The Intel 12th Gen Core i9-12900K Review: Hybrid Performance Brings Hybrid Complexity
by Dr. Ian Cutress & Andrei Frumusanu on November 4, 2021 9:00 AM ESTPower: P-Core vs E-Core, Win10 vs Win11
For Alder Lake, Intel brings two new things into the mix when we start talking about power.
First is what we’ve already talked about, the new P-core and E-core, each with different levels of performance per watt and targeted at different sorts of workloads. While the P-cores are expected to mimic previous generations of Intel processors, the E-cores should offer an interesting look into how low power operation might work on these systems and in future mobile systems.
The second element is how Intel is describing power. Rather than simply quote a ‘TDP’, or Thermal Design Power, Intel has decided (with much rejoicing) to start putting two numbers next to each processor, one for the base processor power and one for maximum turbo processor power, which we’ll call Base and Turbo. The idea is that the Base power mimics the TDP value we had before – it’s the power at which the all-core base frequency is guaranteed to. The Turbo power indicates the highest power level that should be observed in normal power virus (usually defined as something causing 90-95% of the CPU to continually switch) situation. There is usually a weighted time factor that limits how long a processor can remain in its Turbo state for slowly reeling back, but for the K processors Intel has made that time factor effectively infinite – with the right cooling, these processors should be able to use their Turbo power all day, all week, and all year.
So with that in mind, let’s start simply looking at the individual P-cores and E-cores.
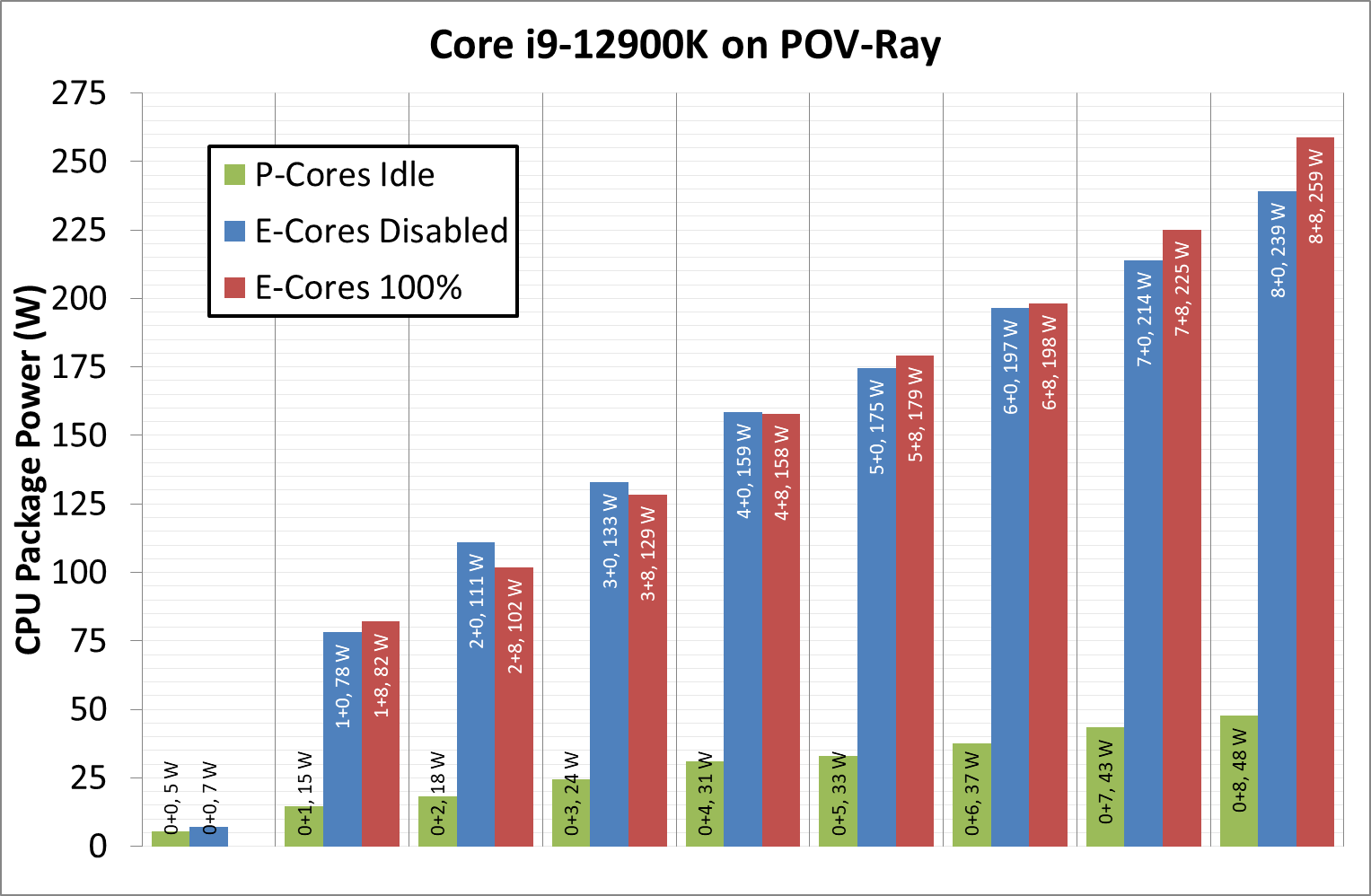
Listed in red, in this test, all 8P+8E cores fully loaded (on DDR5), we get a CPU package power of 259 W. The progression from idle to load is steady, although there is a big jump from idle to single core. When one core is loaded, we go from 7 W to 78 W, which is a big 71 W jump. Because this is package power (the output for core power had some issues), this does include firing up the ring, the L3 cache, and the DRAM controller, but even if that makes 20% of the difference, we’re still looking at ~55-60 W enabled for a single core. By comparison, for our single thread SPEC power testing on Linux, we see a more modest 25-30W per core, which we put down to POV-Ray’s instruction density.
By contrast, in green, the E-cores only jump from 5 W to 15 W when a single core is active, and that is the same number as we see on SPEC power testing. Using all the E-cores, at 3.9 GHz, brings the package power up to 48 W total.
It is worth noting that there are differences between the blue bars (P-cores only) and the red bars (all cores, with E-cores loaded all the time), and that sometimes the blue bar consumes more power than the red bar. Our blue bar tests were done with E-cores disabled in the BIOS, which means that there might be more leeway in balancing a workload across a smaller number of cores, allowing for higher power. However as everything ramps up, the advantage swings the other way it seems. It’s a bit odd to see this behavior.
Moving on to individual testing, and here’s a look at a power trace of POV-Ray in Windows 11:
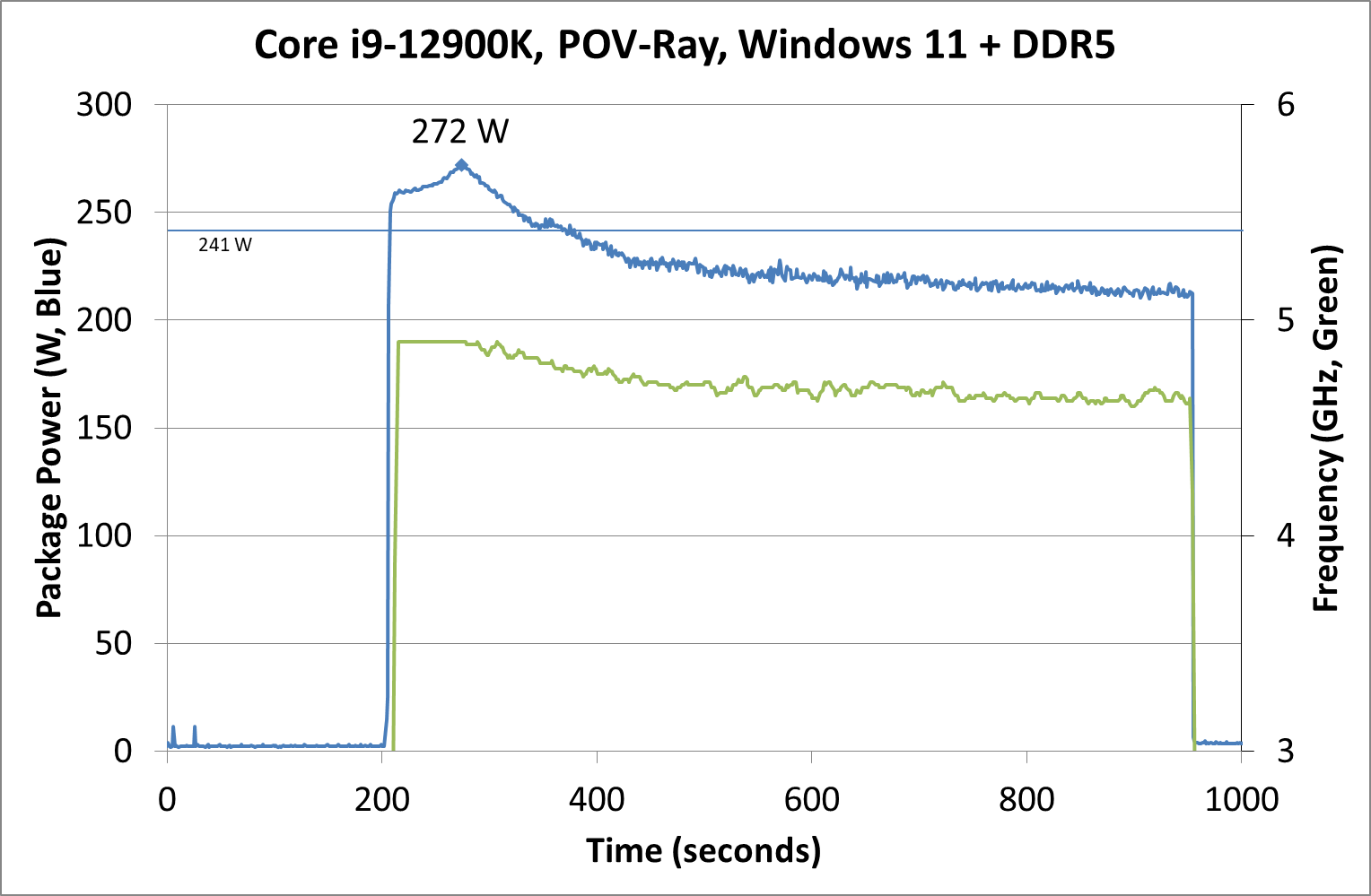
Here we’re seeing a higher spike in power, up to 272 W now, with the system at 4.9 GHz all-core. Interestingly enough, we see a decrease of power through the 241 W Turbo Power limit, and it settles around 225 W, with the reported frequency actually dropping to between 4.7-4.8 GHz instead. Technically this all-core is meant to take into account some of the E-cores, so this might be a case of the workload distributing itself and finding the best performance/power point when it comes to instruction mix, cache mix, and IO requirements. However, it takes a good 3-5 minutes to get there, if that’s the case.
Intrigued by this, I looked at how some of our other tests did between different operating systems. Enter Agisoft:
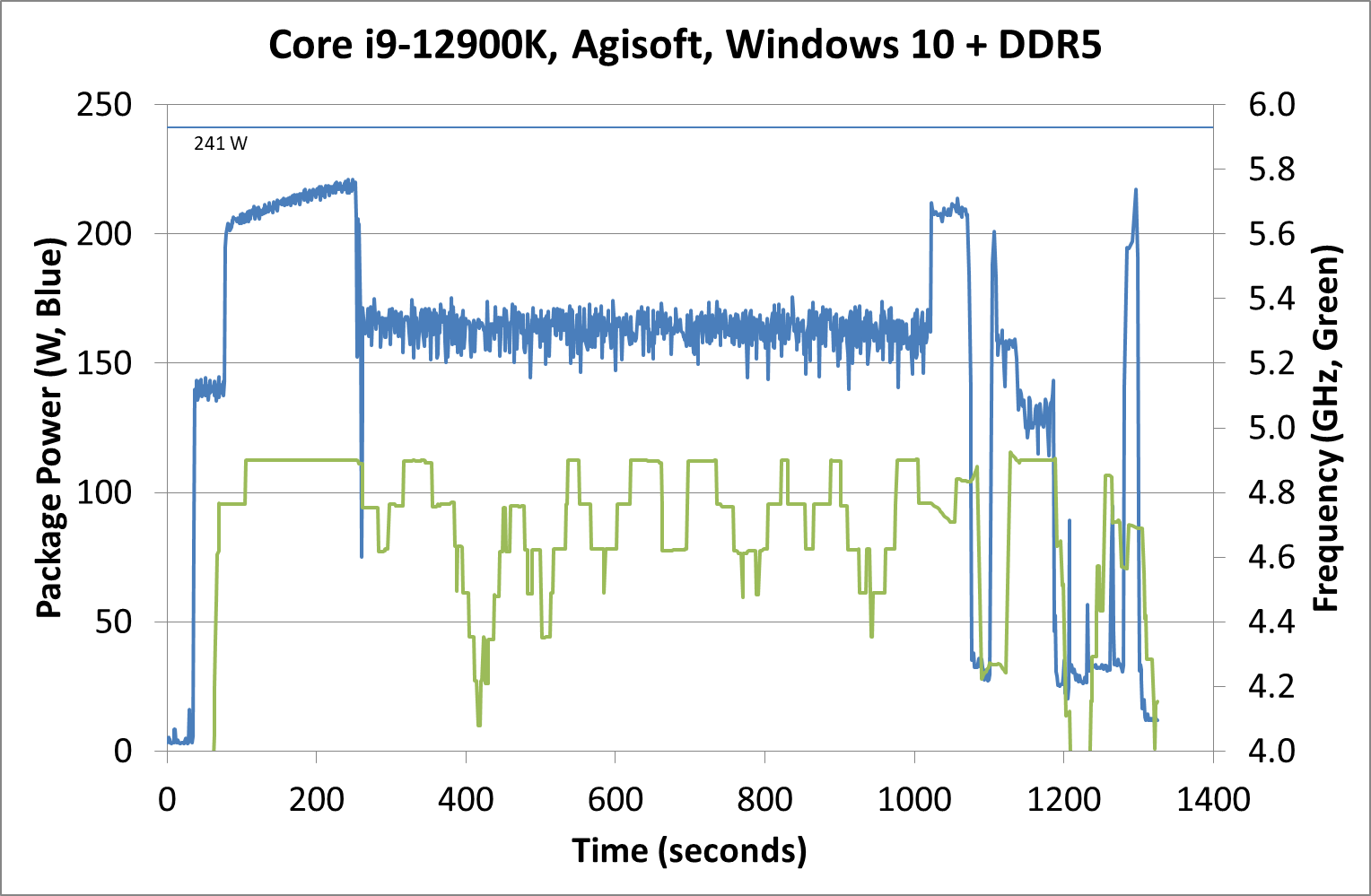
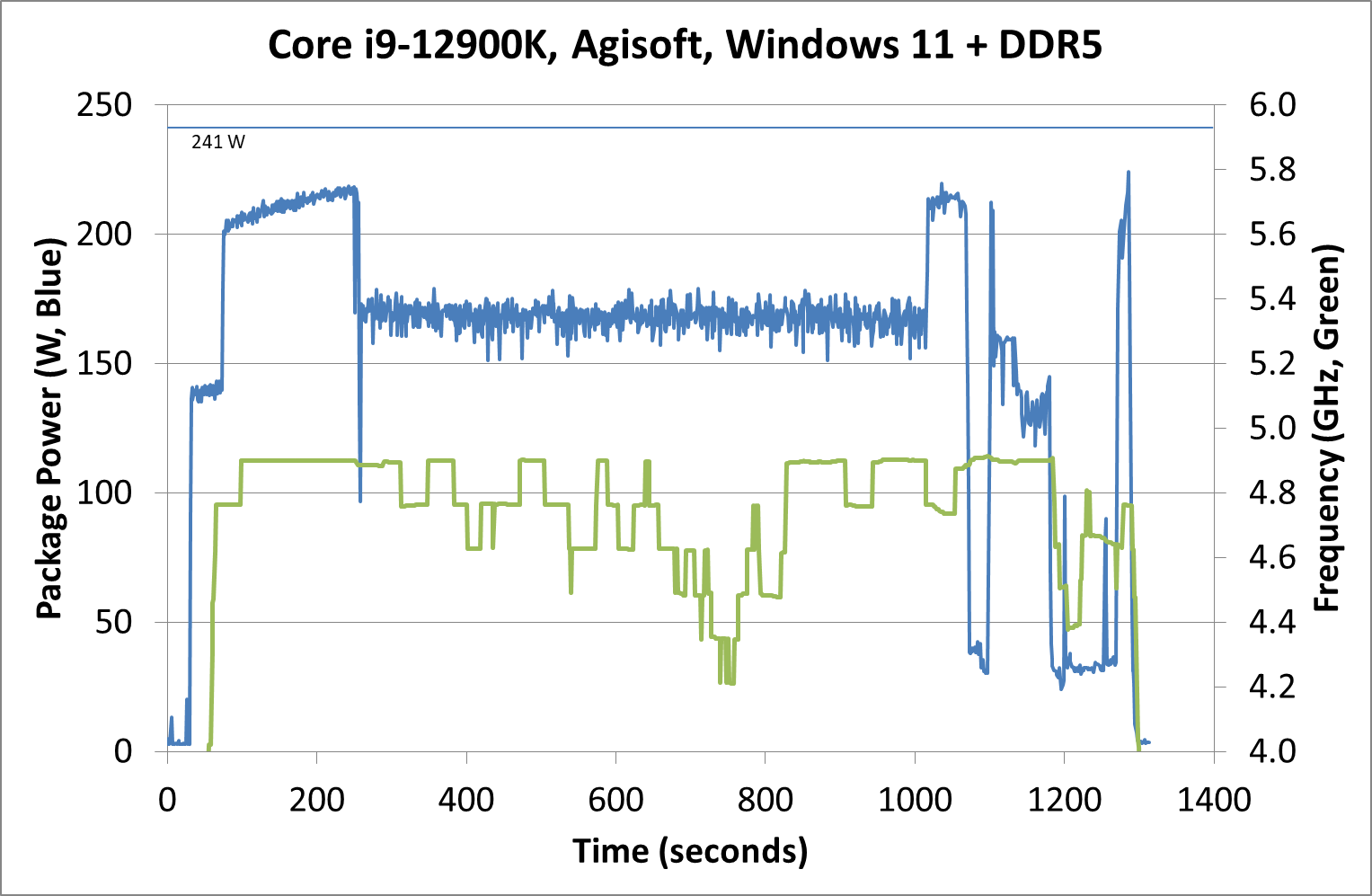
Between Windows 10 and Windows 11, the traces look near identical. The actual run time was 5 seconds faster on Windows 11 out of 20 minutes, so 0.4% faster, which we would consider run-to-run variation. The peaks and spikes look barely higher in Windows 11, and the frequency trace in Windows 11 looks a little more consistent, but overall they’re practically the same.
For our usual power graphs, we get something like this, and we’ll also add in the AVX-512 numbers from that page:
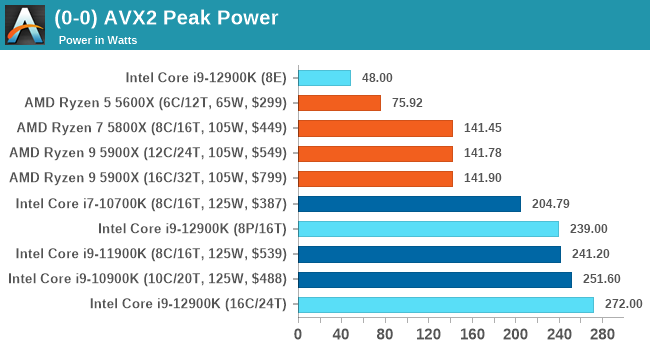
Compared to Intel’s previous 11th Generation Processor, the Alder Lake Core i9 uses more power during AVX2, but is actually lower in AVX-512. The difficulty of presenting this graph in the future is based on those E-cores; they're more efficient, and as you’ll see in the results later. Even on AVX-512, Alder Lake pulls out a performance lead using 50 W fewer than 11th Gen.
When we compare it to AMD however, with that 142 W PPT limit that AMD has, Intel is often trailing at a 20-70 W deficit when we’re looking at full load efficiency. That being said, Intel is likely going to argue that in mixed workloads, such as two software programs running where something is on the E-cores, it wants to be the more efficient design.








474 Comments
View All Comments
mode_13h - Tuesday, November 9, 2021 - link
Well, AMD does have V-Cache and Zen 3+ in the queue. But if you want to short them, be my guest!Sivar - Monday, November 8, 2021 - link
This is an amazingly deep, properly Anandtech review, even ignoring time constraints and the unusual difficulty of this particular launch.I bet Ian and Andrei will be catching up on sleep for weeks.
xhris4747 - Tuesday, November 9, 2021 - link
Hiricebunny - Tuesday, November 9, 2021 - link
It’s disappointing that Anandtech continues to use suboptimal compilers for their platforms. Intel’s Compiler classic demonstrated 41% better performance than Clang 12.0.0 in the SPECrate 2017 Floating Point suite.mode_13h - Wednesday, November 10, 2021 - link
I think it's fair, though. Most workloads people run aren't built with vendor-supplied compilers, they use industry standards of gcc, clang, or msvc. And the point of benchmarks it to give you an idea of what the typical user experience would be.ricebunny - Wednesday, November 10, 2021 - link
But are they not compiling the code for the M1 series chips with a vendor supplied compiler?Second, almost all benchmarks in SPECrate 2017 Floating Point are scientific codes, half of which are in Fortran. That’s exactly the target domain of the Intel compiler. I admit, I am out of date with the HPC developments, but back when I was still in the game icc was the most commonly used compiler.
mode_13h - Thursday, November 11, 2021 - link
> are they not compiling the code for the M1 series chips with a vendor supplied compiler?It's just a slightly newer version of LLVM than what you'd get on Linux.
> almost all benchmarks in SPECrate 2017 Floating Point are scientific codes,
3 are rendering, animation, and image processing. Some of the others could fall more in the category of engineering than scientific, but whatever.
> half of which are in Fortran.
Only 3 are pure fortran. Another 4 are some mixture, but we don't know the relative amounts. They could literally link in BLAS or some FFT code for some trivial setup computation, and that would count as including fortran.
https://www.spec.org/cpu2017/Docs/index.html#intra...
BTW, you conveniently ignored how only one of the SPECrate 2017 int tests is fortran.
mode_13h - Thursday, November 11, 2021 - link
Oops, I accidentally counted one test that's only SPECspeed.So, in SPECrate 2017 fp:
3 are fortran
3 are fortran & C/C++
7 are only C/C++
ricebunny - Thursday, November 11, 2021 - link
Yes, I made the same mistake when counting.Without knowing what the Fortran code in the mixed code represents I would not discard it as irrelevant: those tests could very well spend a majority of their time executing Fortran.
As for the int tests, the advantage of the Intel compiler was even more pronounced: almost 50% over Clang. IMO this is too significant to ignore.
If I ran these tests, I would provide results from multiple compilers. I would also consult with the CPU vendors regarding the recommended compiler settings. Anandtech refuses to compile code with AVX512 support for non Alder Lake Intel chips, whereas Intel’s runs of SPECrate2017 enable that switch?
xray9 - Sunday, November 14, 2021 - link
> At Intel’s Innovation event last week, we learned that the operating system> will de-emphasise any workload that is not in user focus.
I see performance critical for audio applications which need near-real time performance.
It's already a pain to find good working drivers that do not allocate CPU core for too long, not to block processes with near-realtime demands.
And for performance tuning we use already the Windows option to priotize for background processes, which gives the process scheduler a higher and fix time quantum, to be able to work more efficient on processes and to lower the number of context switches.
And now we get this hybrid design where everything becomes out of control and you can only hope and pray, that the process scheduling will not be too bad. I am not amused about that and very skeptical, that this will work out well.