AMD's Ryzen 9 6900HS Rembrandt Benchmarked: Zen3+ Power and Performance Scaling
by Dr. Ian Cutress on March 1, 2022 9:30 AM ESTCPU Tests: SPEC Performance
SPEC2017 is a series of standardized tests used to probe the overall performance between different systems, different architectures, different microarchitectures, and setups. The code has to be compiled, and then the results can be submitted to an online database for comparison. It covers a range of integer and floating point workloads, and can be very optimized for each CPU, so it is important to check how the benchmarks are being compiled and run.
For compilers, we use LLVM both for C/C++ and Fortran tests, and for Fortran we’re using the Flang compiler. The rationale of using LLVM over GCC is better cross-platform comparisons to platforms that have only have LLVM support and future articles where we’ll investigate this aspect more. We’re not considering closed-sourced compilers such as MSVC or ICC.
clang version 10.0.0
clang version 7.0.1 (ssh://git@github.com/flang-compiler/flang-driver.git
24bd54da5c41af04838bbe7b68f830840d47fc03)-Ofast -fomit-frame-pointer
-march=x86-64
-mtune=core-avx2
-mfma -mavx -mavx2
Our compiler flags are straightforward, with basic –Ofast and relevant ISA switches to allow for AVX2 instructions. We decided to build our SPEC binaries on AVX2, which puts a limit on Haswell as how old we can go before the testing will fall over. This also means we don’t have AVX512 binaries, primarily because in order to get the best performance, the AVX-512 intrinsic should be packed by a proper expert, as with our AVX-512 benchmark. All of the major vendors, AMD, Intel, and Arm, all support the way in which we are testing SPEC.
To note, the requirements for the SPEC licence state that any benchmark results from SPEC have to be labeled ‘estimated’ until they are verified on the SPEC website as a meaningful representation of the expected performance. This is most often done by the big companies and OEMs to showcase performance to customers, however is quite over the top for what we do as reviewers.
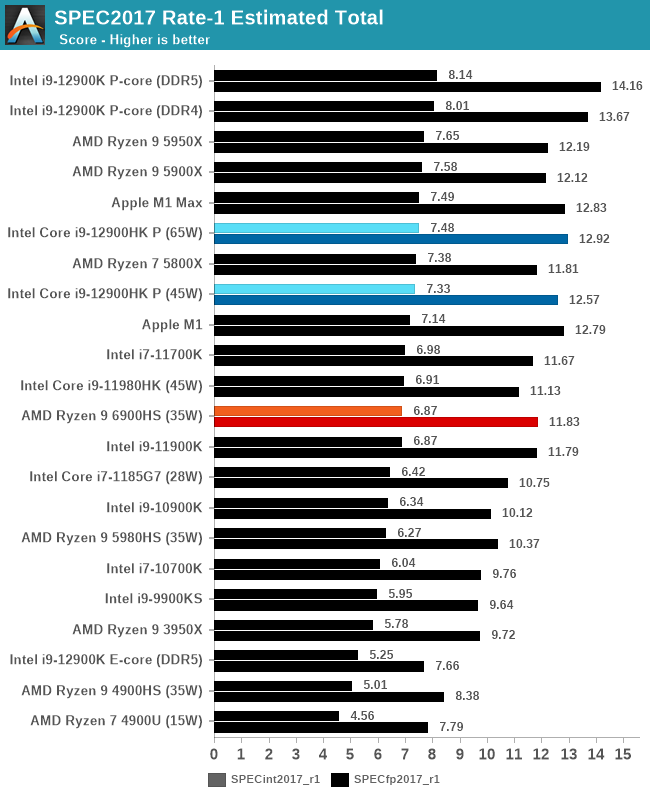
In the single threaded test, the jump over the regular Zen 3 Ryzen mobile variant (5980HS) at the same power is quite substantial: +9.6% on integer performance and +14.1% on floating point. The move from DDR4 to DDR5 is quite substantial in that regard, and it’s seen in a lot of our upcoming benchmarks.
We didn’t see any change from 35 W to 45 W to 65 W in our AMD testing as the power consumption of the chip in single threaded workloads did not exceed 24 W, however we did see performance difference in Intel’s Alder Lake going from 45 W to 65 W, showcasing how much power the core can consume.
But if we compared that to Intel’s latest Alder Lake offerings, there’s a deficit in both categories – even though our lowest data here is at 45 W, we can see that the 45 W testing of the previous generation Intel also beats the 6900HS at SPECint (but AMD wins in SPECfp). This is something that carries through to multi-threaded performance.
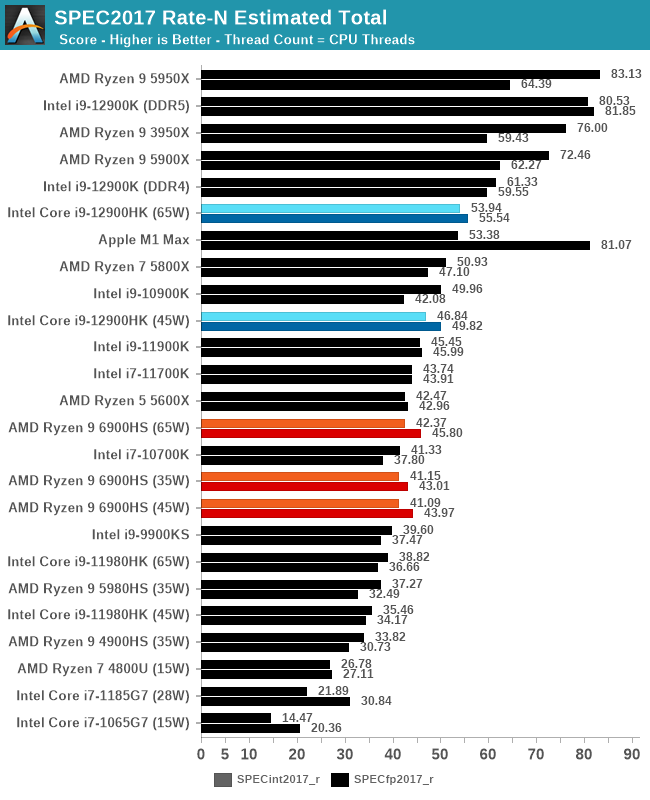
For Multi-Threaded performance, we only saw the slightest improvement from AMD moving up to 65 W, perhaps showcasing that the hardware is limited in other ways than just power and the uplift from DDR4 to DDR5. In any event, at 35 W, AMD still surpasses what the previous generation Intel i9-11980HK can provide at 65 W.
But if we compare it to Intel’s latest Alder Lake processors, featuring 6 performance cores and 8 efficiency cores, we now have 20 threads up against AMD’s 16 threads. If we compare 45 W to 45 W, Intel has a +14.0% lead in integer and a +13.3% lead in floating point, despite the 20% increase in threads. With Intel introducing this dual tier performance with hybrid SoCs, multi-threaded performance is going to be a combination of fast+slow and it all comes down to how the system can divide up the work.








92 Comments
View All Comments
Kangal - Sunday, March 6, 2022 - link
Zeno, Guards of Zeno, Grand Priest, Whis/Angels, Awakened Gass, Ultra Granolah, Ultra Instinct Goku, Beerus/GoDs, Fused Zamasu, Prime Moro, Raged Broly, Ultra Ego Vegeta, Full-power Jiren, LSS Kefla, Destruction Toppo, Max Hit, Anilaza, SSJ Rose Black, Golden Frieza, Dyspo, LSS Kale, Spirit Future Trunks, Super Ribrianne, Trained #17, Ultimate Gohan, Buu, Seven-Three.GeoffreyA - Monday, March 7, 2022 - link
Astonishing, and thanks for that! Remembering only Buu, Ultimate Gohan, and a bit of Beerus, I am really out of touch with DB canon!Kangal - Tuesday, March 8, 2022 - link
You can find the new series Dragon Ball Super online or even youtube. There is also the official manga which you can read for free* here:https://www.viz.com/shonenjump/chapters/dragon-bal...
*only the latest three issues available, new issues always free.
GeoffreyA - Tuesday, March 8, 2022 - link
Thanks, I only saw the first 10-15 episodes of Super in 2018, where Beerus came to the cruiseship, and still hope to watch the rest of it, eventually. It was nostalgic, I remember, seeing these dear characters after so long.mode_13h - Wednesday, March 9, 2022 - link
Eh, I only watched the original series. The few things after it that I had seen lacked the same charm. And among that series, the first season was one of the best. The censors had clearly cracked down on it, after that.What I thought worked so well about the original DB was Goku's innocence, ignorance, indomitable spirit, and purity of heart. That made it so much more entertaining and gratifying to see him overcome all the obstacles and enemies he encountered. And it's almost as if not knowing his own limitations made him unrestrained by them.
GeoffreyA - Thursday, March 10, 2022 - link
That's an exact description of Goku's character and is likely the secret of his greatness and why he often prevailed over his enemies. I would add that forgiveness was another trait of his, and something they could never understand. It's almost paradoxical, at least in DBZ, how he was the comic clumsy figure, and yet when it came to saving the world, only he could do it. Without knowing it, people are emulating, I feel, more of Vegeta's cynical character today. What the world needs is more of Goku.mode_13h - Friday, March 11, 2022 - link
I haven't watched much since the mid 2000's, but I thought Luffy, in One Piece, had a similar personality. However, he seemed to have a mercurial wisdom and canniness, just beneath the surface. In that regard, he seemed to have echos of Irresponsible Captain Taylor.I don't remember too much of Naruto, though I had started watching it from the beginning. Like Goku, he also had an innocence and indomitably, but there was obviously a darkness about him and inside of him.
I wouldn't have patience for any of that, now. Even at the time, it seemed rather excessively drawn out.
BTW, did you see the live action DB movie? I think it was made around 2008? More of a Hollywood movie; not Japanese. I'm apparently among the small minority who actually liked it. It helps to remember that Dragon Ball itself is loosely based on the ancient tale of Saiyuki and just don't expect a direct translation from the TV series or manga. It's very much a reinterpretation, but I enjoyed it.
GeoffreyA - Monday, March 14, 2022 - link
Luffy is very like Goku, regarding his innocence, simplicity, and goodness, but yes, he had another element which is hard to pin down. Perhaps a certain stoic quality that clicked on at times, and made him something fearful to all those who practised evil. (It's even evident when they left the Merry; Goku would never have operated like that, and for my part, I agree with Usopp.) I really loved One Piece. It could often be tedious and silly, but once the story knocked into gear, it was usually astonishing, and gave you the feeling of being on an adventure with noble companions. Namaka. My favourite arcs were Arlong/Nami, Arabasta, and Water 7. In 2018, I got stuck at Thriller Bark and never went on.What caused me to stop was seeing Evangelion for the first time that year. It left me a sadder, more sober person for ever; and I'll add a word of warning to others, Eva is terribly depressing and no joke. That and Steins;Gate are my favourite anime. I've heard great things about Naruto but to this day have not seen a single episode. Rurouni Kenshin was nice.
My brother really enjoyed the live-action Dragon Ball, but though I've seen only bits and pieces, I always debate with him that it's not the real DB! He contends that it's pretty good. Well, perhaps I need to sit down and actually watch it and give it a proper appraisal.
mode_13h - Tuesday, March 15, 2022 - link
Wow, all those One Piece names are definitely a flashback. I hung out with some Kenshin fans, so I saw the entire original series.Evangelion was pretty mind-blowing for me, when the original series first aired. A bit confusing, especially with the movies, the revisionist ending, and whatnot.
More recently, I went to a marathon showing of the original series, back when they started releasing the new version. I watched the first 2-3 installments of the new version and just quit. It got too absurd for me. I never liked the direction Gainax took with FLCL, but I guess it was inevitable the new Eva would go there (and lose me). I did really like Kare Kano and Chobits (lol, they seemed to have HDDs inside!).
I got a lot from Evangelion, but I'm pretty much over it. Not unlike how I parted ways with the Star Wars franchise, more than a decade ago. I just don't need it. I don't seem to have trouble finding enough to watch. For instance, a movie I recently enjoyed was Arrival.
Even the news is like a high-tension drama, for at least the past half decade. I can really feel like I'm living through history. It gives me a new perspective on much of the past century and what it was probably like, at the time.
Some other old anime that's fun to re-watch are the original Patlabor OAV series and movies, Akira, and the Ghost in the Shell series and movies. And every time I hear about space junk in the news, my mind goes back to Planetes.
GeoffreyA - Tuesday, March 15, 2022 - link
Evangelion is indeed out of this world. It's really the sadness of the characters that touched me, though of course the relentless, minimal action was impressive when it came. Can anyone ever forget Eva-01 breaking out of the shadow space in episode 16, or the time, nearing the end, when it reactivates though its power is gone? The new movies' weakness is that they tried to spin everything out to excessive detail, whereas the series' strength was minimalism. The characterisation, too, was subtly altered. Anyhow, last year I watched the final film, Thrice upon a Time, and can honestly say they did a good job and ended Eva on a surprisingly cheerful note, with a good message. I secretly hope for a return someday.I haven't seen most of the anime you mentioned, except for Akira and Ghost in the Shell. Suffice to say, Akira leaves the viewer speechless.
Same here. Lost my interest in Star Wars and don't care to see it again. Arrival was great, with a good performance by Amy Adams. And talking of Villeneuve movies, the new Dune was a big disappointment to me.