% faster.You got awhile man. Reply
abufrejoval - Wednesday, September 28, 2022 - link
It should be interesting to see if AMD is opening the architecture for 3rd parties to exploit the actual potential of the Ryzen 7000 chips.The current mainboard/slot era that dates back to the 1981 IBM-PC (or the Apple ][) really is coming to an end and perhaps few things highlight this as well as a 600 Watt GPU that has a 65 Watt mainboard hanging under it.
We may really need something more S100 or VME, for those old enough to understand that.
Thunderbolt cables handle 4 lanes of PCIe 3.0 today and AFAIK cables are used for much higher lane counts and PCIe revisions within high-end server chassis today, even if perhaps at shorter lengths and with connectors designed for somewhat less (especially less frequent) pluggability.
Their main advantage is vastly reduced issues with mainboard traces and much better use of 3D space to optimize air flow cooling.
Sure those cables aren't cheap, but perhaps the cross-over point for additional PCB layers has been passed. And optical interconnects are waiting in the wings: they will use cables, too.
You stick PCIe 5.0 x4 fixed length cables out from all sides of an AM5 socket and connect those either to high bandwidth devices (e.g. dGPU) or a switch (PCIe 5.0 variant of the current ASMedia), you get tons of flexibility and expandability in a box form factor, that may not resemble an age old PC very much, but deliver tons of performance and expandability in a deskside form factor.
You want to recycle all your nice PCIe 3.0 2TB NVMe drives? Just add a board that puts a PCIe 5.0 20 lane switch between (even PCIe 4.0 might do fine if it's 50% $$$).
And if your dGPU actually needs 8 lanes of PCIe 5.0 to deliver top performance, connect two of those x4 cables to undo a bit of bifurcation!
How those cable connected board would then mount in a chassis and be cooled across a large range of form factors and power ranges is up for lots of great engineers to solve, while dense servers may already provide lots of the design bricks.
Unfortunately all that would require AMD to open up the base initialization code and large parts of the BIOS, which I guess currently has the ASmedia chip(s) pretty much hardwired into it.
And AMD with all their "we don't do artificial market segmentation" publicity in the past, seem to have become far more receptive to its bottom line benefits recently, to allow a free transition from console to PC/workstation and servers of all sizes.
And it would take a high-volume vendor (or AMD itself), a client side Open Compute project or similar to push that form factor the the scale where it becomes economically viable.
It's high time for a PC 2.0 (which isn't a PS/2) to bridge into the CXL universe even on desktops and workstations. Reply
Oxford Guy - Wednesday, September 28, 2022 - link
"The current mainboard/slot era that dates back to the 1981 IBM-PC (or the Apple ][)"Absolutely nothing about the IBM PC was new. The Micral N introduced slots in a microcomputer and the S-100 bus, introduced by the Altair, became the first big standard. Reply